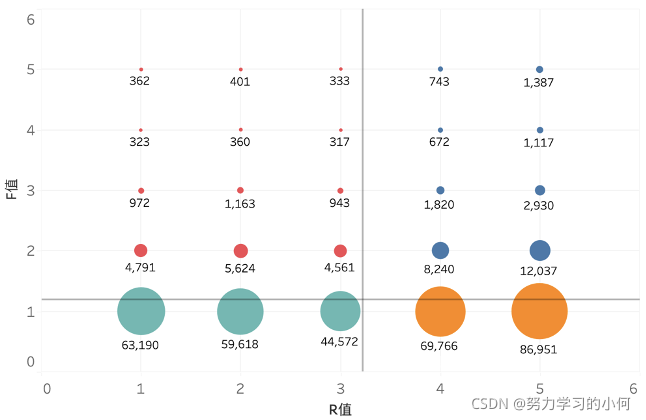
京东两个商品的中差评爬下来,因为评价太多了总共1万评价爬虫软件最多爬到前1000条,所以全是好评,但是想要分析的是中差评数据
商品链接
https://item.jd.com/100013315046.html
https://item.jd.com/100011977026.html#none
一、visual studio安装python开发插件,按照网上的爬虫教程:https://www.cnblogs.com/onemorepoint/p/7203465.html?utm_source=itdadao&utm_medium=referral
一点一点的编写代码

二、导入的库全都带着下划线,开始一个个安装

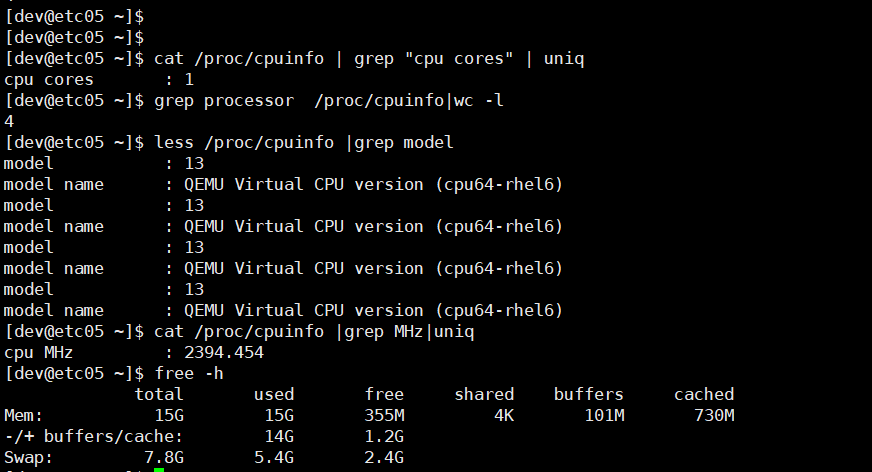
我使用的是python2.7版本,安装时候都是用的pip install --user 库名 scipy matplotlib,竟然全部适用,解决了代码中所有的绿色警告线
安装numpy库

安装jieba库

然后重启vs
三、编译时候有报错visual studio SyntaxError: Non-ASCII character,查了是编码错误,于是将.py文件以NotePad++打开并设置编码为
编码-》使用UTF-8-BOM编码,重新加载文件,就可以正确编译了
四、正确编译后发现printf中文解析错误


于是我改成了这样,我在逃避问题


五、报错Backend TkAgg is interactive backend. Turning interactive mode on.解决办法:https://www.icode9.com/content-4-32530.html
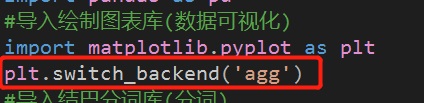
做了几个小时只得到了下面这样,没有处理换行没有做表

过程代码
#导入requests库(请求和页面抓取)
import requests
#导入time库(设置抓取Sleep时间)
import time
#导入random库(生成乱序随机数)
import random
#导入正则库(从页面代码中提取信息)
import re
#导入数值计算库(常规计算)
import numpy as np
#导入科学计算库(拼表及各种分析汇总)
import pandas as pd
#导入绘制图表库(数据可视化)
import matplotlib.pyplot as plt
#导入结巴分词库(分词)
import jieba as jb
#导入结巴分词(关键词提取)
import jieba.analyse#设置请求中头文件的信息
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'Accept':'*/*',
'Connection':'close',
'Referer':'https://item.jd.com/'
}#设置Cookie的内容
cookie={'__jda':'122270672.16174285433021660352364.1617428543.1617428543.1617431374.2',
'__jdb':'122270672.3.16174285433021660352364|2.1617431374',
'__jdc':'122270672',
'__jdu':'16174285433021660352364',
'__jdv':'122270672|direct|-|none|-|1617428543303',
'areaId':'2',
'ipLoc-djd':'2-2830-51803-0',
'mx':'0_X',
'rkv':'V0800',
'user-key':'216123d5-4ed3-47b0-9289-12345',
'xtest':'4657.553.d9798cdf31c02d86b8b81cc119d94836.b7a782741f667201b54880c925faec4b'}#设置URL的第一部分
url1='https://club.jd.com/comment/productPageComments.action?&productId=100013315046&score=0&sortType=5&page=pageSize=10&'
#设置URL的第二部分
url2='&pageSize=10&isShadowSku=0&fold=1&callback=fetchJSON_comment98'
#乱序输出0-80的唯一随机数
ran_num=random.sample(range(100), 100)#拼接URL并乱序循环抓取页面
for i in ran_num:a = ran_num[0]if i == a:i=str(i)url=(url1+i+url2)r=requests.get(url=url,headers=headers,cookies=cookie)html=r.contentelse:i=str(i)url=(url1+i+url2)r=requests.get(url=url,headers=headers,cookies=cookie)html2=r.contenthtml = html + html2time.sleep(5)print("当前抓取页面:",url,"状态:",r)- Cookie
- 理解:存储在浏览器的文本文件,可以设置和读取。用户在其他网页买东西后,跳转到支付页面时Http会附着已购买商品信息的cookie,于是支付页面就知道用户之前挑选了什么。同一域名下的每个请求都会携带cookie
- 使用场景:记住密码下次登录,购物车,记录浏览数据来广告推荐
- 原理:浏览器第一次向服务器发送请求,服务器响应后会在响应头中添加Set-Cookie选项。浏览器第二次向服务器发送请求时会将Cookie从Cookie请求头部发送给服务器,服务器会判断用户身份。另外,Cookie的过期时间、域、路径、有效期、适用站点都可以根据需要来定。
- 缺陷:
- 不够大:Cookie大小限制为4kb,否则被裁切,部分浏览器对同一站点的Cookie个数也有限制。各浏览器的Cookie每一个name=value,value的大小是4kb,并不是每个域名下的所有cookie一共4k,是一个name的大小。
- 过多cookie会带来巨大的性能浪费:同一域名下的所有请求都会携带cookie,带着cookie跑来跑去,带来的开销无法想象
- 安全性:HTTP请求中Cookie是明文传递的,除非用HTTPS
- cookie与安全:
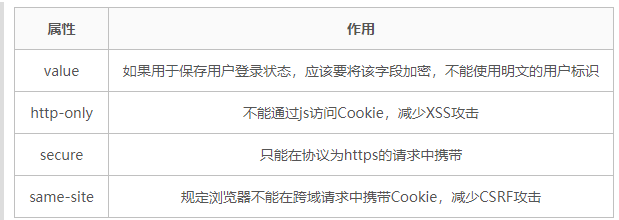
- LocalStorage
- 理解:网页保存在本地的缓存数据,不与服务端通信,接口封装较好,大小在5M左右
- 使用场景:可作为浏览器本地缓存方案,用来提升网页首屏渲染速度
- sessionStorage
- 理解:保存浏览器中的一次会话数据,浏览器关闭数据就被清空。两个浏览器窗口的sessionStorage数据不共享,大小5M左右,是会话级别的浏览器存储,不与服务端通信,接口封装较好
- 使用场景:有效对表单信息进行维护,刷新时,表单信息不丢失
- IndexedDB
- 理解:非关系型数据库,没有存储上限,一般小于250M,可以储存字符串和二进制数据
- 特点:
- 键值对存储
- 异步
- 支持事务:一步失败,整个事务被取消
- 同源限制:只能访问自身域名下的数据,无法跨域
- 储存空间大
- 支持二进制储存
- cookie,localStorage,sessionStorage区别
- 共同点:
- 都保存在浏览器端,都遵循同源策略
- 只能存储字符串
- 不同点:
- 生命周期:
- localStorage是持久化的本地存储,永不过期
- sessionStorage是临时性的本地存储,会话结束内容随之释放
- 作用域:
- localStorage只要在相同协议相同主机名,相同端口,就能读写同一份localStorage数据
- sessionStorage更苛刻,除了上述条件,还要在同一窗口下
- 生命周期:
- 共同点:
- 总结:
- cookie本职工作并非本地存储而是维持状态
- Web Storage 是 HTML5 专门为浏览器存储而提供的数据存储机制,不与服务端发生通信
- IndexedDB 用于客户端存储大量结构化数据