首先在http://www.ip138.com/上注册一个帐号(过程省略)
点击IP查询

token就是key了,还有其它的调用方法,这里只讲token这种调用
注册后好像免费只能查1000次(有需要可以自己买,貌似不贵)
有了这个key就可以调用接口了,代码如下
# coding: utf-8
__author__ = 'www.py3study.com'
import urllib.request
class ip_source_find(object):def __init__(self):self.sfile = r'C:\Users\9you\Desktop\ang_login_ip.log' #源日志ipself.dfile = r'C:\Users\9you\Desktop\alive.txt' #处理后的新文件self.aliveList = [] #临时的文件self.run()def run(self):with open(self.sfile, 'r') as fp:lines = fp.readlines() # readlines 读取所有行for i in lines:ip = i.strip('\n')key = '77cc292f2f80124a1bfcb29802eb4ac' #自己的tokenURL = 'http://api.ip138.com/query/?ip=' + str(ip) + '&datatype=jsonp&callback=find&token=' + keyresponse = urllib.request.urlopen(URL)html = response.read().decode("utf-8")print(html)new_ip = html.split(':')[2].split(',')[0]address = html.split(':')[-1].split('}')[0]new_content = new_ip + '\t' + address + '\n'self.aliveList.append(new_content)with open(self.dfile, 'w') as fp:for i in range(len(self.aliveList)):fp.write(self.aliveList[i])if __name__ == '__main__':st = ip_source_find()
如果需要使用上面的脚本
需要注意的地方
源ip文件格式,只能是ip,不能有其它的任何东西
Linux下去过滤web的日志
cat access_201711160430.log | awk ‘{print $1}’ | sort| uniq -u >> 2.txt
内容如下,只能是单纯的ip
注意脚本最上面源ip路径,和生成后新的ip路径,
windows下路径需要用反斜杠\
linux下路径用/
还有就是你自己的key,也就是注册帐号里面的token
最后还需要安装一个python3以上版本,我用的是py3的语法!
改完后,就可以运行脚本了,运行截图
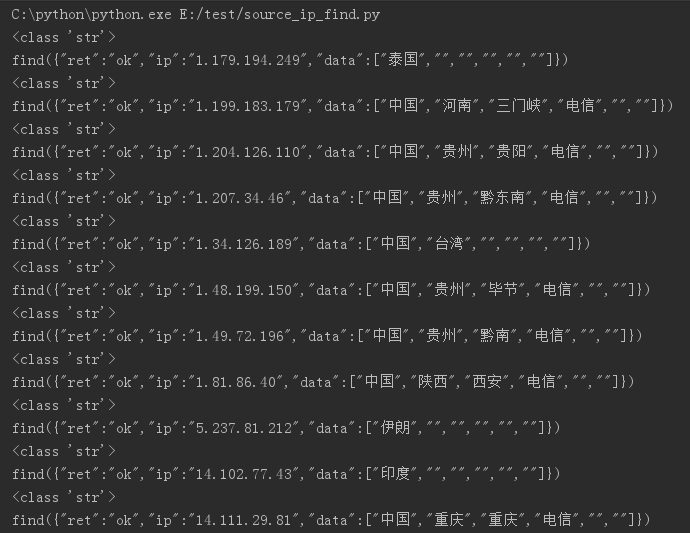
最后生成文件截图