Multi-Robot Path Planning Method Using Reinforcement Learning
期刊:applied science MDPI
总结:使用VGG进行特征提取,再使用DQN进行决策。论文质量较低,缺乏很多重要内容,如:环境搭建、数据集介绍、action和state的相关描述,还有很多typo;而且论文中并未体现出多机器人的思想。
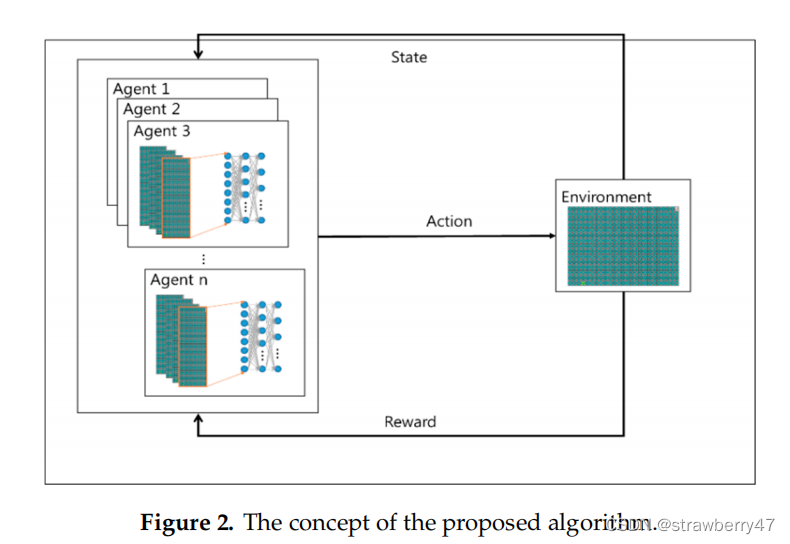
论文模型图非常简单,画了跟没画似的。。。和常见的强化学习交互图一样。
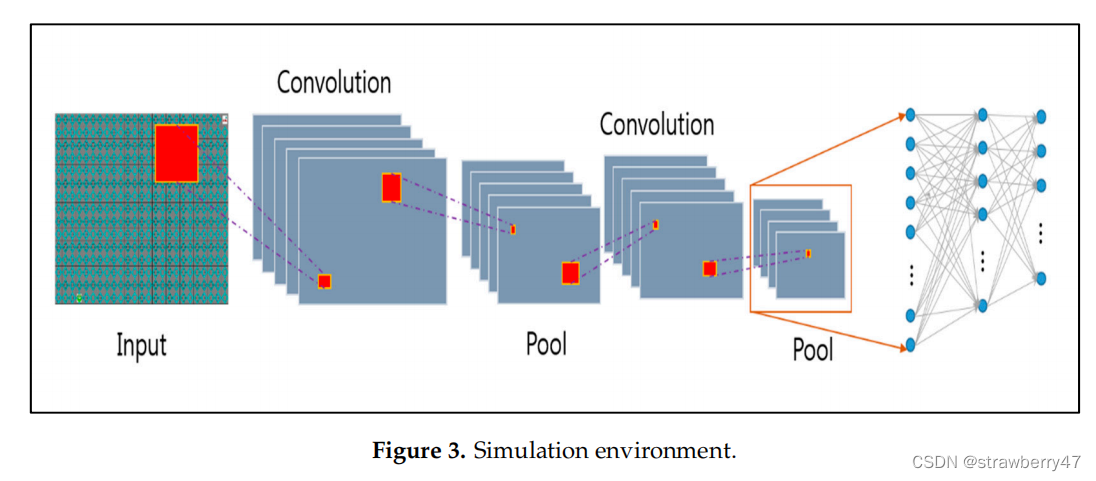
用到了CNN来处理像素信息(应该后续会作为state),但文中并未说明图像信息来源:
reward设置:离目标近,reward +0.2;碰撞,reward -20;到达目标点,reward +100;

算法流程:并未说清楚s,a是怎么来的;猜测action是停在原地以及上下左右移动五种情形

强化学习算法:DQN
模拟环境:we built a simulator using C++ and Python in a Linux environment;障碍物的数量和位置是随机的;最终目标始终是右上角
Multi-agent navigation based on deep reinforcement learning and traditional pathfinding algorithm
arxiv 2020
总结:将传统的A star算法选择路径作为强化学习算法中的action(相当于用A*进行保底)
action:

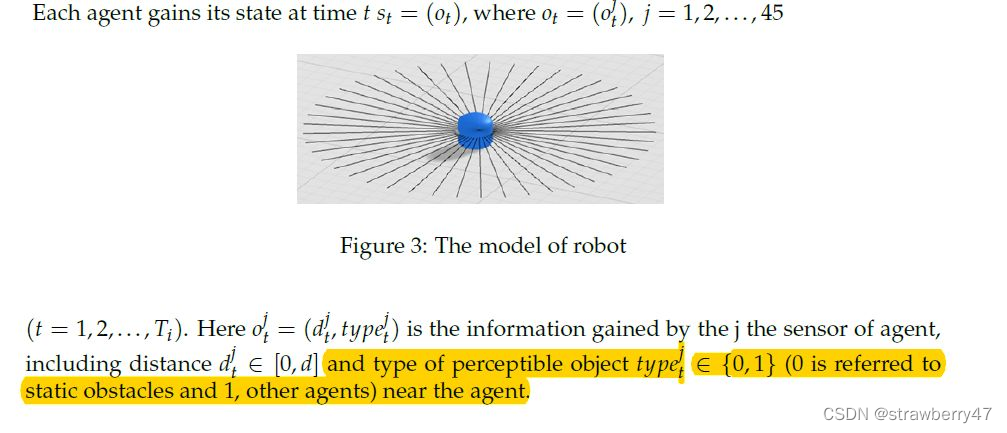
state:作者在unity3D上的简要环境,一个机器人带有45方向个传感器,45个方向感知的东西, 传感器的感知范围为d长度。
reward: r n a v i g a t i o n + r s c e n a r i o + r p e n a l t y r_{navigation}+r_{scenario}+r_{penalty} rnavigation+rscenario+rpenalty
- r n a v i g a t i o n r_{navigation} rnavigation: 如果action是 a 0 a_0 a0,即采用传统方法,则为正奖励,否则为0
- r s c e n a r i o r_{scenario} rscenario:若发生碰撞,则为负奖励;若到达终点,则为正奖励
- r p e n a l t y r_{penalty} rpenalty:每走一步,都有一个负奖励
RL算法:PPO
模拟环境:Unity3D + Tensorflow
PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning(经典)
发表于2019 Robotics and Automation Letters
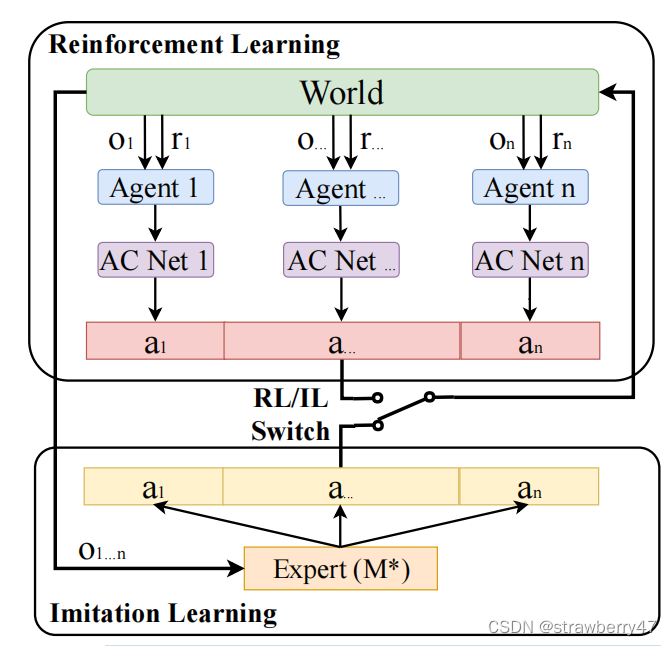
总结:结合了强化学习和模仿学习,能用于多个智能体(1024);分布式算法
设计了expert centralized MAPF planner,各个agent的决策都是有益于全体的;agent不需要显式通信,但可以在路径规划中表现出隐式协同。
单agent的决策靠的是RL + 模仿集中专家
(有点类似于:集中式训练,分布式执行)
state
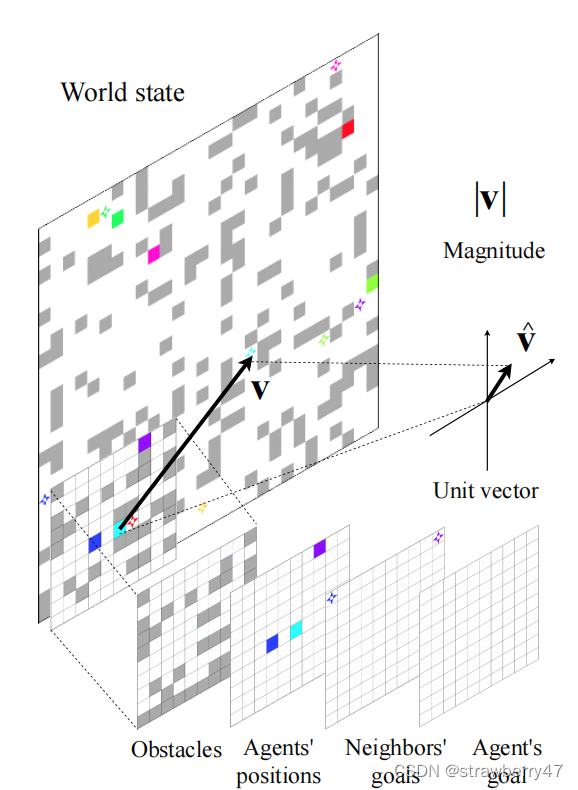
observation space是有限的,不知道全局地图;每个agent视野范围不一定有goal,但是知道goal方向。
state:由四个channel组成(二值矩阵),障碍物、其他agent位置、agent的目标、其他可见的agent目标
action:
action:上下左右或者不动
存在无效action,规定只在有效action中采取行动(比给无效action一个负反馈,效果更好)。
鼓励探索,禁止agent返回上一个位置,可以静止不动
reward:
reward:发生碰撞就扣分,达到目的地就加分
静止不动,惩罚更多

Netword:
使用A3C来训练,policy network由CNN, LSTM, pooling组成:
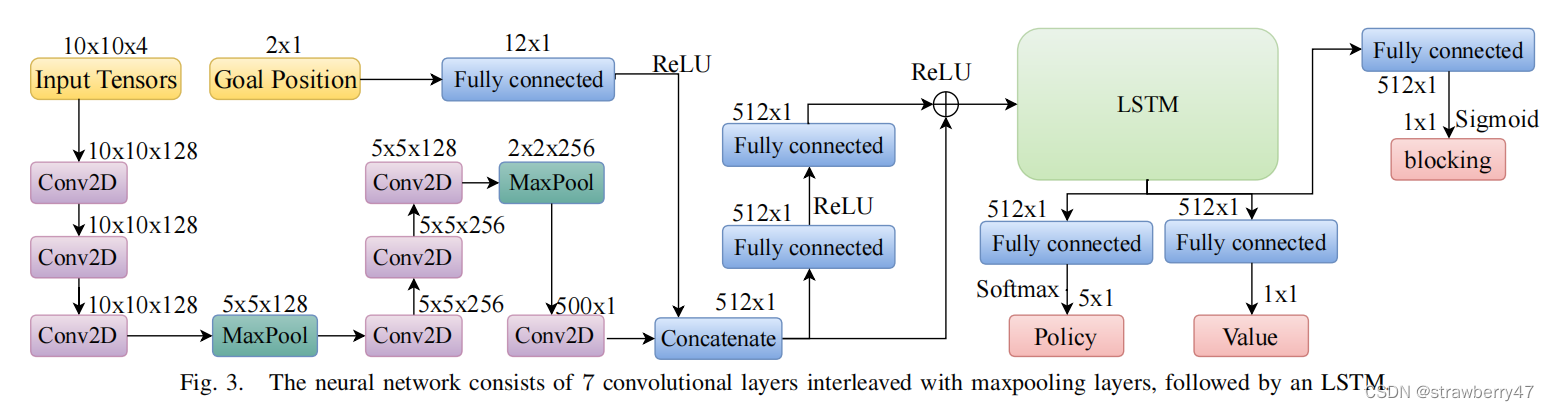
输入是四个channel和goal position
输出有三部分,policy和value相当于actor和critic(他们共享了参数),还多了一个blocking,代表是否阻碍了别的agent。
使用A*算法估计路程,如果说去掉所有的agent后的路程变少了十步,那就视为blocking
Learning
分布式策略,但是得互相合作。常用的协同策略:① shared critics,当FOV并非有限的时候是有用的 ② joint rewards
本文的策略:
- blocking penalty:如果agent在goal待着不动,阻碍了别的agent到达,扣分。虽然别的agent可能有另外的路线,但当前路径可能是最短的
- combining RL and IL :RL允许探索,IL能快速找到高质量区域;在线生成专家演示?(利用ODrM* optimal multirobot path planning in low dimensional search spaces生成高质量路径)
- environment sampling
知乎解析
模拟环境:YouTube视频 , github代码 (python搭的环境)
总结对比:
| paper | state | action | reward | 补充 |
|---|---|---|---|---|
| Multi-Robot Path Planning Method Using Reinforcement Learning | CNN分析环境的结果 | 未说明,猜测是上下左右和停在原地 | 离目标越近越好,碰撞会赋负值 | 质量低 |
| Multi-agent navigation based on deep reinforcement learning and traditional pathfinding algorithm | 45个方向的传感器结果,障碍物or合作智能体 | 六种action,A*, stay, backward, forward,left,right | r n a v i g a t i o n + r s c e n a r i o + r p e n a l t y r_{navigation}+r_{scenario}+r_{penalty} rnavigation+rscenario+rpenalty | A*作为保底 |
| PRIMAL: Pathfinding via Reinforcement and Imitation Multi-Agent Learning | 不同视野的四通道(障碍位置、当前agent位置、邻居位置、agent目标) | 东南西北移动、不移动 | 靠近目标就加分,发生碰撞减分 | 推出了PRIMAL2 |