kafka 串讲:架构模型、角色功能梳理
kafka 的 what why how,先有一个粗略宏观的理解
rabbitmq、各种 mq 的技术选型、横向对比
首先,kafka 是一个消息中间件。我们从一个本质的点聊起,我们有一个系统 service,如果这两个服务之间直接调用的话,它们之间会相互约束,耦合性比较强,而且未来的拓展不好,一方有调整的时候,另一方会受到影响。

这时候我们加入一个消息系统,一方发送消息,另一方去取,就起到了我们所谓的消峰填谷以及解耦的效果。
现在我们聊的是消息的中间件,其实中间件包括很多,包括有存储的,有缓存的,他们的作用都有一个相通性,就是他们最终都会与分布式挂钩。
那说道中间件,会有几个词汇的需求:可靠的、可扩展的、高性能的等等,关于分布式对中间件大概有这么几个要求。在 redis 中,我们会有 AKF 微服务划分原则,那 kafka 和 AKF 划分有什么联系呢,等待会儿我讲完看一下效果吧,如果讲的不明白的话,后面排一个分布式系统划分分享。
我们先举一个简单的例子,然后去挑这个例子的毛病,把毛病挑出来之后,我们就知道为什么 kafka 会被设计成现在这个样子了。
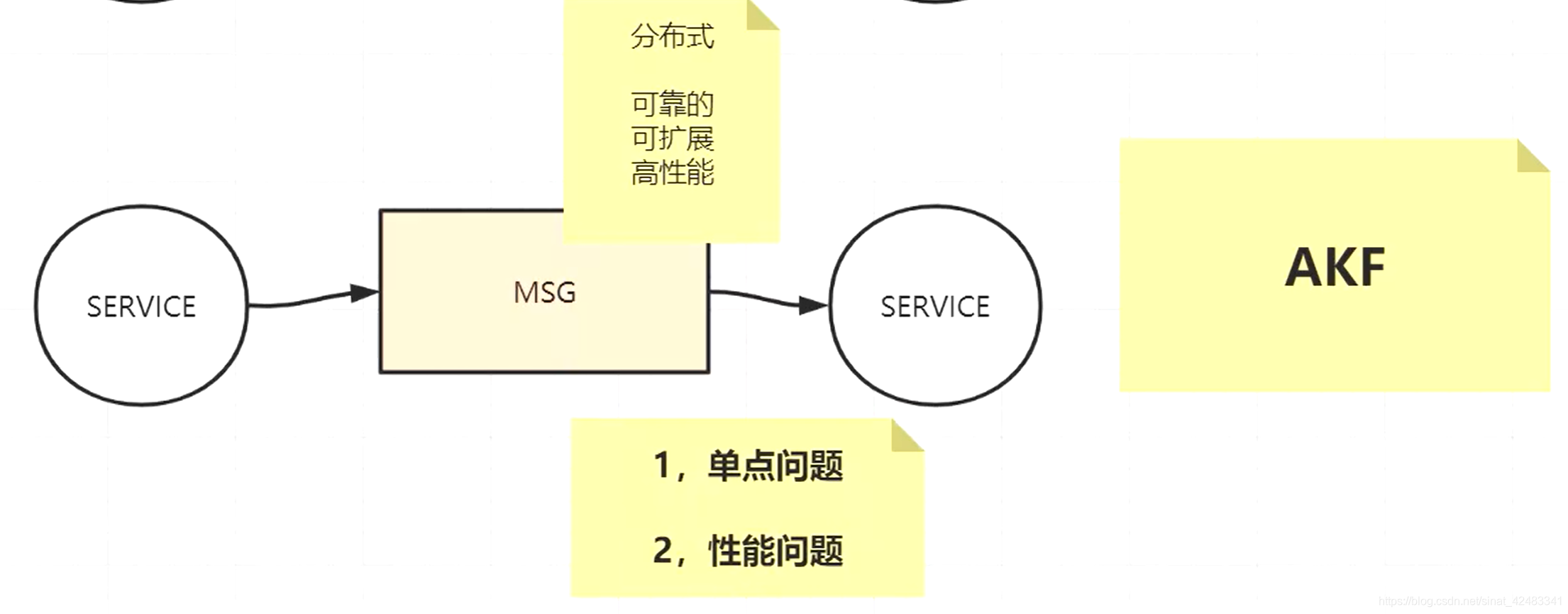
现在我们假设,整家公司只有一个系统。所有消息被调用的时候,都被打到同一个单机队列中,这个时候确实能够达到我们常说的削峰填谷的作用,但是随着我们业务的增大,并发量的随之增大,这个单机的队列它会有单点问题,会有性能问题。这也是我们在使用很多技术的时候通常会遇到的两个问题。这是两个独立的问题,这两个问题我们可以独立的解决,解决方案也可以独立的应用,但很多时候我们会把他们整合应用。所以继续往下讲你们应该能找到这种感觉。
性能问题
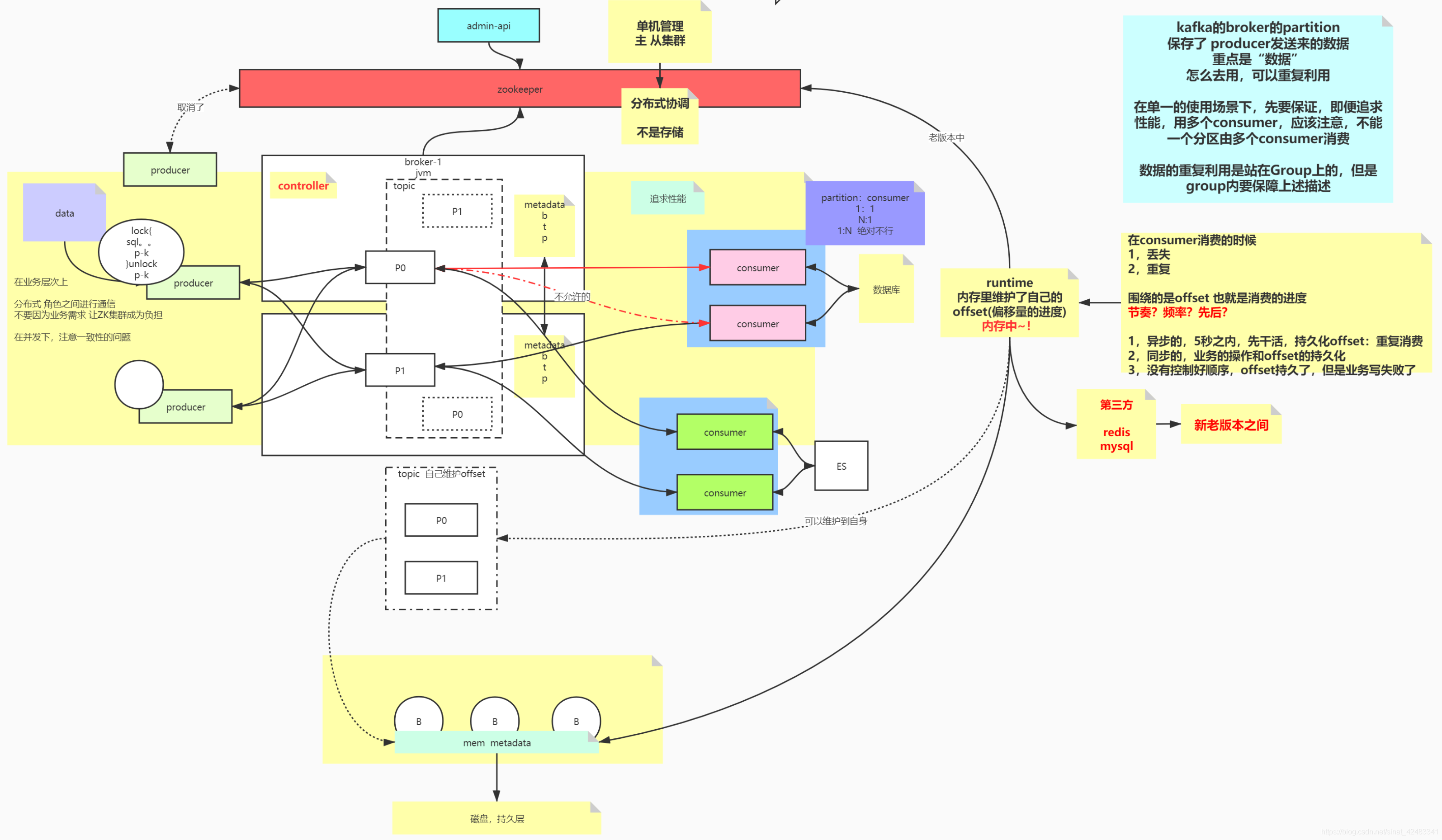
我们要先解决性能问题,因为 kafka 的关键词里面,先是 topic,然后是 partition,再是副本。
性能问题是怎么解决的?以 AKF 的角度来说,它有三个维度:
x 轴解决的是单点问题,是高可用的,y 轴解决的是业务划分的,z 轴解决的是分片、分治的。先把这个图放在这里,然后我们再细讲。
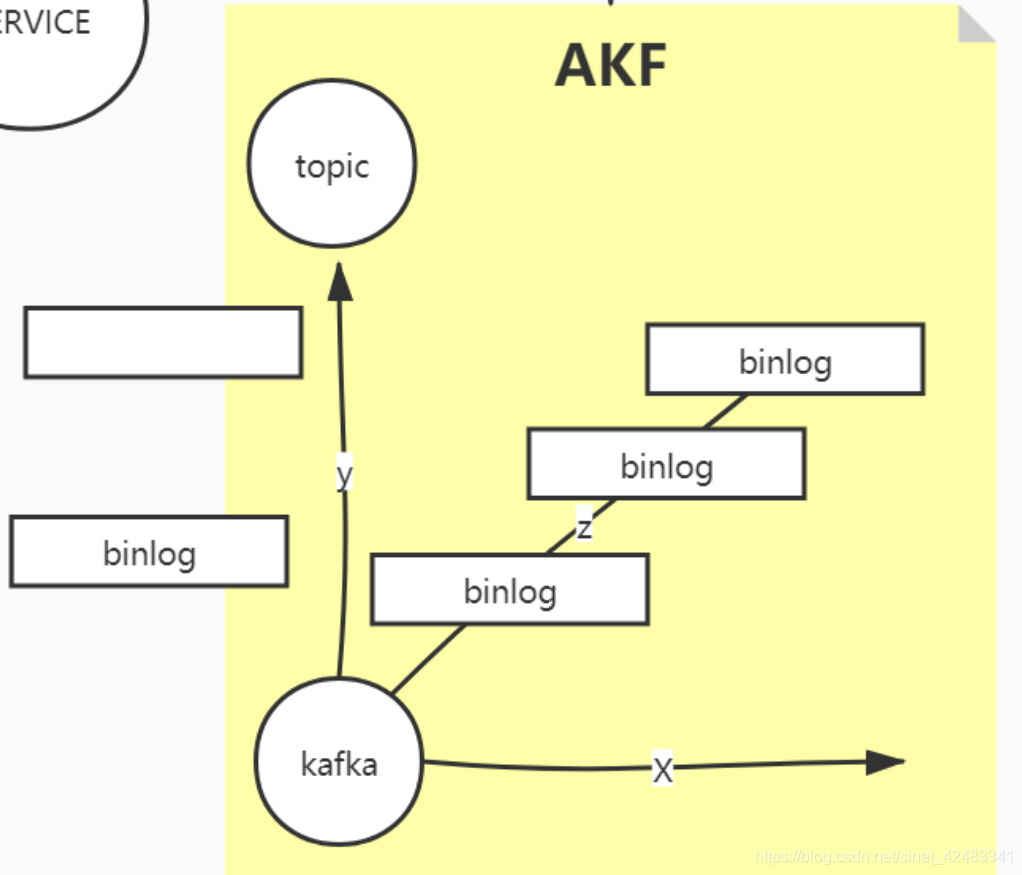
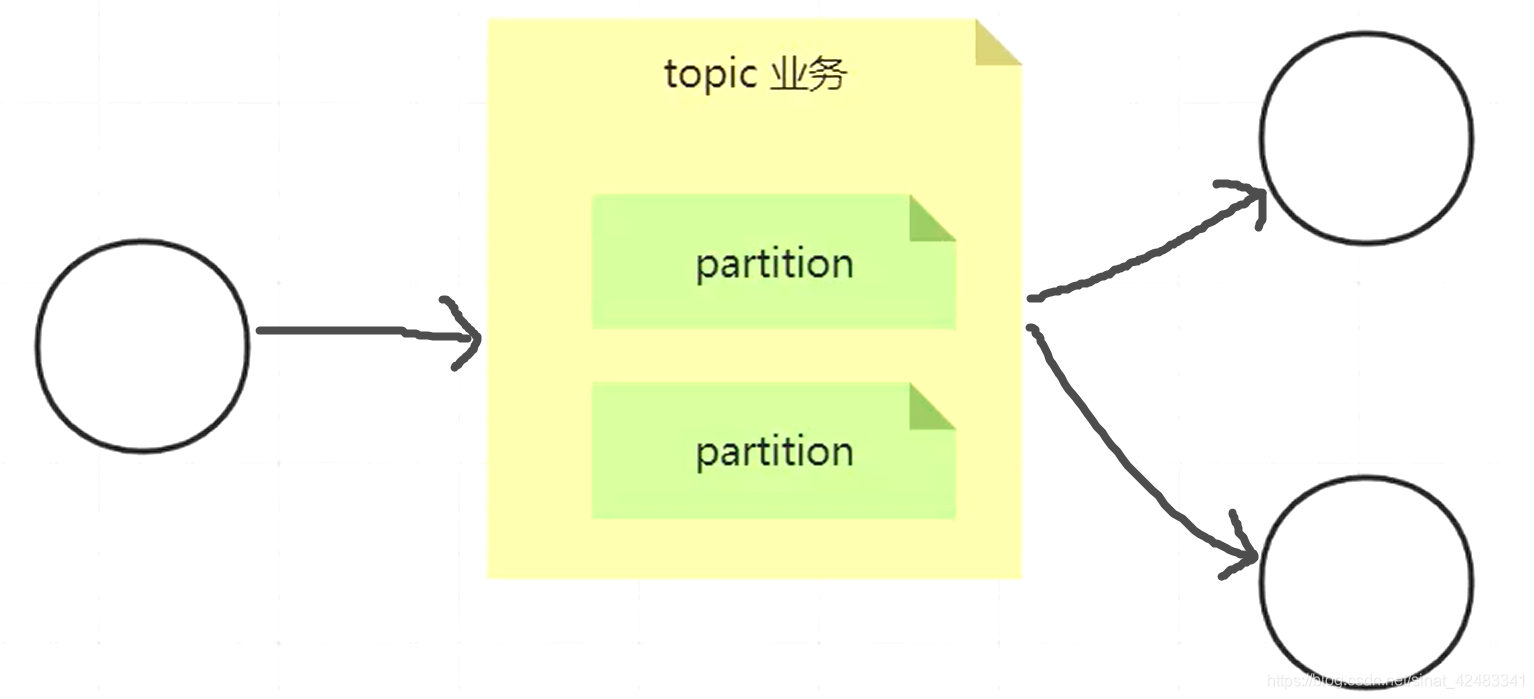
那我们如何把这三个轴对应到 kafka 的特性上,首先 y 轴将消息按业务划分,比如在一个电商系统,可以把订单拆出一个队列、用户行为拆成一个队列、广告推荐拆成一个队列。这样划分之后,不同业务的生产和消费都不会相互影响,业务之间的隔离性会比较好。而且按照业务划分之后,不同的业务数据会被部署在整个 kafka 集群中的不同的节点上,每个节点只关注自己的一套东西的话,资源的利用率会高。因此如果将我们上面说道的单机版的这个消息队列从逻辑上进行拆分的话,第一个拆出来的就是 topic,我们说的 y 轴其实就是 topic。你可以把 topic 就理解成是业务。
但是如果这么划分的话,假设说我的用户行为日志存在某个 topic 中,如果我的日志量太大了,如果全部存放在一个节点(中的一个进程)上的话,工作起来 IO 上会受限,而且单看自己它会有一个性能瓶颈。那怎么解决这个性能瓶颈,当我们已经进行过业务拆分之后,怎么再进行更细粒度的拆分,这时候就是我们的 partition。在一个 topic 下,会有多个 partition。
我们这个讲法可能会比较墨迹,是因为比较注重思路的推导这个过程,其实很多地方都有 AKF 这个思想,不仅是 kafka,还有 redis 也会涉及到 AKF,那在我们出去面试的时候,如果抓住这个内容的话,分布式和微服务都可以在这里面去聊。
那另外一个就是 partition,分区的概念。这个分区其实作用的就是我们的 z 轴,因为在业务使用的时候,假如说我们希望用 kafka 去存 用户行为日志,我们会期望把这些日志由一个变成多个,由多台机器,更大的能力去承载它。一般我们聊到 z 轴的时候,z 轴其实是对 y 轴一个细分,那细分的时候,可以使用的手段可以是 range,hash,或者是做一个映射,拆解的方案会有很多。
还是拿刚才推荐系统中收集用户行为的例子来说,我要把所有的用户行为日志打散到多台里面去,这个多台应该怎么打才合适?也就是说,当使用的数据从一个线性的队列散落到多个地方的时候,如何去保证前面的生产最后消费的数据的一致性?就是说,在以前没有分区的概念的时候,数据长什么样,我只需要按顺序一个一个推进来,这边取到的就是原有的样子。一旦一变多,会带来一致性的问题,那我们的生产方和消费方,如何组建这个先后关系,保证它仍然是有序的?
在 AKF z 轴划分的时候,如果你学过大数据,也可以引入分治这个概念了,大数据必然会有分治,也就是 map 阶段,map by key,也会有聚集 reduce,就是相同的数据要打到一起去,然后收集起来进行后续的处理,其实 kafka 中依然是这个原理。在生产用户行为日志的时候,有 展现,点击,收藏 三种不同的用户行为,只要他们各自有自己的顺序。也就是在分而治之的时候,将无关的打开,分散出去,将有关的放在一起,一定要保证顺序。

所以这时候,z 轴应该如何实现?要规划好整个数据路由,将无关的数据放在不同的 partition 中,这样我们就达到了一个后续无关数据的并行度。
无关的数据是可以并行计算的,如果有关的话,我们会需要在他们之间加上一个分布式锁,或者通过 log id 等方式去保证他们的顺序性,这样会变得很慢,所谓的并发最终还会退化为串行。所以我们希望将并行最大化,将无关的数据分散到不同的分区里,以追求并发、并行处理,有关联的数据,一定要按照原有顺序发送到同一个分区里。
topic 是逻辑概念,partition 是最后物理的对应,一个 topic 下面有 partition 1,2,3…
然后我们看到还有一个 x 轴,这个 x 轴什么意思,x 轴做的是可靠性的保证。现在通过 y 轴和 z 轴,将这些消息打散到不同的分区了,实现的是计算的并行,提升了性能,但是这个时候,如果某一个分区消失了,挂掉了,这时候你堆积的消息会丢失,这时候需要我们给它做副本。在做副本的时候,我们横向走下这个过程。
无论 redis 也好,kafka 也好, 你像纯内存的 redis,它必须有一个持久化,他会认为磁盘是自己可靠性的来源,如果不在单机的维度,而是看集群的维度的话,单物理节点可能也会丢失,会挂,这时候为了解决节点的问题,我们还需要网络的维度提供可靠性,那 redis 就会有单机的持久化、网络的持久化,基于网络的主从复制集群。那他的主从复制集群就来自于它的 x 轴。其实 kafka 也一样,kafka 分区的数据会持久化到磁盘当中去,而且利用顺序读写这种高性能的磁盘 IO,x轴一般是出主机的、异地的备份,因为如果将全量备份放在同一个节点上意义不大。
x 轴的拆分会比较容易出现数据一致性、数据的同步问题,会有一系列分布式集群下的解决方案,比如 mysql 会有读写分离的策略,为了解决一致性和复杂性上的痛点,kafka 做了一个决策就是只允许在主片上增删改,从片只允许读。
**由单机到分布式,或者说由传统到中间件,基本都是按照这个思路来设计的。**我们用到的各种分布式中间件的实现,和 AKF 这一侧是有必然的这么一个参照和关联的关系的。
这些都是方法论,来推导出 kafka 中有 topic,partition,有序性的这些概念,然后我们再把有序性做一个延伸:下面我们来讲 offset
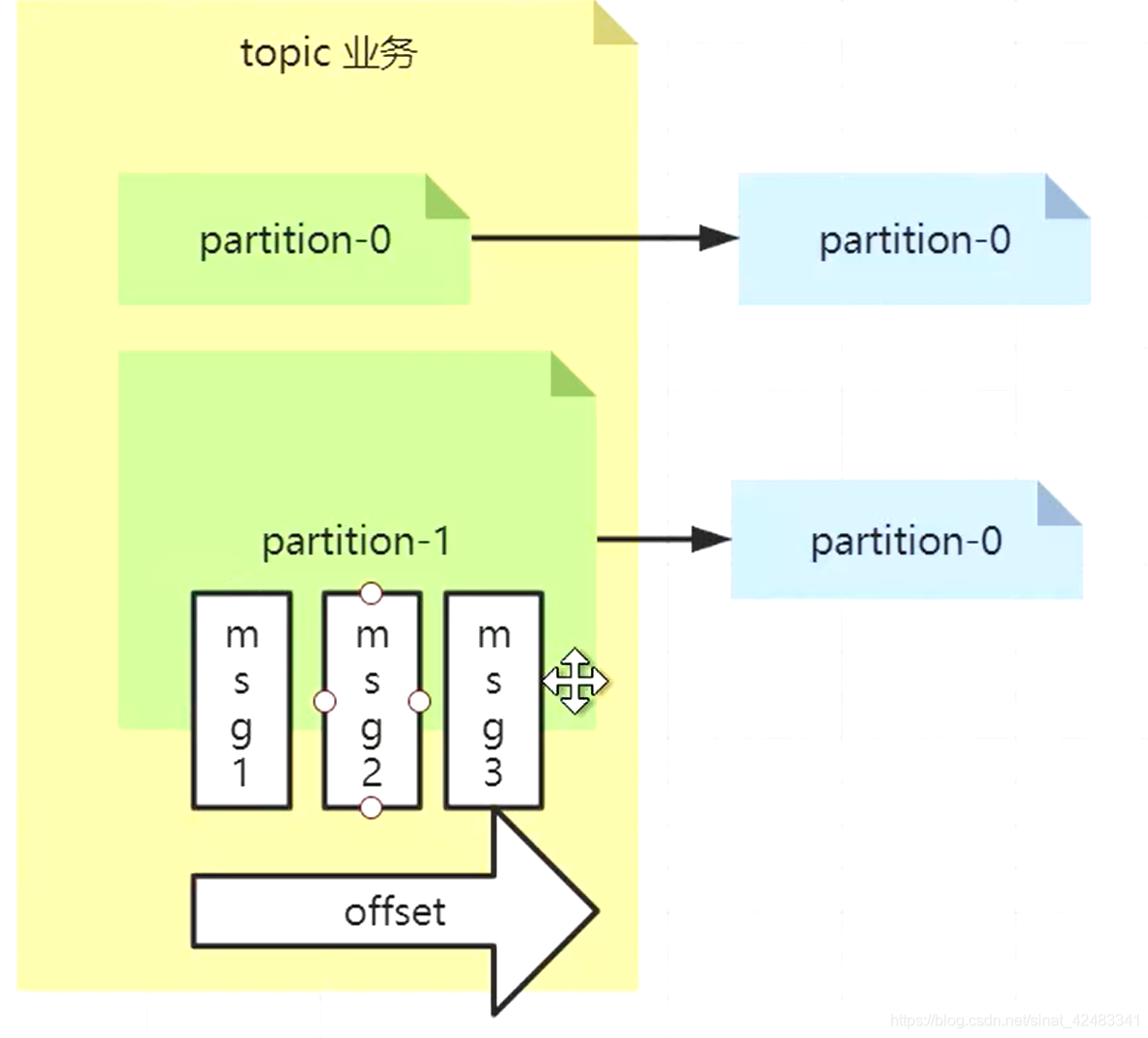
我们知道,分区内部是有序的(纯队列),分区外部是无序的,那这个顺序是怎么得到的?我们用 partition1 做一个简单的描述。假设我们的上游发来三个消息,msg 1,2,3,这三个消息会按照接收的顺序存在 kafka 队列中。当消费者来消费的时候,每个消费者会维护一个自己消费到的位置,也就是 offset。
The offset is a simple integer number that is used by Kafka to maintain the current position of a consumer. That’s it. The current offset is a pointer to the last record that Kafka has already sent to a consumer in the most recent poll. So, the consumer doesn’t get the same record twice because of the current offset.
Offsets in Kafka are stored as messages in a separate topic named ‘__consumer_offsets’ . Each consumer commits a message into the topic at periodic intervals.
上面的例子中,只有一个 topic 和这个 topic 下的两个 partition,实际上企业中会有很多个 topic,每个业务下都会有很多 topic,每个 topic 下会有几百个 partition,如何去管理这些分布式的东西的一致性?在经验中,主从是管理成本最低的,它的协调成本会比主主要低,这样会引发一系列分布式协调的问题,包括选主,包括如何保证数据的一致性,常用的解决方案有 zookeeper,或者 etcd。那我们的 kafka 会依赖 zookeeper,主要是依赖它的分布式协调,不过要注意千万不要把 zookeeper 当做是分布式存储来使用。
kafka 对 zookeeper 的依赖
kafka 的 broker 依赖于 zookeeper
- 使用 zk 存储 broker 的元数据,将 broker 当做是一个进程。
- 使用到 zk 的选举机制