包装类型和基本类型
-
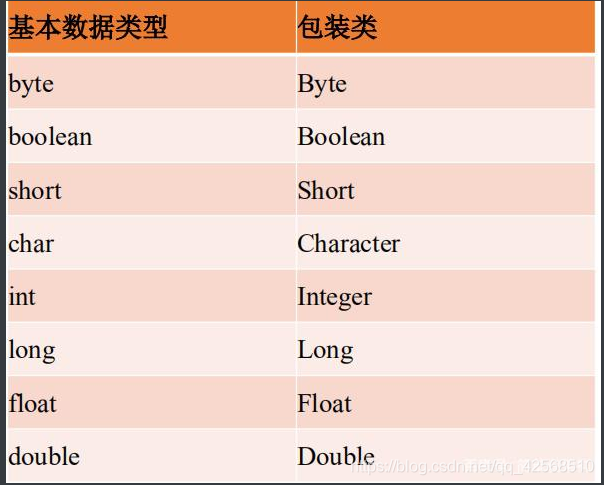
Java中有八种基本数据类型,分别对应着八大包装类型,因为包装类型的实例都存在于堆中,所以包装类型也称为引用类型。
-
基本类型属于原始数据类型,变量中存储的就是原始值。包装类型属于引用数据类型,变量中存储的是存储原始值的地址的引用。
- 基本类型中,局部变量存在方法虚拟机栈的局部变量表中,而类中声明的的变量存在堆里。
- 包装类型中,无论局部变量还是类中声明的变量均存在堆中,而方法内的局部包装类型变量,其也存在局部变量表中,不过期值为该变量在堆中的地址。
-
手动装箱 / 手动拆箱
Integer b = valueOf(1);int a = b.intValue();
- 自动装箱 / 自动拆箱
Integer b = 1;int a = b;
Java SE5 为了减少开发人员的工作,提供了自动装箱与自动拆箱的功能,3等价4。
5. == and equals:
- == 比较的是内存地址
- equals 比较的是值
- 代码实例
int a=0;int b=0;System.out.println(a==b);
按照==的分析,此处应该输出false,然而结果是true,原因在于:
当定义b时,JVM会先检查局部变量表中是否已经有了0这个值,如果没有,则创建,如果有(如之前已经执行过int a= 0),则不会再创建,而是直接将变量b指向变量a所在的局部变量表的地址,就好像执行的语句是int b = a。换句话说,a和b最终指向的内存空间,其实还是一致的
int a = 0;int b = 0;b = b + 1;System.out.printlt(a == 1)
首先jvm会先创建一个常量 0,然后把a的引用指向0,再把b的引用指向0,当执行b=b+1的时候,运算出结果为1,jvm先不创建1这个量,而是在局部变量表中去查找是否有这个值,有就返回,无就创建,此时b的值就被指向了1,所以输出结果自然是false,当我们看下面代码
int a = 0;int b = 0;int c=1;b = b + 1;System.out.println(b==c);
我们已经声明了1,并把c指向这个地址,然后运行b=b+1时,jvm查找有1这个值,就把这个值的局部变量表地址赋值给了b,所以这里判断b==c应该是true;
- 装箱拆箱详解
- 装箱:装箱是通过 valueOf()方法来实现自动装箱的,我们来看看源码:
public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);}
这里面有个IntegerChche即Integer类型的缓存,来看看内部类IntegerCache:
private static class IntegerCache {static final int low = -128;static final int high;static final Integer cache[];static {...high = h;cache = new Integer[(high - low) + 1];int j = low;for(int k = 0; k < cache.length; k++)cache[k] = new Integer(j++);// range [-128, 127] must be interned (JLS7 5.1.7)assert IntegerCache.high >= 127;}private IntegerCache() {}}
这里省略了部分内容,这个类存在的意义是将较为常用的数字存到缓存中,int类型的是 -128 - +127,我们可以看到有一个final类型、Integer类型的cache数组,然后在static块中分别对这个数组赋值,即把-128 - +127这256个数据存到cache数组里,且索引是0-255,注意,这里的cache数组是在类加载过程的初始化阶段确定的,因为在static块中,并且由于是常量,会存在元空间内 ,又由于cache这实际上是一个对象数组,所以常量池中有cache这一项引用,其指向了再堆中的数组,但是又因为是对象数组,其每一项都指向了堆中的具体的Integer对象.
然后再看valueOf,如果要装箱的值不在-128-+127之间,那么它会返回一个新的对象,这个对象是存在堆里,如果是方法内调用,那么对象的引用会存在方法的局部变量表内。
即:当我们开始运行程序的时候,-128-+127这256个数字就已经存在了堆中,用cache进行管理,如果新建一个Integer对象,其值是在此范围内,就会直接返回cache中的相对于的信息即堆中的信息,如果不在此范围内,就会新建立一个Integer对象,放在堆中,然后将其引用存在局部变量表里。
- 拆箱:拆箱是通过intValue来实现的
Integer a = 0;int b = a.intValue();
其中intValue:
public int intValue() {return value;}
从JVM来看,先创建了一个Integer类型的变量a,其引用指向堆,当我们实现拆箱的时候,JVM会先判断
在局部变量表中是否有这个值,如果有,直接放回在局部变量表中的引用,如果没有则新建再返回。
- 包装类型代码详解:
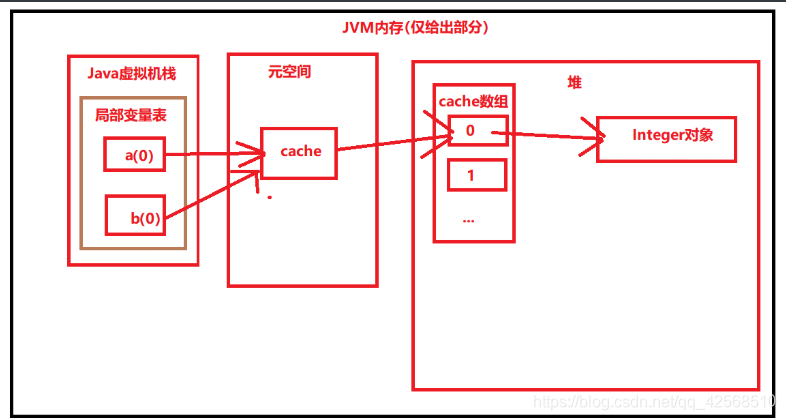
Integer a = 1;Integer b = 1;System.out.println(a==b);
由于 == 是比较地址,而Integer属于引用类型,分别建立了两个实例分别存在了堆中,所以直觉来看应该两个地址应该不同,但是结果是true,原因是cache的存在,再代码正式运行前,堆中就已经存有缓存,这里的1属于-128-+127之间,所以直接返回缓存中的值也就是说,在赋值a的时候,其实它指向了缓存中的1的引用,也就是指向了堆中,而赋值b的时候也是直接指向了缓存,所以他们两个地址是一致的。
给一个草图
Integer a = 128;Integer b = 128;System.out.println(a==b);
这里由于128不属于缓存范围,所以两个语句分别建立了两个不同的对象,所以他们的内存地址也是不一样的,所以返回false,同样也给出一个草图
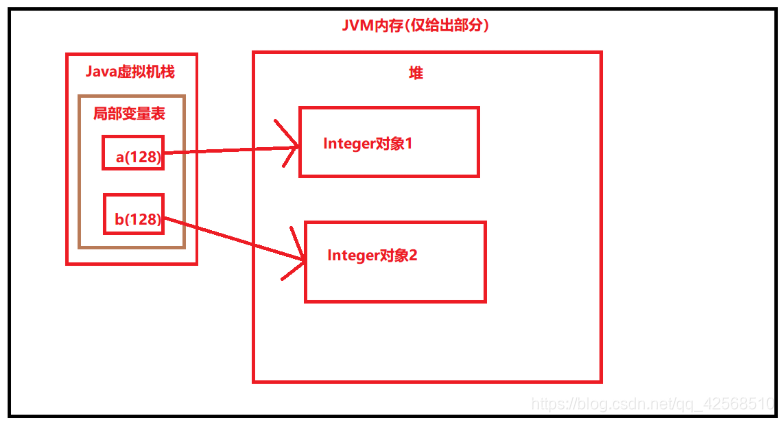
public class test2 {Integer b=0;public static void main(String[] args) {test2 test2 = new test2();Integer a = 0;System.out.println(test2.b==a);}}
我们来看这个代码,我们再类中定义了一个Integer对象b,赋值为0,在main方法中也定义了一个Integer对象,也赋值为0,比较这两个地址,会输出什么?答案是true,原因很简单:
在我们在类中定义b时,实际上这个b存于堆中,然后指向常量池中的cache,然后cache又指向在堆中的数组,而数组的每一项均指向了堆中的Integer对象,所以可以直接说是b直接指向了0这个Integer对象,在类中定义的a,其引用存在于局部变量表中,引用指向了Integer的cache,cache指向了堆,所以它们两个的实际地址引用是一致的,都是cache在堆中的缓存.
所以我们得出了这个结论:在一个程序运行期间,无论是方法内还是方法外,其所定义的Integer,且其值是在-128-+127之间,那么他们的引用是一致的。
int a = 1;Integer b = 1;System.out.println(a==b);
但是如果我们来比较包装类型和基本类型的地址的时候会输出什么?这里输出了true,为什么呢?
单看代码看不出来啥,我们来看看字节码:
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=3, locals=3, args_size=10: iconst_11: istore_12: iconst_13: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;6: astore_27: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;10: iload_111: aload_212: invokevirtual #4 // Method java/lang/Integer.intValue:()I15: if_icmpne 2218: iconst_119: goto 2322: iconst_023: invokevirtual #5 // Method java/io/PrintStream.println:(Z)V26: return}
这里是main方法的主要字节码,省略了部分,我们不做细讲,主要讲跟问题相关的,我们通过行号指示器来看,
首先第3行,invokestatic 表示调用了一个static方法,后面是注释,表示调用了Integer.valueOf,这里对应着代码里的定义包装类,因为定义包装类就必须进行装箱,而Java5后直接支持自动拆装箱,自动不代表不用,所以这里需要调用静态方法Integer.valueOF进行装箱,
看第7行,调用了输出流的PrintSteam方法,再来看第12行,看后面的注释,表示调用了Integer.intValue方法,这是拆箱的方法,但是我们代码中并没有拆箱,那么这段代码是怎么来的呢?
如果要使用拆箱,就必须有包装类,看代码,输出流里面只有一个包装类即b,那就说明了b调用了拆箱的方法,其主要过程是,把b的值取出,判断局部变量表中是否存在,如果存在,则返回局部变量表中的地址,如果不存在则创建再返回。
所以我们能很好的解释为什么上面的输出是true,因为,当我们使用==来比较基本类型和包装类型时,包装类型自动进行拆箱,并返回局部变量表中的引用,由于之前局部变量表中已经存在0这个值,并把a的引用执行它,当进行拆箱的时候,b的引用也指向它,如此一比较,他们的地址当然相等。
- equals 详解
Integer a=128;Integer b=128;System.out.println(a.equals(b));
为什么用equals能比较值呢?来看看equals源码:
public boolean equals(Object obj) {if (obj instanceof Integer) {return value == ((Integer)obj).intValue();}return false;}
非常简单粗暴,先判断是否属于Integer,如果是转换再进行拆箱直接判断值是否相等即可。
这个equals方法属于Object类,如果要分别实现比较不同的值就必须进行重写,所以上面的equals是Integer类重写的equals,其实现会根据不同的引用类型给予不同实现。例如 Character-char类型包装类,其equals是这样的:
public boolean equals(Object obj) {if (obj instanceof Character) {return value == ((Character)obj).charValue();}return false;}
和Integer的equals是不一样的。
几个问题:
- b=b+1;1存在哪?
当我们执行b=b+1时,b的值和1均存在于局部变量表中,不过b是以变量形式存在,即b的引用可以根据需要指向不同的值,而1是常量,直接存在局部变量表中,当我们执行加法操作时,JVM会先把b这个变量所代表的数(有可能是1、2、3等)压入操作数栈,然后再把1压入操作数栈,然后一个个出栈进行加法操作,再把结果入栈,这就完成了一个加法操作,看下面的实例:
public class test6 {public static void main(String[] args) {int a=1;a = a+1;}}
很简单一个例子,要分析就要通过字节码进行分析,字节码如下:
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=2, args_size=10: iconst_11: istore_12: iload_13: iconst_14: iadd5: istore_16: return
省略了部分,我们来分析这个字节码的内容
第一行代表这个字节码是main方法的字节码
第二行是这个方法的描述信息,说明这个方法的参数是String类型的一维数组,其返回值是void
第三行表示控制修饰符:说明这个方法的控制描述符(AccessFlag)是public、static
第五行表示,操作数栈深度为2,局部变量表数为2,参数大小是1
剩下的就是这个main方法的具体实现过程
- 0:iconst_1:把int类型的常量1压入到操作数栈中,对应着是代码中的 int a=1;
- 1:istore_1:把int类型的值从操作数栈中弹出,将其放到位置为1的局部变量中;
- 2: iload_1:将位置为1的int类型的局部变量压入栈;
- 3: iconst_1:把int类型的常量1压入到操作数栈中,对应着是代码中的 a+1的1;
- 4:iadd: 从操作数栈栈顶弹出两个元素然后做加法,把结果压入栈。对应着代码中的a=a+1;
- 5:istore_1:把int类型的值从操作数栈中弹出,将其放到位置为1的局部变量中;
- 6:return表示结束。
很容易看出:一个简单的Java程序,其原理无非就是数据再内存中入栈出栈并进行计算的过程,其常量在编译期均已经确定并存于局部变量表中,因为字节码是根据class文件反编译而成,
- 基本类型的内存模型是什么
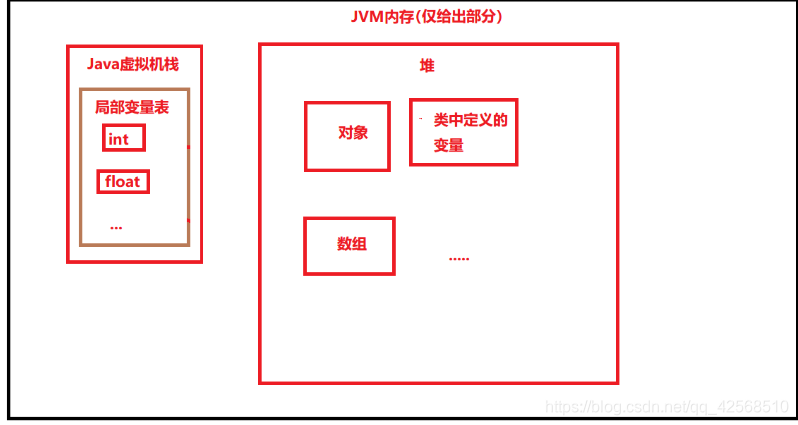
方法中的基本类型如int、float等类型是直接存在局部变量表中的,类中的基本类型数据是存在堆中的。
参考资料
java中的基本数据类型和引用类型在JVM中存储在哪?
包装类和基本类型
操作数详解一
操作数详解二
自动拆箱装箱
Java基本类型详解
基本类型和包装类型的区别