在实际的项目环境中碰到了如下的问题
Microsoft.Data.SqlClient.SqlException (0x80131904): 事务(进程 ID
98)与另一个进程被死锁在 锁 资源上,并且已被选作死锁牺牲品。请重新运行该事务。
怀疑是因为数据库查询和修改中产生的死锁问题,造成的上述原因。
我在百度查询出存在如下一种情况会出现这种问题。
引起这个问题主要是因为违反了事务的隔离性
隔离性:并发多个事务时,各个事务不干涉内部数据,处理的都是另外一个事务处理之前或之后的数据。

依次执行如上代码,就会出现我们今天讲解的问题

这就是因为“锁”造成的。
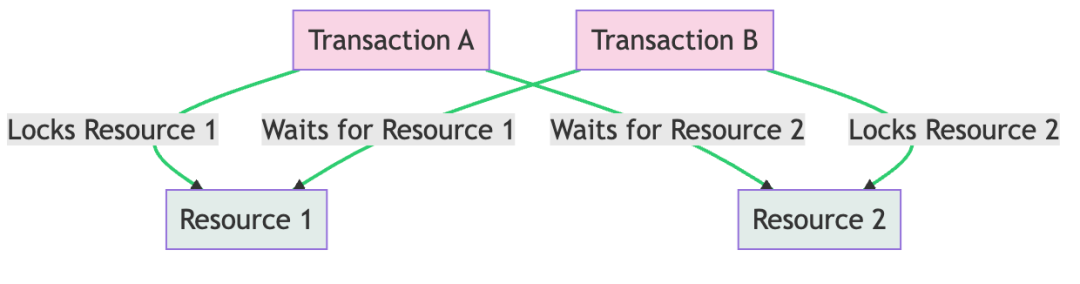
在执行事务的时候,如果其中有修改语句,就是更新锁,资源的更新锁一次只能分配给一个事务,如果需要对资源进行修改,更新锁会变成排他锁。
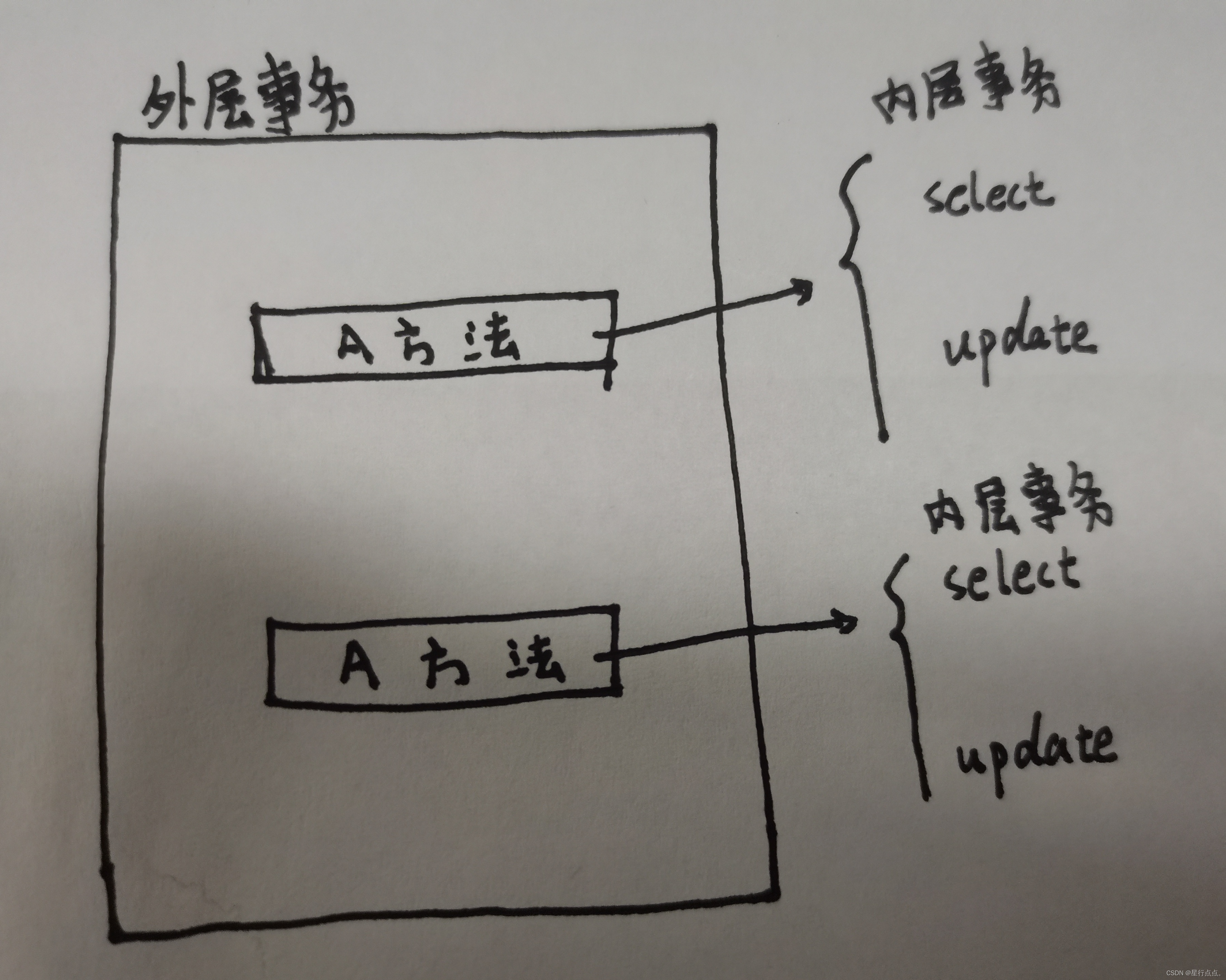
我们来分析一下上面的sql语句;
首先 我们执行左边的sql语句,执行了第一条sql语句,Dome表—延迟4秒—Domes表
然后 我们执行右边的sql语句,执行了第一条sql语句,Domes表—延迟4秒—Dome表
执行过程如下,
第一个事务更新Dome表,就为Dome表上锁;
第二个事务更新Domes表,就位Domes表上锁;
然后延迟4秒后,两个事务都要各自去更新已经上锁的表,所以这就造成了死锁,数据库发现了这种情况,就会检查选择一个合适事务作为牺牲品,牺牲品回滚数据。注意:数据库在选择牺牲品的时候,是有一套自己的判断程序的,他们会判断哪个事务更适合作为牺牲品,与执行事务的先后顺序无关,也可以设置死锁处理的优先级别,这里不多叙述。
注意:只有当事务修改的数据有冲突的时候,才会死锁,我们更新数据的时候,都是带上where条件更新某一条数据,这种情况下,只要当两个事务都是更新你指定那一条数据。才会触发死锁。
处理死锁
当 SQL Server 数据库引擎的实例选择事务作为死锁受害者时,它会终止当前批处理,回滚事务,并将错误消息 1205 返回到应用程序。
Your transaction (process ID #52) was deadlocked on {lock | communication buffer | thread} resources with another process and has been chosen as the deadlock victim. Rerun your transaction.
由于任何提交 Transact-SQL 查询的应用程序都可以选择为死锁受害者,因此应用程序应具有可捕获错误消息 1205 的错误处理程序。 如果应用程序不处理该错误,可以继续操作,但是不知道自己的事务已回滚而且可能出错。
通过实现捕获 1205 号错误消息的错误处理程序,使应用程序得以处理该死锁情况并采取补救措施(例如,可以自动重新提交陷入死锁中的查询)。 通过自动重新提交查询,用户不必知道发生了死锁。
应用程序在重新提交其查询前应短暂暂停。 这样会给死锁涉及的另一个事务一个机会来完成并释放构成死锁循环一部分的该事务的锁。 这将把重新提交的查询请求其锁时,死锁重新发生的可能性降到最低。
将死锁减至最少
尽管死锁不能完全避免,但遵守特定的编码惯例可以将发生死锁的机会降至最低。 将死锁减至最少可以增加事务的吞吐量并减少系统开销,因为只有很少的事务:
- 回滚,撤消事务执行的所有工作。
- 由于死锁时回滚而由应用程序重新提交。
- 下列方法有助于将死锁减至最少:
按同一顺序访问对象。
避免事务中的用户交互。 - 使事务保持简短且一批。
使用较低的隔离级别。
使用基于行版本控制的隔离级别。
将 READ_COMMITTED_SNAPSHOT 数据库选项设置为 on,以使读取提交的事务可以使用行版本控制。
使用快照隔离。
使用绑定连接。
详情可见:https://learn.microsoft.com/zh-cn/sql/relational-databases/sql-server-transaction-locking-and-row-versioning-guide?view=sql-server-ver16#deadlock_minimizing
解决方案:https://techcommunity.microsoft.com/t5/sql-server-support-blog/deadlock-simulator-app-for-developers-how-to-handle-a-sql/ba-p/334019







![[Software]Vivado 2018.2 安装及激活教程](https://img-blog.csdnimg.cn/20200528143844738.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0tLS0tLS09CRV8yNA==,size_16,color_FFFFFF,t_70)