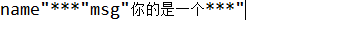1.replace过滤
最简单也是最直接的就是直接循环敏感词,然后使用replace过滤关键词,文章和敏感词少的时候还可以,多的时候效率就真的很一般了。
2.使用正则过滤
有两个技术要点,
1.使用Python正则表达式的re的sub()函数;
2.在正则表达式语法中,竖线“|”表示二选一或多选一。
代码参考
Python
1
2
3
4
5
6
7
8
importre
defcheck_filter(keywords,text):
returnre.sub("|".join(keywords),"***",text)
keywords=("暴力","色情","其他关键字")
text="这句话里不包含暴力,也不包含色情,但是可能包含其他关键字"
print(check_filter(keywords,text))
返回结果
Python
1
2
这句话里不包含***,也不包含***,但是可能包含***
3.DFA过滤敏感词算法
在网上查了下敏感词过滤方案,找到了一种名为DFA的算法,即 Deterministic Finite Automaton 算法,翻译成中文就是确定有穷自动机算法。它的基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测,所以效率比方案一高不少。
假设我们有以下5个敏感词需要检测:傻逼、傻子、傻大个、坏蛋、坏人。那么我们可以先把敏感词中有相同前缀的词组合成一个树形结构,不同前缀的词分属不同树形分支,以上述5个敏感词为例,可以初始化成如下2棵树:


把敏感词组成成树形结构有什么好处呢?最大的好处就是可以减少检索次数,我们只需要遍历一次待检测文本,然后在敏感词库中检索出有没有该字符对应的子树就行了,如果没有相应的子树,说明当前检测的字符不在敏感词库中,则直接跳过继续检测下一个字符;如果有相应的子树,则接着检查下一个字符是不是前一个字符对应的子树的子节点,这样迭代下去,就能找出待检测文本中是否包含敏感词了。
我们以文本“你是不是傻逼”为例,我们依次检测每个字符,因为前4个字符都不在敏感词库里,找不到相应的子树,所以直接跳过。当检测到“傻”字时,发现敏感词库中有相应的子树,我们把他记为tree-1,接着再搜索下一个字符“逼”是不是子树tree-1的子节点,发现恰好是,接下来再判断“逼”这个字符是不是叶子节点,如果是,则说明匹配到了一个敏感词了,在这里“逼”这个字符刚好是tree-1的叶子节点,所以成功检索到了敏感词:“傻逼”。大家发现了没有,在我们的搜索过程中,我们只需要扫描一次被检测文本就行了,而且对于被检测文本中不存在的敏感词,如这个例子中的“坏蛋”和“坏人”,我们完全不会扫描到,因此相比方案一效率大大提升了。
在python中,我们可以用dict来存储上述的树形结构,还是以上述敏感词为例,我们把每个敏感词字符串拆散成字符,再存储到dict中,可以这样存:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
{
'傻':{
'逼':{
'\x00':0
},
'子':{
'\x00':0
},
'大':{
'个':{
'\x00':0
}
}
},
'坏':{
'蛋':{
'\x00':0
},
'人':{
'\x00':0}
}
}
首先将每个词的第一个字符作为key,value则是另一个dict,value对应的dict的key为第二个字符,如果还有第三个字符,则存储到以第二个字符为key的value中,当然这个value还是一个dict,以此类推下去,直到最后一个字符,当然最后一个字符对应的value也是dict,只不过这个dict只需要存储一个结束标志就行了,像上述的例子中,我们就存了一个{'\x00': 0}的dict,来表示这个value对应的key是敏感词的最后一个字符。
同理,“坏人”和“坏蛋”这2个敏感词也是按这样的方式存储起来,这里就不罗列出来了。
用dict存储有什么好处呢?我们知道dict在理想情况下可以以O(1)的时间复杂度进行查询,所以我们在遍历待检测字符串的过程中,可以以O(1)的时间复杂度检索出当前字符是否在敏感词库中,效率比方案一提升太多了。
接下来上代码。
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
# -*- coding:utf-8 -*-
importtime
time1=time.time()
# DFA算法
classDFAFilter(object):
def__init__(self):
self.keyword_chains={}# 关键词链表
self.delimit='\x00'# 限定
defadd(self,keyword):
keyword=keyword.lower()# 关键词英文变为小写
chars=keyword.strip()# 关键字去除首尾空格和换行
ifnotchars:# 如果关键词为空直接返回
return
level=self.keyword_chains
# 遍历关键字的每个字
foriinrange(len(chars)):
# 如果这个字已经存在字符链的key中就进入其子字典
ifchars[i]inlevel:
level=level[chars[i]]
else:
ifnotisinstance(level,dict):
break
forjinrange(i,len(chars)):
level[chars[j]]={}
last_level,last_char=level,chars[j]
level=level[chars[j]]
last_level[last_char]={self.delimit:0}
break
ifi==len(chars)-1:
level[self.delimit]=0
defparse(self,path):
withopen(path,encoding='utf-8')asf:
forkeywordinf:
self.add(str(keyword).strip())
print(self.keyword_chains)
deffilter(self,message,repl="*"):
message=message.lower()
ret=[]
start=0
whilestart
level=self.keyword_chains
step_ins=0
forchar inmessage[start:]:
ifchar inlevel:
step_ins+=1
ifself.delimit notinlevel[char]:
level=level[char]
else:
ret.append(repl*step_ins)
start+=step_ins-1
break
else:
ret.append(message[start])
break
else:
ret.append(message[start])
start+=1
return''.join(ret)
if__name__=="__main__":
gfw=DFAFilter()
path="E:/lyh/test/sensitive_words.txt"
gfw.parse(path)
text="你真是个大傻逼,大傻子,傻大个,大坏蛋,坏人。"
result=gfw.filter(text)
print(text)
print(result)
time2=time.time()
print('总共耗时:'+str(time2-time1)+'s')
sensitive_words.txt
Python
1
2
3
4
5
6
傻逼
傻子
傻大个
坏蛋
坏人
运行结果
Python
1
2
3
4
你真是个大傻逼,大傻子,傻大个,大坏蛋,坏人。
你真是个大**,大**,***,大**,**。
总共耗时:0.0009999275207519531s
4.AC自动机过滤敏感词算法
AC自动机:一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。
简单地讲,AC自动机就是字典树+kmp算法+失配指针
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
# -*- coding:utf-8 -*-
importtime
time1=time.time()
# AC自动机算法
classnode(object):
def__init__(self):
self.next={}
self.fail=None
self.isWord=False
self.word=""
classac_automation(object):
def__init__(self):
self.root=node()
# 添加敏感词函数
defaddword(self,word):
temp_root=self.root
forchar inword:
ifchar notintemp_root.next:
temp_root.next[char]=node()
temp_root=temp_root.next[char]
temp_root.isWord=True
temp_root.word=word
# 失败指针函数
defmake_fail(self):
temp_que=[]
temp_que.append(self.root)
whilelen(temp_que)!=0:
temp=temp_que.pop(0)
p=None
forkey,value intemp.next.item():
iftemp==self.root:
temp.next[key].fail=self.root
else:
p=temp.fail
whilepisnotNone:
ifkey inp.next:
temp.next[key].fail=p.fail
break
p=p.fail
ifpisNone:
temp.next[key].fail=self.root
temp_que.append(temp.next[key])
# 查找敏感词函数
defsearch(self,content):
p=self.root
result=[]
currentposition=0
whilecurrentposition
word=content[currentposition]
whileword inp.next==Falseandp!=self.root:
p=p.fail
ifword inp.next:
p=p.next[word]
else:
p=self.root
ifp.isWord:
result.append(p.word)
p=self.root
currentposition+=1
returnresult
# 加载敏感词库函数
defparse(self,path):
withopen(path,encoding='utf-8')asf:
forkeywordinf:
self.addword(str(keyword).strip())
# 敏感词替换函数
defwords_replace(self,text):
"""
:param ah: AC自动机
:param text: 文本
:return: 过滤敏感词之后的文本
"""
result=list(set(self.search(text)))
forxinresult:
m=text.replace(x,'*'*len(x))
text=m
returntext
if__name__=='__main__':
ah=ac_automation()
path='F:/文本反垃圾算法/sensitive_words.txt'
ah.parse(path)
text1="新疆骚乱苹果新品发布会雞八"
text2=ah.words_replace(text1)
print(text1)
print(text2)
time2=time.time()
print('总共耗时:'+str(time2-time1)+'s')
运行结果