记录背景:SpringBoot项目实现敏感词汇过滤
一:敏感词汇文件放置位置
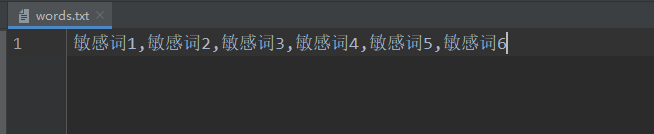
二:说明:如果txt文件不能编译,pom文件添加下面配置
<build><resources><resource><directory>src/main/resources</directory><includes><include>**/*.*</include></includes></resource></resources></build>
三:简单的内存缓存敏感词汇类
public class Cache {/*** 键值对集合*/private final static ConcurrentHashMap<String, List<String>> MAP = new ConcurrentHashMap<>();/*** 添加缓存 */public synchronized static void put(String key, List<String> data) {//清除原键值对Cache.remove(key);//不设置过期时间MAP.put(key, data);}/*** 读取缓存 */public static List<String> get(String key) {return MAP.get(key);}/*** 清除缓存*/public synchronized static void remove(String key) {MAP.remove(key);}
}
四:敏感词汇过滤替换为*
package cloud.exec.common.wordfilterutils;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.*;
/*** 敏感词汇过滤替换为** 说明:部分代码来源于互联网*/
@Slf4j
public class WordFilter {private final static String WORDS = "WORDS";private final static String REPLACE_CHAR = "*";private static HashMap sensitiveWordMap;/** * 最小匹配规则 */private static int minMatchTYpe = 1;/** * 最大匹配规则 */private static int maxMatchType = 2;/*** 敏感词汇过滤替换为* ** @param text 待检测文字* @return 替换后文字*/public static String replaceWords(String text) {if (StringUtils.isBlank(text)) {return text;}//缓存获取敏感词汇原记录List<String> words = Cache.get(WORDS);if (CollectionUtils.isEmpty(words)) {//读取敏感词汇文件,存入缓存words = readWordsFile();Cache.put(WORDS, words);}if (CollectionUtils.isEmpty(words)) {return text;}//屏蔽敏感词汇return WordFilter.replaceSensitiveWord(words, text, WordFilter.minMatchTYpe);}/*** 读取敏感词汇文件*/private static List<String> readWordsFile() {List<String> list = new ArrayList<>();InputStream inputStream = null;InputStreamReader inputStreamReader = null;BufferedReader bufferedReader = null;try {Resource resource = new DefaultResourceLoader().getResource("classpath:words.txt");inputStream = resource.getInputStream();inputStreamReader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);bufferedReader = new BufferedReader(inputStreamReader);String txt = "";while (StringUtils.isNotBlank(txt = bufferedReader.readLine())) {list.addAll(Arrays.asList(StringUtils.split(StringUtils.deleteWhitespace(StringUtils.replace(txt, ",", ",")),",")));}bufferedReader.close();inputStreamReader.close();inputStream.close();} catch (Exception e) {log.error("读取敏感词汇文件出错", e);} finally {try {if (bufferedReader != null) {bufferedReader.close();}if (inputStreamReader != null) {inputStreamReader.close();}if (inputStream != null) {inputStream.close();}} catch (Exception e) {log.error("读取敏感词汇文件出错", e);}}return list;}/*** 替换敏感字字符** @param data 敏感字集合* @param txt 待检查文本* @param matchType 匹配规则*/private static String replaceSensitiveWord(List<String> data, String txt, int matchType) {if (sensitiveWordMap == null) {addSensitiveWord(data);}String resultTxt = txt;//获取所有的敏感词List<String> set = getSensitiveWord(txt, matchType);Iterator<String> iterator = set.iterator();while (iterator.hasNext()) {resultTxt = resultTxt.replaceAll(iterator.next(), REPLACE_CHAR);}return resultTxt;}/*** 读取敏感词库,将敏感词放入HashSet中,构建一个DFA算法模型:* 说明:该方法来源于互联网*/private static void addSensitiveWord(List<String> datas) {sensitiveWordMap = new HashMap(datas.size());Iterator<String> iterator = datas.iterator();Map<String, Object> now = null;Map now2 = null;while (iterator.hasNext()) {now2 = sensitiveWordMap;String word = iterator.next().trim(); //敏感词for (int i = 0; i < word.length(); i++) {char key_word = word.charAt(i);Object obj = now2.get(key_word);if (obj != null) { //存在now2 = (Map) obj;} else { //不存在now = new HashMap<String, Object>();now.put("isEnd", "0");now2.put(key_word, now);now2 = now;}if (i == word.length() - 1) {now2.put("isEnd", "1");}}}}/*** 获取内容中的敏感词*说明:该方法来源于互联网* @param text 内容* @param matchType 匹配规则 1=不最佳匹配,2=最佳匹配* @return*/private static List<String> getSensitiveWord(String text, int matchType) {List<String> words = new ArrayList<String>();Map now = sensitiveWordMap;int count = 0; //初始化敏感词长度int start = 0; //标志敏感词开始的下标for (int i = 0; i < text.length(); i++) {char key = text.charAt(i);now = (Map) now.get(key);if (now != null) { //存在count++;if (count == 1) {start = i;}if ("1".equals(now.get("isEnd"))) { //敏感词结束now = sensitiveWordMap; //重新获取敏感词库words.add(text.substring(start, start + count)); //取出敏感词,添加到集合count = 0; //初始化敏感词长度}} else { //不存在now = sensitiveWordMap;//重新获取敏感词库if (count == 1 && matchType == 1) { //不最佳匹配count = 0;} else if (count == 1 && matchType == 2) { //最佳匹配words.add(text.substring(start, start + count));count = 0;}}}return words;}public WordFilter() {super();}
}
五:测试