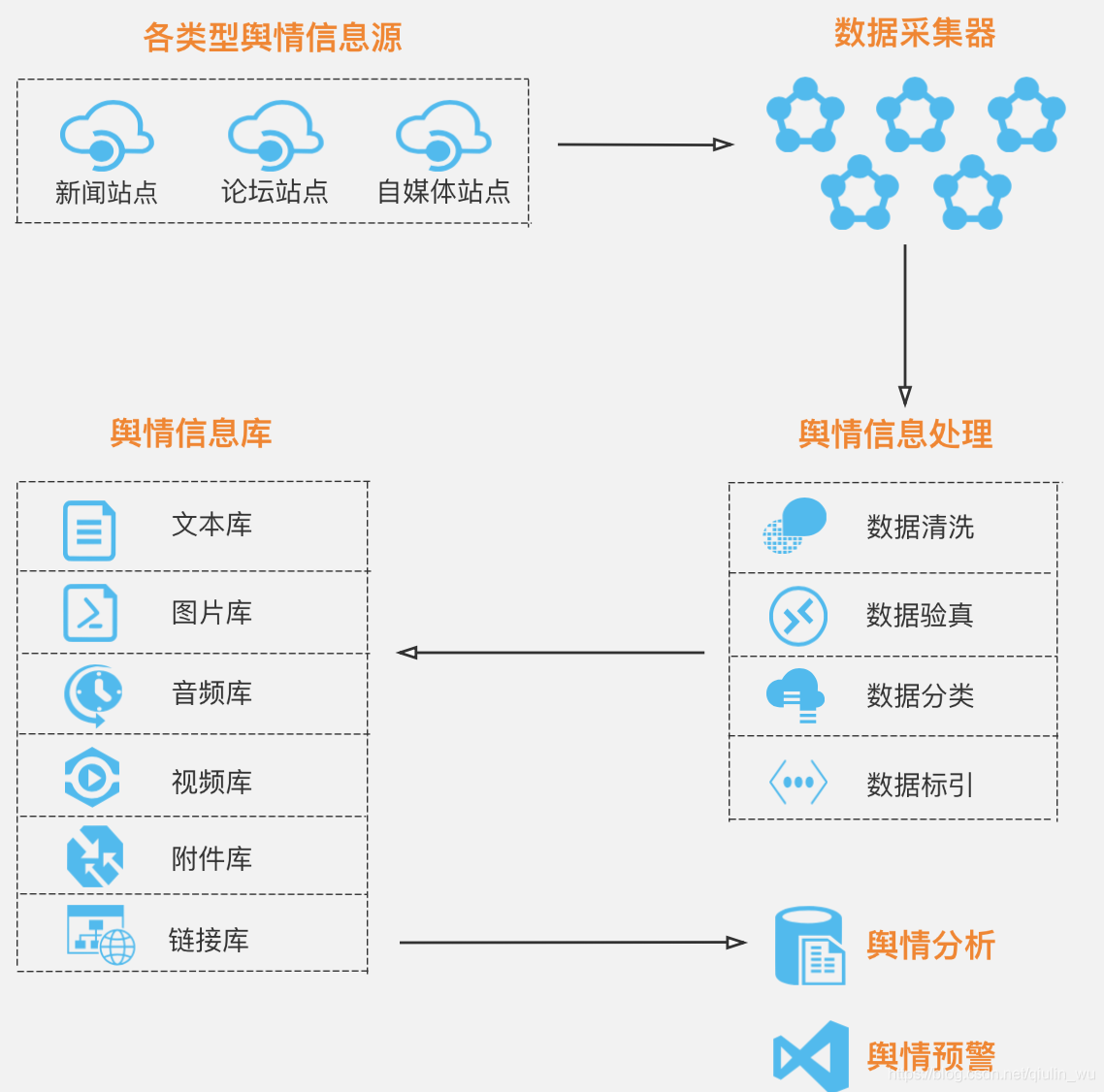
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、如何读取txt文件,将其转化为DataFrame格式
- 二、给DataFrame添加列名
- 三、删除指定行
- 四、读取csv文件,不让第一行成为列名
- 五、读取DataFrame的第几行第几列
- 六、读取数据时,删除含有空值的行或列
- 七、将dict数据存储到txt中
- 八、DataFrame 按照条件删选数据
- 九、使用SVM训练鸢尾花数据集中的一些函数用法
一、如何读取txt文件,将其转化为DataFrame格式
f = open("G:\\prediction\\BIOGRID-ORGANISM-Homo_sapiens-4.4.204.tab3.txt","r",encoding='utf-8') #设置文件对象
result=[]
for line in f.readlines():#readlines以列表输出文件内容line=line.strip().split("\t")result.append(line)
f.close() #将文件关闭
result=pd.DataFrame(result).dropna(axis=0)
二、给DataFrame添加列名
usedata.columns=["Official Symbol Interactor A","Official Symbol Interactor B"]
usedata

三、删除指定行
usedata=usedata.drop([0])
#[]里面是行号
四、读取csv文件,不让第一行成为列名
# 读取数据
import pandas as pd
score = pd.read_csv(r"C:\Users\zyy\Desktop\source_code\out_dbis\dbis.cac.w5.l10_other.csv",header=None).dropna(axis=1)
score
# 主要是header=None,如果不加,第一行就成为了列名

五、读取DataFrame的第几行第几列
score.loc[2]
# loc[i] 读取第i行
score.iloc[2]
# iloc[i] 读取第i列
六、读取数据时,删除含有空值的行或列
dropna()方法,可以找到DataFrame类型数据的空值,将空值所在的行/列删除后,将新的DataFrame作为返回值返回。
函数形式:dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
参数:
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
使用dropna()删除后

七、将dict数据存储到txt中


八、DataFrame 按照条件删选数据
需求就是 我有个DataFrame里面存储了许多数据,包括name ,以及其他的信息。我这里也有一个list里面包含了我所需要的数据的name. 就是按照list里面的name筛选数据
使用方法:
isin函数:df[df[“column_name”].isin(li)] (# li = [20, 25, 27] 或 li = np.arange(20, 30))
根据从isin函数传入的列表(li),筛选出与列表中包含的数值或字符串相同的数据记录, 用法有点类似sql中的"in"
下面这个是原始数据:

这个是筛选之后的数据:

九、使用SVM训练鸢尾花数据集中的一些函数用法
- np.loadtxt()加载数据
- numpy.split()函数 分割数据
- sklearn的train_test_split()各函数参数含义解释(非常全)