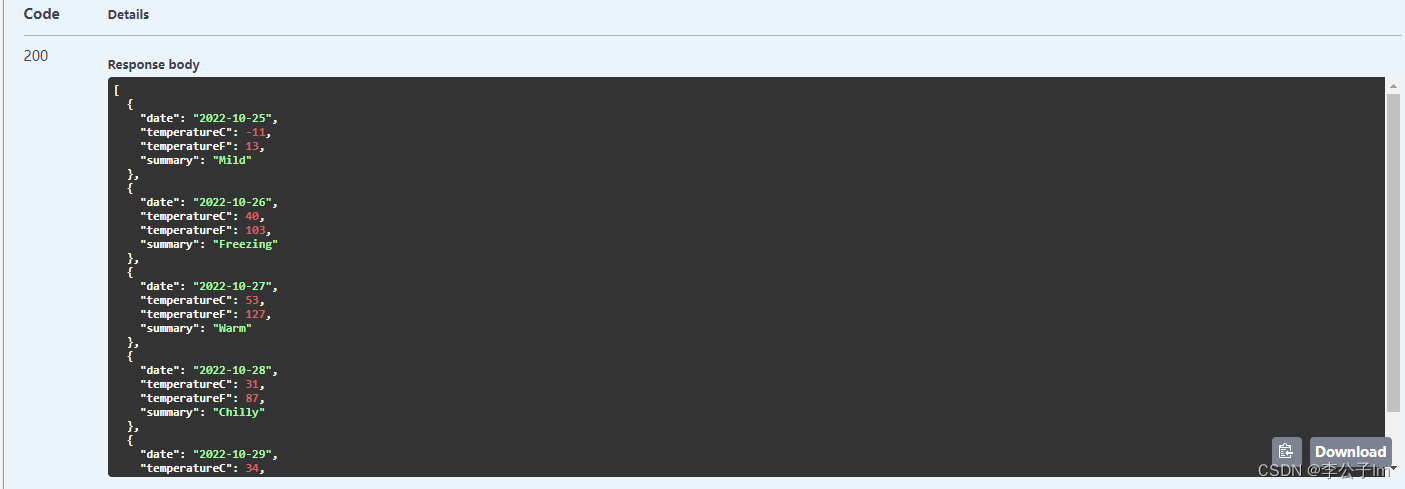
我用的是递归循环的,不限制有多少子级关系都可以拿到
首先引入解析mpp所需依赖
<dependency><groupId>net.sf.mpxj</groupId><artifactId>mpxj</artifactId><version>7.1.0</version></dependency>
解析所用实体类,每个字段都有对应意思
public class ArrowDiagramImport extends Model<ArrowDiagramImport> {@TableId(value = "ID")private String id;/*** 序号*/@TableField(value = "SERIAL_NUMBER",exist = true )private String serialNumber;/*** 节点名称*/@TableField(value = "TASK_NAME",exist = true )private String taskName;/*** 前置节点ID*/@TableField(value = "PARENT_ID",exist = true )private String parentId;/*** 工期*/@TableField(value = "DURATION",exist = true )private Double duration;/*** 计划开始时间*/@TableField(value = "PLAN_START_DATE",exist = true )@JsonFormat(locale="zh", timezone="GMT+8", pattern="yyyy-MM-dd")private Date planStartDate;/*** 计划结束时间*/@TableField(value = "PLAN_END_DATE",exist = true )@JsonFormat(locale="zh", timezone="GMT+8", pattern="yyyy-MM-dd")private Date planEndDate;/*** 层级*/@TableField(value = "plan_level",exist = true )private String planLevel;/*** 是否拆分 0是 1否(代表该条数据是不是父节点)*/@TableField(value = "is_not_split",exist = true )private String isNotSplit;/*** 拆分后子任务的父节点序号*/@TableField(value = "split_parent_id",exist = true )private String splitParentId;}
核心代码
public void mppFileAnalysis(MultipartFile multipartFile) {try {//读取文件的组件MPPReader mppReader = new MPPReader();//注意,如果在这一步出现了读取异常,肯定是版本不兼容,换个版本试试ProjectFile pf = mppReader.read(multipartFile.getInputStream());//从文件中获取的任务对象List<Task> tasks = pf.getChildTasks();//解析后数据存入对象List<ArrowDiagramImport> importList = new ArrayList<>();//递归解析方法childrenTask(tasks.get(0).getChildTasks(), new ArrowDiagramImport(), importList);for (ArrowDiagramImport diagramImport : importList) {System.out.println(diagramImport.getTaskName());}} catch (Exception e) {e.printStackTrace();}}递归方法
taskList 循环解析对象,rtSingleArrowDiagramImport 代表当前循环的数据是它的子级,importList 循环解析后数据存入的集合
//taskList 循环解析对象,rtSingleArrowDiagramImport 代表当前循环的数据是它的子级,importList 循环解析后数据存入的集合public void childrenTask(List<Task> taskList, ArrowDiagramImport rtSingleArrowDiagramImport, List<ArrowDiagramImport> importList) {//设置层级,如果等于空,则代表是第一层级,不为空则在父级节点的层级基础上+1int levelNum;if (StringUtils.isEmpty(rtSingleArrowDiagramImport.getPlanLevel())) {levelNum = 1;} else {levelNum = Integer.parseInt(rtSingleArrowDiagramImport.getPlanLevel()) + 1;}//循环所有节点for (Task task : taskList) {ArrowDiagramImport diagramImport = new ArrowDiagramImport();diagramImport.setId(StringUtils.getUUID());diagramImport.setSerialNumber(task.getID().toString());diagramImport.setSplitParentId(rtSingleArrowDiagramImport.getSerialNumber());//将上一级目录的Id赋值给下一级的ParentIddiagramImport.setPlanLevel(String.valueOf(levelNum));//层级diagramImport.setTaskName(task.getName());//这个是获取文件中的“任务名称”列的数据diagramImport.setDuration(task.getDuration().getDuration());//获取的是文件中的“工期”diagramImport.setPlanStartDate(task.getStart());//获取文件中的 “开始时间”diagramImport.setPlanEndDate(task.getFinish());//获取文件中的 “完成时间”diagramImport.setParentId(getParentIds(task));if (task.getChildTasks().size() > 0) {diagramImport.setIsNotSplit(DelFlagType.Normal.getType());childrenTask(task.getChildTasks(), diagramImport, importList);//继续进行递归,当前保存的只是父任务的信息} else {diagramImport.setIsNotSplit(DelFlagType.Delete.getType());}importList.add(diagramImport);}}
该方法是为了获取前置节点的关系,包含特殊前置关系
public String getParentIds(Task task) {String parentId = "";if (task.getPredecessors().size() > 0) {for (Relation relation : task.getPredecessors()) {//前置节点IDString id = relation.getTargetTask().getID().toString();//关联前置节点的关系 FS/FF/SS/SFString type = relation.getType().toString();//与前置节点关系的天数Integer duration = (int) relation.getLag().getDuration();//如果类型=FS,并且天数为0,则代表没有特殊关系if (type.equals(DiagramPlanType.FS.getCode()) && duration == 0.0) {parentId += id + ",";} else {String durationStr = "";if (duration > 0.0) {durationStr = "+" + duration + "工日";} else if (duration < 0.0) {durationStr = duration.toString() + "工日";}parentId += id + type + durationStr + ",";}}parentId = parentId.substring(0, parentId.length() - 1);}return parentId;}