目录
- 浅读Rasa3.2.5源码(rasa train、rasa shell)
- 一、 分析 __main__.py
- (1). 解析main.py的部分代码
- (2). rasa常用命令
- 二、 训练阶段
- (1). 准备训练数据
- (2). 跟踪模型训练
- 1. 从配置文件和参数中构造有向无环图
- 2. 运行有向无环图,这是模型实际进行训练和持久化的过程
- (3). 返回模型文件路径
- 三、 推理阶段
- (1). 建立connector,对外提供访问接口
- (2). 从磁盘载入模型:rasa/core/agent.py
- (3). 处理用户消息
- 四、思维导图
- 五、 结语
浅读Rasa3.2.5源码(rasa train、rasa shell)
你好,这里写这篇文章的原因是因为想要探究两个问题:
1、 终端执行rasa shell命令并出现交互界面后,rasa在此之前做了哪些工作?
2、 当用户发出消息后,rasa如何根据该消息执行动作?
本文主要记录了一些关于rasa train和rasa shell 的浅显见解:
(同时参考了孔晓泉大佬出版的《rasa实战》并使用了部分图表,如有不妥,立即删除)
一、 分析 main.py
(1). 解析main.py的部分代码
首先rasa会创建一个rasa命令的解析器,这包含了所有子指令(如shell、run等)的子解析器,确保你在终端输入的具体指令可以被及时执行。
# 创建一个命令解析器
def create_argument_parser() -> argparse.ArgumentParser:"""Parse all the command line arguments for the training script."""parser = argparse.ArgumentParser(prog="rasa",formatter_class=argparse.ArgumentDefaultsHelpFormatter,description="Rasa command line interface. Rasa allows you to build ""your own conversational assistants 🤖. The 'rasa' command ""allows you to easily run most common commands like ""creating a new bot, training or evaluating models.",)# 创建一条子命令 rasa --versionparser.add_argument("--version",action="store_true",default=argparse.SUPPRESS,help="Print installed Rasa version",)parent_parser = argparse.ArgumentParser(add_help=False)add_logging_options(parent_parser)parent_parsers = [parent_parser]subparsers = parser.add_subparsers(help="Rasa commands")# 为子命令创建子解析器,为了可以指定具体参数执行# 如rasa train 、 rasa shellscaffold.add_subparser(subparsers, parents=parent_parsers)run.add_subparser(subparsers, parents=parent_parsers)shell.add_subparser(subparsers, parents=parent_parsers)train.add_subparser(subparsers, parents=parent_parsers)interactive.add_subparser(subparsers, parents=parent_parsers)telemetry.add_subparser(subparsers, parents=parent_parsers)test.add_subparser(subparsers, parents=parent_parsers)visualize.add_subparser(subparsers, parents=parent_parsers)data.add_subparser(subparsers, parents=parent_parsers)export.add_subparser(subparsers, parents=parent_parsers)x.add_subparser(subparsers, parents=parent_parsers)evaluate.add_subparser(subparsers, parents=parent_parsers)return parser(2). rasa常用命令
| 命令 | 功能 |
|---|---|
| rasa init | 创建一个新的项目,包含样本训练模型、配置和动作 |
| rasa train | 使用NLU训练数据、故事数据和配置训练模型,默认情况下模型保存在/models目录中 |
| rasa interactive | 交互式的训练:通过和机器人对话修正可能的错误,并将对话数据导出 |
| rasa run | 运行Rasa 服务器 |
| rasa shell | 等价于执行rasa run命令,开启基于命令行界面的对话界面和机器人交流 |
| rasa run actions | 运行Rasa动作服务器 |
| rasa x | 启动RasaX服务器(如果没有安装RasaX的话会提示安装吗,并且RasaX是与Rasa适配,版本不匹配,会无法使用 1) |
| rasa -h | 打印 Rasa命令的帮助信息 |
二、 训练阶段
训练阶段是执行了rasa train命令。即运行了/rasa/cli/train.py文件。

从源码看出,rasa train 也可以只单独训练nlu 或者 core 部分,并有相应的训练函数。
# 为 rasa train 再创建一个子命令解析器train_subparsers = train_parser.add_subparsers()# '''add_parser:为 rasa train 添加指定命令 core'''train_core_parser = train_subparsers.add_parser("core",parents=parents,conflict_handler="resolve",formatter_class=argparse.ArgumentDefaultsHelpFormatter,help="Trains a Rasa Core model using your stories.",)train_core_parser.set_defaults(func=run_core_training) ## 添加训练core的函数(rasa train core)# '''add_parser:为 rasa train 添加指定命令 nlu'''train_nlu_parser = train_subparsers.add_parser("nlu",parents=parents,formatter_class=argparse.ArgumentDefaultsHelpFormatter,help="Trains a Rasa NLU model using your NLU data.",)train_nlu_parser.set_defaults(func=run_nlu_training) ## 添加训练nlu的函数(rasa train nlu)(1). 准备训练数据
从源码可以看出参与训练的数据只有data文件夹、domain.yml和config.yml文件。
def run_training(args: argparse.Namespace, can_exit: bool = False) -> Optional[Text]:"""Trains a model.Args:args: Namespace arguments.can_exit: If `True`, the operation can send `sys.exit` in the casetraining was not successful.Returns:经过训练的模型的路径,如果训练不成功,则为“无”Path to a trained model or `None` if training was not successful."""## train: rasa.api.train()from rasa import train as train_all# 可以指定路径,否则就默认路径# get_validated_path:检查路径是否存在并且合理domain = rasa.cli.utils.get_validated_path(args.domain, "domain", DEFAULT_DOMAIN_PATH, none_is_valid=True)config = _get_valid_config(args.config, CONFIG_MANDATORY_KEYS)training_files = [rasa.cli.utils.get_validated_path(f, "data", DEFAULT_DATA_PATH, none_is_valid=True)for f in args.data]## ---------读到此处就可以知道rasa train只需要data、config和domain文件------------------
(2). 跟踪模型训练
事实上,模型训练的主要函数是rasa/model_training.py的track_model_training()。
1. 从配置文件和参数中构造有向无环图
# 将配置转换为与图形兼容的模型配置# 构造有向无环图model_configuration = recipe.graph_config_for_recipe(config,kwargs,training_type=training_type,is_finetuning=is_finetuning,)
2. 运行有向无环图,这是模型实际进行训练和持久化的过程
trainer.train(model_configuration,file_importer,full_model_path,force_retraining=force_full_training,is_finetuning=is_finetuning,)
(3). 返回模型文件路径
训练的模型一般就保存到/models文件夹下。
return self._model_storage.create_model_package(output_filename, model_configuration, domain)
三、 推理阶段
代码位置:rasa/cli/shell.py
rasa shell 也可以只测试nlu部分,来帮助我们测试nlu样本部分,看能否正确识别用户的意图。
即rasa shell nlu。
shell_nlu_subparser = run_subparsers.add_parser("nlu",parents=parents,conflict_handler="resolve",formatter_class=argparse.ArgumentDefaultsHelpFormatter,help="Interprets messages on the command line using your NLU model.",)
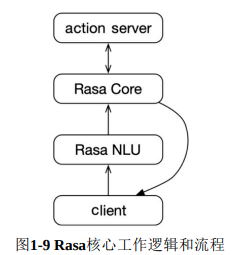
可以看到,rasa shell 实际上是等价于rasa run的。在shell函数里,最终是启动了run函数。
# rasa shell nluif metadata.training_type == TrainingType.NLU:import rasa.nlu.runtelemetry.track_shell_started("nlu")rasa.nlu.run.run_cmdline(model)# rasa shell# 其实 rasa shell 等价于 rasa runelse:import rasa.cli.runtelemetry.track_shell_started("rasa")rasa.cli.run.run(args)
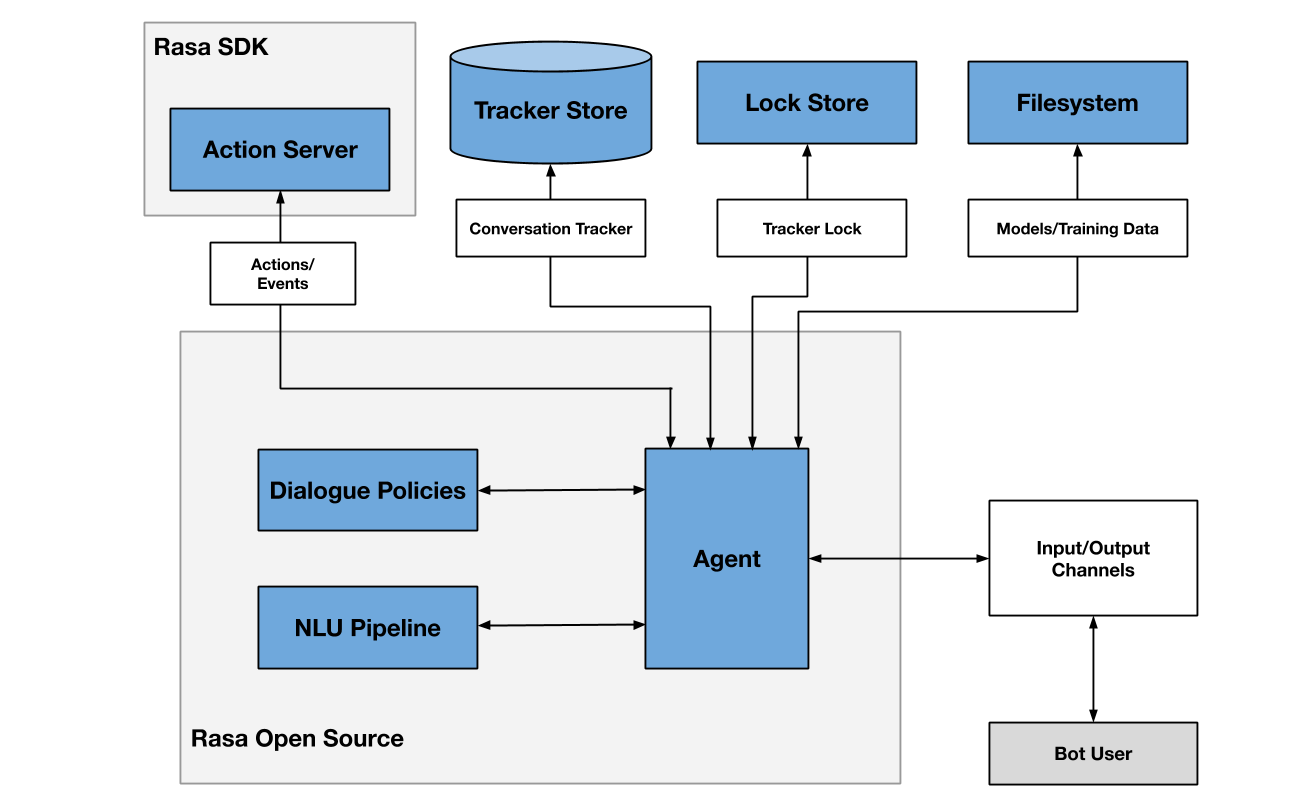
接下来的推理阶段主要在rasa/core/run.py: serve_application()函数中
(1). 建立connector,对外提供访问接口
在rasa shell中指定connector为 cmdline,这样用户就可以通过命令行与rasa进行交互。如果不在命令行而在其他客户端进行交互的话,我们就需要在credentials中配置新的connector。比如自己建造的网站、微信或者嵌入在一些软件上等等,而载入connector的函数代码在create_http_input_channels()中。
if not channel and not credentials:channel = "cmdline"# 第一步:将channel指定为cmdline# 正在连接到由“--connector”参数指定的通道“cmdline”。任何其他通道都将被忽略。要连接到所有给定的通道,请省略 '--connector' 参数。input_channels = create_http_input_channels(channel, credentials)
(2). 从磁盘载入模型:rasa/core/agent.py
从源码中可以看出有三种不同的方式加载已训练的模型:
1、从云存储(如 S3)获取模型
2、从自己的 HTTP 服务器获取模型
3、从本地磁盘加载模型
默认情况下,Rasa 的 CLI 的所有命令都将从本地磁盘加载模型。具体信息可以参考Rasa官方文档。2
try:if model_server is not None:return await load_from_server(agent, model_server)elif remote_storage is not None:agent.load_model_from_remote_storage(model_path)elif model_path is not None and os.path.exists(model_path):try:agent.load_model(model_path)except ModelNotFound:rasa.shared.utils.io.raise_warning(f"No valid model found at {model_path}!")else:rasa.shared.utils.io.raise_warning("No valid configuration given to load agent. ""Agent loaded with no model!")return agent
(3). 处理用户消息
首先要说一下在rasa/core/agent.py里有一个重要的Agent类,它是rasa里的重要接口,包含了加载模型、处理消息等的重要功能。我们在实例化Agent的时候会同时实例化它的处理器processor,processor是与机器人的通信的接口。在这个过程中,processor会从磁盘中加载模型并还原成推理所用的有向无环图。核心代码在rasa/core/processor.py的load_predict_graph_runner()函数中。
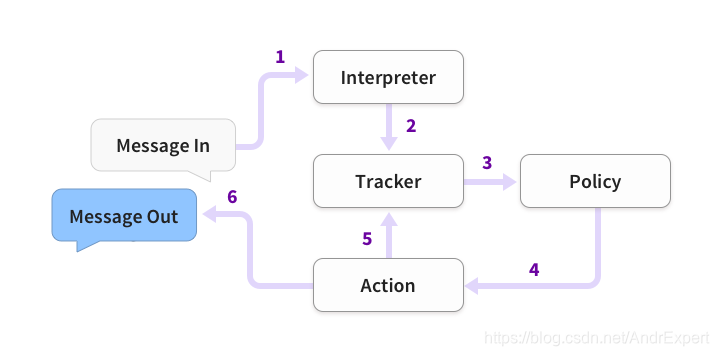
当用户通过客户端向指定的connector发送消息到rasa服务器(实际上,connector应该是rasa服务器的 接口),然后rasa服务器就会处理用户消息返回响应消息到客户端。从逻辑上讲,这个处理过程应该是先由Rasa NLU解析消息传递到Rasa Core来决定合适的动作执行。核心代码是processor中定义的hand_message()方法。
async def handle_message(self, message: UserMessage) -> Optional[List[Dict[Text, Any]]]:"""Handle a single message with this processor."""# 处理UserMessage类返回的用户消息# 对用户消息作NLU的预处理# log_message:运行推理的有向无环图,得到NLU的结果# 这些NLU的结果会更新tracker的状态tracker = await self.log_message(message, should_save_tracker=False)# 如果是执行rasa shell nluif self.model_metadata.training_type == TrainingType.NLU:await self.save_tracker(tracker)rasa.shared.utils.io.raise_warning("No core model. Skipping action prediction and execution.",docs=DOCS_URL_POLICIES,)return None# 如果是执行rasa shell# run_action_extract_slots:根据slot 的配置映射更新tracker的状态tracker = await self.run_action_extract_slots(message.output_channel, tracker)# 把tracker的状态作为输入,通过有向无环图推理得到新的tracker,得到目的tracker状态# 并根据目的tracker状态执行动作,但是执行动作可能会带来新的tracker状态# 重复过程,直到满足条件await self._run_prediction_loop(message.output_channel, tracker)# 保存tracker状态# 这个tracker的状态决定了bot是选择继续倾听还是继续执行动作await self.save_tracker(tracker)if isinstance(message.output_channel, CollectingOutputChannel):return message.output_channel.messagesreturn None
从源码中读到,在用户消息经过UserMessage类的处理后传入handle_message()中,首先经过log_message()方法的处理。这个方法实际上就是Rasa NLU在工作,先根据“sender_id”来获得当前会话的tracker,再根据tracker得到用户消息来进行NLU解析,并按需求保存tracker。
async def log_message(self, message: UserMessage, should_save_tracker: bool = True) -> DialogueStateTracker:"""Log `message` on tracker belonging to the message's conversation_id.在属于该消息的对话ID的tracker上记录消息Optionally save the tracker if `should_save_tracker` is `True`. Tracker savingcan be skipped if the tracker returned by this method is used for furtherprocessing and saved at a later stage.如果'should_save_tracker'为'True',则可以选择保存跟踪器。如果此方法返回的跟踪器用于其他用途,则可以跳过跟踪器保存处理并在稍后阶段保存"""# 得到当前会话的trackertracker = await self.fetch_tracker_and_update_session(message.sender_id, message.output_channel, message.metadata)await self._handle_message_with_tracker(message, tracker)# 是否保存trackerif should_save_tracker:await self.save_tracker(tracker)return tracker
然后执行run_action_extract_slots()和_run_prediction_loop()方法。
前者从tracker中获取解析过的用户消息来填充slots,填充slots的时候,slots会将消息中的实体映射成需要的实体,并更新tracker的值(关于slots的具体内容可以参考Rasa官方文档 3)。比如用户询问“今天长沙的天气如何?”,这里通过NLU解析可以提取出“今天”,“长沙”的实体值,然后该函数会通过slots的配置将提取到的实体值映射到如“datetime”,“address”的词槽,只有满足了这两个词槽,Rasa才能执行查询天气的动作。
后者将这个tracker作为有向无环图的输入,预测下一步执行的动作并执行这一动作,但是这个过程中可能会重复并带来新的tracker状态,直到满足停止条件。最后保存tracker,并倾听等待下一用户消息。
# run_action_extract_slots:根据slot 的配置映射更新tracker的状态tracker = await self.run_action_extract_slots(message.output_channel, tracker)# 把tracker的状态作为输入,通过有向无环图推理得到新的tracker,得到目的tracker状态# 并根据目的tracker状态执行动作,但是执行动作可能会带来新的tracker状态# 重复过程,直到满足条件await self._run_prediction_loop(message.output_channel, tracker)# 保存tracker状态await self.save_tracker(tracker)
四、思维导图
事实上,在Rasa3中NLU和Core的界限不在清晰,但是为了理解,我仍然画成了两个部分。

五、 结语
事实上,本文只是从宏观层面解析了模型训练和用户消息传入Rasa服务器的处理过程,具体细节仍未展开剖析,一些东西也是点到为止。接下来的时间我会从NLU和Core的处理过程展开研究,同时记录思路过程,也请阅者批评斧正。
RasaX版本适配图表 ↩︎
Rasa官方文档之模型存储 ↩︎
Rasa官方文档之slots ↩︎