随着系统规模的不断增加,数据量和并发量不断增大,整个系统架构中最先受到冲击而形成瓶颈的,定然是数据库,因此数据库层面的优化,是一个程序员不可或缺的技能,以下是我在使用数据库中的一些心得,有不足之处,还望批评指正完善。
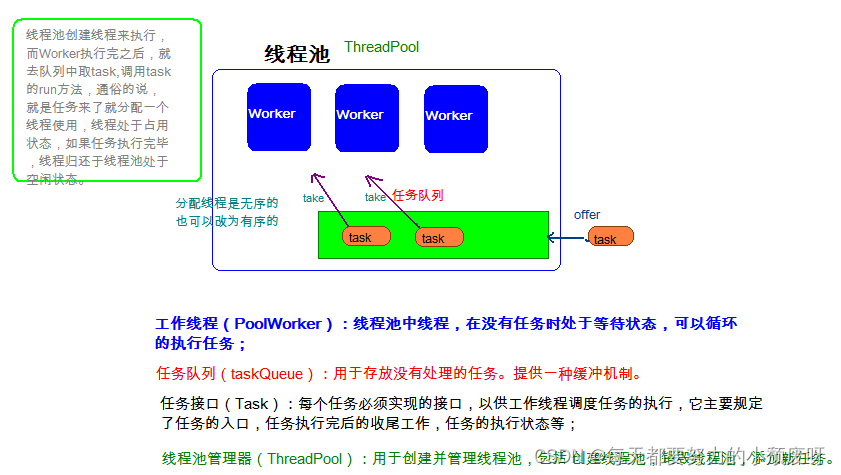
首先简单介绍下sql执行的过程,如下图

当你在sql客户端(如命令行或者navicat)提交一条sql后,sql解析引擎会被启动,此时,sql引擎会去解析优化这条sql,比如有时候你发现你写的sql 查询条件中的数据类型虽然和数据库表定义的数据类型不一致,但是还是能够得到正确的执 行,是因为数据库引擎帮你做了自动转化,比如
select * from user where telephone=13937147647 telephone为varchar类型
虽然类型不一致,但是sql会得到正确执行,是因为数据库引擎帮你做了自动类型转化
不仅如此,数据库表定义了多个索引,你写的sql可能都会命中,sql引擎会帮你选择最优的一个,这些都是此阶段完成的
接下来,数据库引擎会拿着优化好的sql命令语义去硬盘中查找数据,然后将查找到的数据返回(如果此时返回的结果集过大,会造成数据库IO繁忙,会大大损伤sql效率,所以一般我们都使用分页的原因就在于此)
我们熟悉了sql执行过程之后,开始了解各种优化方式吧:
1、索引,建立索引是数据库优化各种方案之中成本最低,见效最快的解决方案,一般来讲,数据库规模在几十万和几百万级别的时候见效最快,即便是有不太复杂的表关联,也能大幅度提高sql的运行效率,这个在我们以前的项目应用中,有非常深刻的体会,本来耗时50s的sql,在增加索引后可以提升到1-2s,而且不需要有代码改动,成本低廉,见效明显
建立索引需要注意的地方
a、索引一般加在查询条件的关键字上,如果有多个查询条件关键字,还可以添加组合索引,写sql的时候需要注意,索引字段和sql字段需要保持一致,否则索引会无效,比如
简单粗暴一点儿,我直接使用我们主数据数据库(测试库)中的md_house_property_info表中的source_house_code_no字段,这个字段在数据库中被定义为了varchar类型,定义了多个索引,都包含了source_house_code_no字段

大家看,source_house_code_no我写成varchar类型的时候,是可以走索引的

当我写成数字的时候,sql能够正确执行,但是却没有命中索引
大家再细心一点儿会发现,我这里面有个possiable_keys,这个是指的可能命中的索引,此处出现了两个,但是数据库引擎会选择最优的一个idx_source_house_code_no,这个过程我在开始有介绍了
b、不要在查询=前面使用函数,否则会导致索引不生效,举个栗子,where str=substring(“hello world”,6,8),这样是可以走索引的,但是 where substring(str,6,8)=“hello world” 是不会命中索引的
c、建立索引的字段要区分度比较高,比如user表中有一个性别字段,性别字段无非男女两种值,区分度不好,建立索引效果不好,要选择区分度高的字段
d、建立组合索引,可以持续提升sql运行效率,但是也不要盲目,同样的要注意区分度,如果区分度不够高,就不要加了,多个字段,尽可能把区分度高的字段放在前面,另外,还要注意索引长度,这个索引要同时兼顾索引长度和区分度的平衡
e、索引会大幅提升查询效率,但是也会损耗查询后修改效率,要注意兼顾平衡,使用在一次插入,多次查询的表上效果最好,同时要注意的是,组合索引会不可避免的增加索引长度,会增加索引存储空间,注意索引长度和区分度平衡
f、后来因为工作需要,意外发现mysql居然支持全文索引,没测试过效率,正常使用全文索引都是使用 lunce,以及在其之上的solr和现在正火的elastisearch,后面可以单独来说
2、分库分表分区
分库,可以按照业务分库,分流数据库并发压力,使数据库表更加有条理性,最起码更加好找吧,我们当时是把查询库和系统库(增删改比较频繁的表)分开了,这样如果有大查询,不影响系统库
分表,刚才说了,索引适合应对百万级别的数据量,千万级别数据量使用的好,勉强也能凑合,但如果是上亿级别的数据量,索引就无能为力了,因为单索引文件可能就已经上百兆或者更多了,那么,轮到我们的分表分区登场了
分表的方法有很多种
a、如果这个业务是有流程的,那么我们通常会设计一个历史表或者归档表,用来存放历史数据,这样能保证实时数据效率比较高
b、针对某一张大表,可以根据查询条件分成多张表,比如时间,我们可以将半个月或者10天的数据放到一张表里(看具体数据量,个人认为3000W是个上限,最好控制到百万级别),每过10天,我们就自动创建一张数据库表,然后将数据插入,如此,按照时间查询,就要先定位去那种表中去取数,这样,效率能够得到大幅度提升,当然,这么解决也有问题,比如跨表,需要union多张表,而且跨表没法支持索引
c、上面的方法是我们直接通过程序和数据库实现的最原始的分表解决方案,现在市面上有一些成熟的软件如mycat,也是支持分表的,我们之前从事的公司有个专门做分布式数据库的,这些产品出现跨表,可以不使用程序union了,而且还是使索引生效,但是需要对产品有一定的掌握
d、一般来讲,数据库中的大表毕竟只是一少部分,仅需要对这少部分大表进行分表就可以了,没必要小表也进行分表,增加维护开发难度
分区
分区的实现道理和分表一样,也是将相应规则的数据放在一起,唯一不同的是分区你只需要设定好分区规则,插入的数据会被自动插入到指定的区里,当然查询的时候也能很快查询到需要区,相当于是分表对外透明了,出现跨表数据库自动帮我们合并做了处理,使用起来比分表更加方便,但是分区也有自己的问题,每一个数据库表的并发访问是有上限的,也就是说,分表能够抗高并发,而分区不能,如何选择,要考虑实际情况
3、数据库引擎
也是偶尔听一个dba同事提到的,有一次我跟dba同事抱怨,我的数据库查询太慢,有没有好的优化方法,他一开始就问,数据量多大,有没有索引,使用的什么数据库引擎,这时我才意识到原来数据库引擎也算是一种优化方案
mysql比较常用的数据库引擎有两种,一种是innodb、一种是myisam
我当时做过一个千万级数据量复杂sql测试,myisam的效率大概能够比innodb快1-2倍,虽然效率提升不是很明显,但是也有提升,后来查过一些资料,说之所以mysiam快,是因为他的数据存储结构、索引存储结构和innodb不一样的,mysiam的索引结构是在内存中存的
当然,mysiam也有弱点,那就是他是表级锁,而innodb是行级锁,所以,mysiam适用于一次插入,多次查询的表,或者是读写分离中的读库中的表,而对于修改插入删除操作比较频繁的表,就很不合适了
4、预处理
一般来说,实时数据(当天的数据)还是比较有限的,真正数据量比较大的是历史数据,基于大表历史数据的查询,如果再涉及一些大表关联,这种sql是非常难以优化的
a、实时数据(当天数据)
通过对对业务的抽象,可以放在缓存里面,提升系统运行效率
b、历史数据,大数据表历史数据且有表关联,通过常规sql难以优化,但是该数据通常有个共性,就是第二天去查询前一天的数据做分析报表,也就是说对时效性要求不高,这种情况的解决方案是预处理
做法是将这些复杂表关联sql写成个定时任务在半夜执行,将执行的结果存入到一张结果表中,第二天直接查询结果表,如此,效率能得到十分明显提升
c、和b类似,可以将表关联结果存入solr或者elastisearch中,以此提升效率,目前我们的项目就是如此处理
5、mysql like查询
大家都知道,like “%str%” 不支持索引, "str%"号是支持索引的
因此,如果业务允许,可以使用前匹配的方法是数据库快速定位到数据,在结果集中再进行like匹配,如果这个结果集不是很大,是可以大幅提升运行效率的,这个需要对业务和程序有灵活的变通
如果业务实在不允许前匹配,那就可以采用solr或者elastisearch来进行模糊匹配,但是进行模糊匹配有个前提,原始数据是字符串的话,不要带有特殊符号,如#,&,% 等,这样会造成分词不准,最终导致查询结果不正确
6、读写分离
在数据库并发大的情况下,最好的做法就是进行横向扩展,增加机器,以提升抗并发能力,而且还兼有数据备份功能