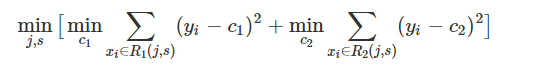一、模型训练过程
贪心优化算法。多颗决策树串行训练,第一棵树拟合训练目标、第二颗树拟合前面的残差、第三棵树拟合前两棵树留下的残差。
1、残差来源:
(1)第k颗树训练时,行采样+列采样(即仅有部分样本、部分特征进入树中进行训练)进入树,决策树按照最大信息增益原则选择分裂特征、分裂点进行分裂;
(2)最终分裂完成之后,每个叶子节点上的分数由该叶子上的所有样本Y标签分布决定,如某叶子节点上正负样本比例:5:1,则该叶子节点分数为0.2(回归问题时为y均值,二分类时也为y均值/bad_rate);
(3)训练完成后,用前k颗树预测所有样本得到y^,y-y^即为前k颗树留下的残差(即第k+1棵树的训练目标,此处假设学习速率为1)
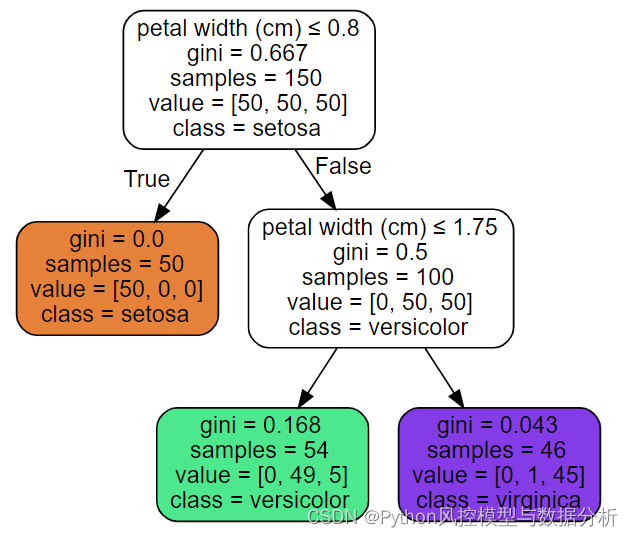
上图中,落到绿色子节点的样本预测概率【0,49/54,5/54】,即属于第一类的概率为0、第二类的概率为49/54、第二类的概率为5/54
2、学习速率/步长
用来指定每棵树的学习步长,在1.中得到了下一颗树的训练目标(残差),以残差为目标在进行完一次迭代后/每训练完一棵树,会将叶子节点的分数*学习速率,主要是为了削弱每棵树的影响,让后面有更大的学习空间、实现小步迭代的思路。注:默认情况下学习速率0.2
二、模型预测过程
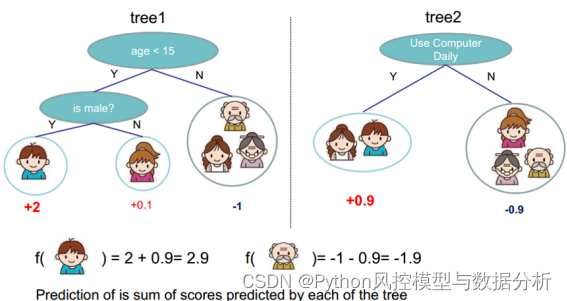
每棵树的预测结果相加得到最终的预测结果
三、目标函数:损失函数 + 正则项

·目标函数:模型训练的优化目标
·损失函数:用来衡量模型的预测效果
(1)对于回归问题,常用的损失函数是MSE

(2)对于分类问题,常用的损失函数是对数损失函数

·正则项:用于控制复杂程度 (alpha为L1正则项参数,lambda为L2正则项参数)
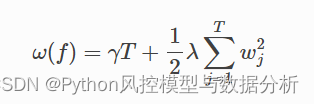
(1)T表示叶子结点的个数,w表示叶子节点的分数向量,γ可以控制叶子结点的个数,λ可以控制叶子节点的分数不会过大,防止过拟合。
(2)叶子节点越多、模型越复杂、w的平方越大

四、XGB与GBDT的区别
1、泰勒二阶展开:GBDT只将目标函数泰勒展开到一阶,而xgboost对代价函数进行了二阶泰勒展开来近似模拟正式的损失函数、方便求解,支持自定义损失函数,只要函数可一阶和二阶求导。
2、加入正则项:xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合。
3、增加自动处理缺失值:
(1) 训练时,若特征m存在空值,当树按照特征m分裂时,先不考虑空值、按照m有值的序列选择最优分裂点进行分裂,然后再分别将空值样本带入左子节点和右子节点,计算两侧信息增益,保留整体信息增益较大的分裂方向,预测时空值样本也按照该方向进行分裂;
(2)训练时特征无空值,预测时空值样本默认分裂到左侧子节点
4、支持并行、多线程:xgboost的并行不是tree粒度的并行,而是在特征粒度上的,各个特征的增益计算就可以开多线程进行。
5、支持列抽样:xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算。
6、传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
五、重要参数
params={'objective':'binary:logistic','eval_metric':'auc','booster': 'gbtree', #树模型'silent': 1, #是否打印'eta':0.3, #学习速率'num_boost_round': 100, #迭代次数'gamma':0, # 节点分裂所需的最先损失下降(惩罚项)'max_depth': 6, #树分裂最大深度,'min_child_weight' :100, #最小叶子节点样本权重和,调大减小过拟合,过高会欠拟合'subsample' : 1, #行采样'colsample_bytree' : 1, #列采样,单颗树进行列采样'colsample_bylevel' : 1, #列采样,子树的每层进行列采样'seed': 0, #随机种子,固定行、列采样'lambda':1, #权重的L1正则化项 'alpha': 0, #权重的L2正则化项'scale_pos_weight': 1, #调节样本平衡度'max_delta_step': 0, #限制每棵树权重改变的最大步长'nthread':None #最大可用线程数
}六、过拟合调参
模型的评估审核时一般都会有针对过拟合问题的要求:如要求train、test的auc相差小于0.03或train、test的ks相差小于0.04等;而在一些场景下训练的模型很容易过拟合,train、test的auc、ks相差较大,这种情况下我们不得不调整参数,有必要在损失一些模型精度的情况下来避免过拟合。
调小max_depth (3,6,1)
调大min_child_weight (100,2000,100)
调大gamma (0,10,2)
调大 lambda
eta、num_round 调高eta,降低num_round, eta(0.01,0.2,0.02),num_round(50,1000,100)
调低subsample & colsample_bytree (0.6,1,0.1)