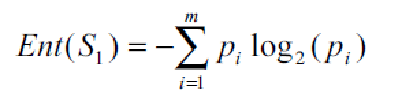数据仓库世界里面的massively parallel processing 大概定义:
MPP 是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
- 首先MPP 必须消除手工切分数据的工作量。 这是MySQL 在互联网应用中的主要局限性。
另外MPP 的切分必须在任何时候都是平均的 , 不然某些节点处理的时间就明显多于另外一些节点。
对于工作负载是不是要平均分布有同种和异种之分,同种就是所有节点在数据装载的时候都同时转载,异种就是可以指定部分节点专门用来装载数据(逻辑上的不 是物理上) , 而其他所有节点用来负责查询。 Aster Data 和Greenplum 都属于这种。 两者之间并没有明显的优势科研,同种的工作负载情况下,需要软件提供商保证所有节点的负载是平衡的。 而异种的工作负载可以在你觉得数据装载很慢的情况下手工指定更多节点装载数据 。 区别其实就是自动化和手工控制,看个人喜好而已。
另外一个问题是查询如何被初始化的。 比如要查询销售最好的10件商品,每个节点都要先计算出自己的最好的10件商品,然后向上汇总,汇总的过程,肯定有些节点做的工作比其他节点要多。
上面只是一个简单的单表查询,如果是两个表的连接查询,可能还会涉及到节点之间计算的中间过程如何传递的问题。 是将大表和小表都平均分布,然后节点计算的时候将得到的结果汇总(可能要两次汇总),还是将大表平均分布,小表的数据传输给每个节点,这样汇总就只需要一 次。 (其中一个特例可以参考后面给出的Oracle Partition Wise Join) 。 两种执行计划很难说谁好谁坏,数据量的大小可能会产生不同的影响。 有些特定的厂商专门对这种执行计划做过了优化的,比如EMC Greenplum 和 HP Vertica 。 这其中涉及到很多取舍问题,比如数据分布模式,数据重新分布的成本,中间交换数据的网卡速度,储存介质读写的速度和数据量大小(计算过程一般都会用临时表 储存中间过程)。
一般在设计MPP 数据仓库的时候都会有一个指导原则用来得到比较好的性能,比如数据如何分布,customer 一般按照hash 分布比较好,而sales_order 一般按照时间分布。所以一般建议在选型做POC 的时候,针对你自己需要的典型查询模式和负载进行测试。 一般优化的时候会考虑如下问题:
查询如何初始化?
是否有足够的节点用来处理查询?
同样的,数据装载的时候是否有足够节点用来装载数据 ?
数据装载如何影响查询的 ?一些列数据库数据装载的时候一般不适合处理查询。
数据该复制多少份?把常用的数据分布在更多的节点上显然会减少数据移动的影响
一般用来做高可用的数据能用在查询上嘛?
- 有什么工具能查看查询的执行计划吗?这些功能能帮助你定位性能瓶颈.
在开始使用MPP 的时候你至少应该明白几件事:
不同的数据分布策略到底如何影响
不同的工作负载模式如何影响你的设计
Share Everthing 和 Share Nothing
数据仓库里面share everything 的代表是Oracle 的Exadata 。 Sybase 也从oracle 引入了rac 的套件,但是Sybase 本身没有硬件,所有架构上还是跟Exadata 有很大区别。 就跟普通所说的RAC 和 Exadata 的在架构上的区别一样。
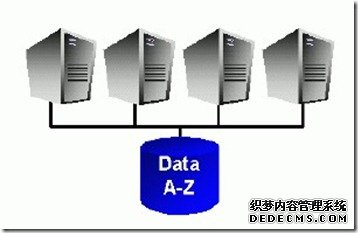
Exadata 是用一个储存阵列来存放数据的,跟Oracle 10g 里面ASM Disk + Disk 是完全不同的。
share nothing 的架构在数据仓库里面更多, Teradata,IBM Netezza , Vertica,Greenplum, Aster Data 基本都是。
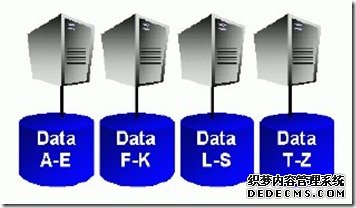
这个是比较传统的share nothing 架构, Sybase IQ , Vertica , Greenplum Community , Aster Data 基本都是这种,纯软件上实现的share nothing, 里面Disk 跟Disk 之间是分开的,Node 跟Node 之间就是纯的物理上的服务器。
Teradata ,IBM Netazza ,将来可能出现的EMC Greenplum + 硬件(现在的Greenplum DCA不是 ) ,HP Vertica + 硬件 架构图是这样的:
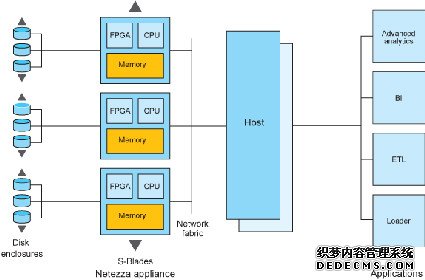
(IBM Netazza Architecture)
里面的磁盘阵列是磁盘阵列,互相之间是可以转移数据的, 前面讲的几个(Sybase IQ) 这种Disk 跟Disk 之间是不能传数据的,要交换数据必须通过计算层面发送内部消息。
他们之间最大的区别就是在执行计划里面数据重分布会非常不一样,具体这个后面我写Exadata vs Netezza 会详细说。 大家也可以参考最下面参考资料给出的连接
MPP 厂商纯软件和软件加硬件的share nothing 架构区别
纯软件的MPP 理论上的伸缩性可能可以到比较高的级别,但是数据越大可能执行某些SQL 就没有在比较小数据量的时候优秀了。 大概的梯度在1P 跟200TB 左右吧。
各数据仓库MPP 的实现
Microsoft 没有mpp , 他的集群甚至都不是线性伸缩的(坑爹啊), 但是他08 年就收购了在Linux+Ingres 上做MPP 的DATAllegro , 但是新版还没出来。
Sybase IQ 最新版15.3 做出来MPP , 时间是今年7月份才发布,Sybase IQ 本身是共享磁盘,但是它跟RAC 的区别是它不共享节点的计算资源。
Vertica , Greenplum , Aster Data 的MPP 都是纯软件的share nothing 并且不共享磁盘的, 数据移动和重分布完全是靠计算机集群完成。
Teradata , IBM Netezza 以及将来可能出现的HP Vertica +硬件, Greenplum + EMC 硬件 , Aster Data + Teradata 硬件都是完全的share nothing , 他们共享的是磁盘阵列, 但是部分数据传输和重分布是靠磁盘阵列完成。
参考资料
节点计算中的数据分配和重新分配问题:Oracle Partition Wise Joiin
数据库 MPP 的秘密
Oracle Exadata
InfoBright 的MPP 实现