一、数据库 vs. 数据仓库
1. 构建目的不同:数据库主要用于实现企业的日常业务管理,提高业务运营的效率
数据仓库用于将多个数据源的数据进行集成,用于分析,结果辅助决策
2. 管理数据不同:数据库通常只包含当前数据,避免冗余,数据的组织应按照业务过程设计的数据实现,由应用驱动
数据仓库中的数据按主题组织,以便分析;为方便查找存在大量冗余,通常存放历史数据
3. 管理方法不同:数据库需频繁进行增删改等更新操作。除了要通过创建事务和处理的正确性外,还需复杂的并发控制机制保证事务运行的隔离性。(更新操作时效性强,事务吞吐率很重要)
数据仓库很少更新,无需复杂并发控制机制,时效性不重要,数据质量重要
二、 数据仓库(Date Warehouse) vs. 数据集市(Data Market)
数据仓库是一个面向主题的、集成的、随时间变化的、稳定的用于支持组织决策的数据集合。
数据集市是部门级的数据仓库,包含数据量较少,是面向一个部门的分析需求建立的
三、数据仓库体系结构

1. 抽取:从不同数据源把所需数据读出来
① 逻辑抽取:a. 全量抽取 b. 增量抽取
② 物理抽取(依赖逻辑抽取):a. 联机抽取:直接从源系统抽取;b. 脱机抽取:从源系统以为的过渡区抽取
2. 转换:主要涉及数据清洗、集成、汇总等主要功能
① 数据清洗:缺失值填补、识别数据冗余、处理不一致数据、识别噪音数据
② 集成:需解决命名实体的识别,及从不同数据源抽取数据的组合
3. 加载:① 数据仓库建成之初,需将数据大批量一次性导入
② 数据仓库正常运作后,需将操作型系统数据定期更新到数据仓库
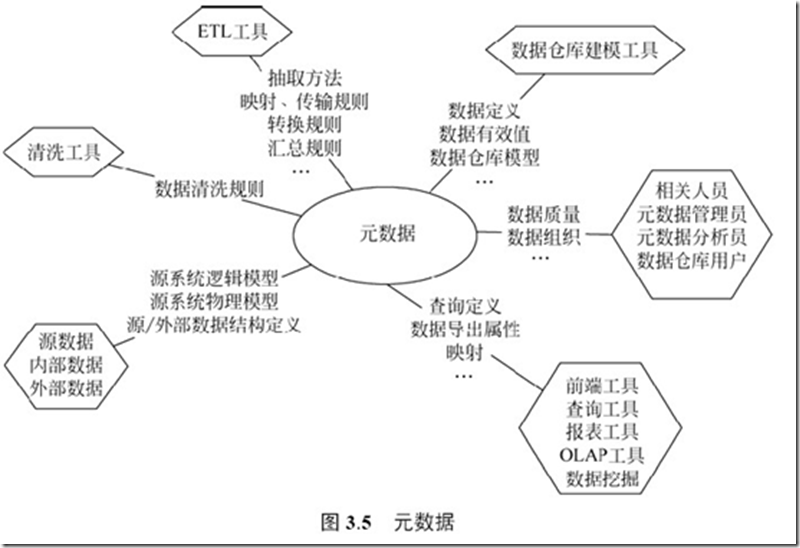
元数据:对数据仓库中数据的描述信息。主要包括数据源数据信息(格式、属性名、类型、长度等)、数据抽取与转换方面的信息(数据抽取频率、抽取方法、转换方法)、数仓中的数据信息(描述面向用户的数据的特性,如每个属性的别名、最后更新时间)
四、多维数据模型
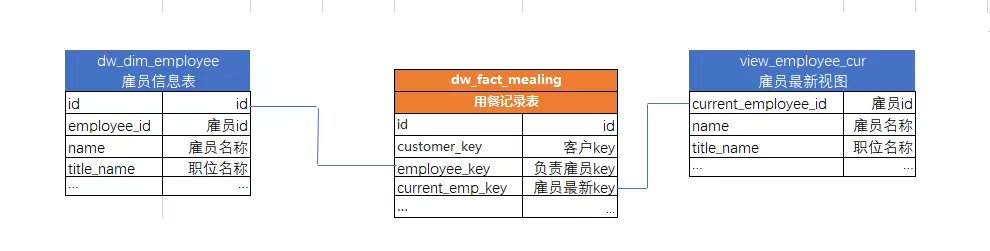
1. 维度表:存放详细维度信息(通常属性很多,属性名不缩写,允许一定冗余)
事实表 = 维度 + 度量(度量分为可加性、半可加性和不具有可加性)
事实表分类:事务事实表、周期快照事实表(以有规律性的、可预见的时间间隔,年/月/日)、累计快照事实表(记录不确定的周期的数据)
2. 星座模型:一个事实表,若干维度表与事实表相连。
优:简单,易于理解,查询方便;缺:有些维度非规范化
3. 雪花模式: 一个维度对应多个表
4. 事实星座:不同事实表共享维度表
五、多维数据模型构建方法
1. 选择业务过程或主题(选择标准:a.亟待解决的问题,解决有助于提升业务质量;b.业务积累了一定数据,可作为数据仓库的数据来源)
2. 选择粒度(交易事实表 or 周期快照事实表 or 累计快照事实表)
3. 确定维度
4. 确定度量
六、数据仓库开发模式
1. 自顶向下:先构建企业数据仓库,根据各个业务过程的需求分析,将数据仓库中的数据调到数据集市中进行分析
优点:从企业整体出发,对数据进行有效集成,避免冗余,提供统一的数据访问
缺点:由于涉及范围广,所花时间、人力、财力较多,风险更高,短期难看到效果
2. 自底向上:根据各个业务需求分析,按紧迫程度先后建立数据集市,再将数据集市集成为数据仓库
优点:从单个业务出发,快速构建数据集市,很快看到效果,成功率高,花费少,风险低
缺点:没有纵观全局的考虑,易导致数据集市数据不一致、冗余
3. 折中:在前期需求分析时从企业整体出发,构建基于全局的数据仓库体系结构,统一定义数据格式、类型、语义。根据需求及业务对企业的重要程度,依次构建数据集市,通过几个数据集市的构建逐步涵盖企业整体范围内的数据,构成数据仓库
七、 数据仓库开发过程
1. 项目规划:了解总体需求,界定项目实施范围,评估必要性、可行性,撰写规划文档
2. 需求分析:确定分析主题、相关维度和度量,确定包含的数据及来源
3. 概念设计:用概念模型描述数据仓库包含的主题及其关系
信息包图:度量、维度、层次(每个维度属性间的层次关系,如年、月、日)
4. ETL设计:① 抽取:抽取接口、策略设计(抽取时机、周期、方式)增量抽取 or 完全抽取
② 转换:转换方式和时机(抽取过程中转换 or 加载过程中转换)
③ 加载:策略(直接追加 or 覆盖)
5. 逻辑和物理设计:① 逻辑模型——多维数据模型
② 物理模型:存储结构:RAID
索引技术:B+树索引、位图索引、广义索引
八、数据仓库分层
1. 分层的好处:
① 分层是一种空间换时间的操作:分层是对原始数据重新归纳整理,在不同层级对数据或指标做不同粒度的抽象。大大降低sql计算的耗时
② 分层有利于减少重复开发:分层把大部分常用的、通用的数据模型和指标进行抽象和汇总,可以满足大部分业务场景使用的数据表和指标。类似于API,下游使用方可以直接拿来使用,不仅减少重复开发还做到了数据和指标的统一
③ 复杂问题简单化:把通用数据和指标进行归类和预计算;把join和union这些复杂的操作拆解放在数仓的ETL中来处理。每层只处理单一问题
④ 数据安全:每层表的宽度和指标的粒度都不同,可以针对不同适用对象开放不同层级的数据.
⑤ 数据血缘追踪:如果有一张来源表出了问题,借助血缘能够快速准确定位到问题,并清除危害范围
2. 分层模型
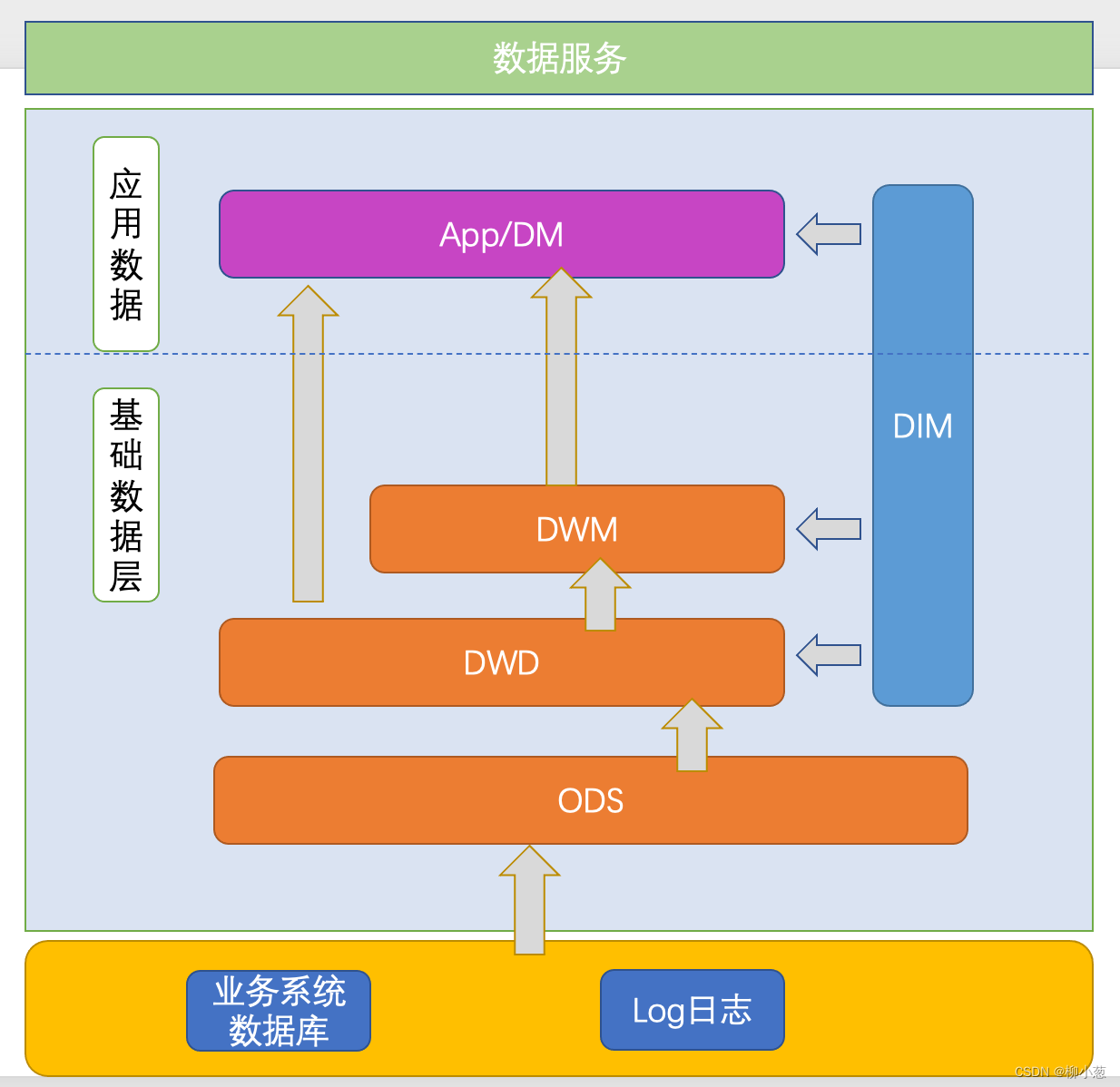
① 数据操作层 ODS(Operation date store):数据仓库源头系统的数据表原封不同的存储一份,在同步过程中不做任何处理,保证与元数据一致。是后续加工数据的来源(业务数据、日志数据、第三方数据)
② 数据明细层 DWD(Data warehouse detail):与原表保持同一粒度的基础上根据业务对ODS数据进行去除脏数据,按照业务过程对表进行归类和关联,经过构建事实表。(不进行聚合,只是表变宽)
③ 数据服务层 DWS(Data Warehouse service):基于DWD数据整合汇总称分析某一个主题域的服务数据。通常把DWD中的事实表的key和DIM中的维度key关联,对事实表按照更高的维度进行上卷的聚合操作,得到在某一维度或多个维度上的汇总数据或指标(粒度发生变化)
④ 维度数据层 DIM(Dimention):与DWD平行,是对业务中常用维度的建模和抽象。这一层通常储存的是完整的维度key和维度名称,而事实表中通常存储的是维度key的字段
⑤ 应用数据层/数据服务层 ADS(Application data service):基于DWD/DWS层数据,或二者的计算,是面向具体应用的较高纬度的数据指标的聚合汇总
九、OLAP
针对特定问题的在线数据访问和分析,通过对信息的多种可能的观察形式进行快速存取,允许管理决策人员对数据进行深入的、多方面的探查。
1.物化:将计算好的立方体数据存放于物理存储设备中,可以提高响应速度
① 不物化策略:用户提出请求后进行聚集运算,响应速度慢
② 完全物化:将所有可能的聚集运算都预先计算好并保存,用户请求时直接读取答案并发送
③ 部分物化:折中,选择一部分立方体预先计算和存储
2. 多维数据分析:切片、切块、上卷、下钻、旋转
数据仓库介绍与建模方法
数据仓库介绍与建模方法 - 知乎 (zhihu.com)
数仓分层 浅谈数仓建设中的分层 (baidu.com)