推荐系统(十八)Gate网络(一):新浪微博GateNet
推荐系统系列博客:
- 推荐系统(一)推荐系统整体概览
- 推荐系统(二)GBDT+LR模型
- 推荐系统(三)Factorization Machines(FM)
- 推荐系统(四)Field-aware Factorization Machines(FFM)
- 推荐系统(五)wide&deep
- 推荐系统(六)Deep & Cross Network(DCN)
- 推荐系统(七)xDeepFM模型
- 推荐系统(八)FNN模型(FM+MLP=FNN)
- 推荐系统(九)PNN模型(Product-based Neural Networks)
- 推荐系统(十)DeepFM模型
- 推荐系统(十一)阿里深度兴趣网络(一):DIN模型(Deep Interest Network)
- 推荐系统(十二)阿里深度兴趣网络(二):DIEN模型(Deep Interest Evolution Network)
- 推荐系统(十三)阿里深度兴趣网络(三):DSIN模型(Deep Session Interest Network)
- 推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
- 推荐系统(十五)多任务学习:谷歌MMoE(Multi-gate Mixture-of-Experts )
- 推荐系统(十六)多任务学习:腾讯PLE模型(Progressive Layered Extraction model)
- 推荐系统(十七)双塔模型:微软DSSM模型(Deep Structured Semantic Models)
CTR预估模型在学术界/工业界进化的路线有明显的几个节点:1. 从单特征到交叉特征,围绕着如何学到更有用的交叉特征,诞生了一系列的模型。2. attention火起来后,被迅速应用到CTR预估领域中,又有很多模型被提出。3. gate网络火起来后,同样也催生了一些模型。但话说,我其实一直没太搞明白『attention』和『gate』本质上的区别是什么?有路过的大佬可以评论区帮忙解答下。
言归正传,这篇博客将要介绍新浪微博张俊林大佬团队提出的GateNet模型,这篇文章我只在arxiv上找到了,并没有找到公布发表的会议版本,应该是还没投。整篇文章看起来比较简短,因为Gate网络实在没什么好讲的,所以文章大量的笔墨都在实证研究上了,不过遗憾的是,数据集都是用的公开的数据集,没有看到在新浪微博自己的数据集上的实验效果。
本篇博客将会从两个方面介绍下GateNet:
- GateNet网络类型
1.1. embedding层Gate(Feature Embedding Gate)
1.2. 隐藏层Gate(Hidden Gate) - GateNet论文实验结论
- 自己实践中一些结论
一、GateNet网络类型
这篇论文中依据Gate网络施加位置的不同,分为了两种类型:embedding层Gate(Feature Embedding Gate)和 隐藏层Gate(Hidden Gate)。下面来分别介绍一下:
1.1、embedding层Gate(Feature Embedding Gate)
顾名思义,embedding层Gate就是把Gate网络施加在embedding层,具体又可以分为两种:bit-wise和vector-wise。bit-wise就是每一个特征的embedding向量的每一个元素(bit)都会有一个对应的Gate参数,而vector-wise则是一个embedding向量只有一个Gate参数。假设样本有两个特征,每个特征embedding维度取3,用个图来形象的对比下bit-wise和vector-wise的gate的区别:


值得一提的是,论文中关于gate网络参数是否共享提出了两个概念:
- field private: 所谓field private就是每个特征都有自己的一个gate(这意味着gate数量等于特征个数),这些gate之间参数不共享,都是独立的。图1、图2中gate的方式就是这种。
- field sharing: 与field private相反,不同特征共享一个gate,只需要一个gate即可。优点就是参数大大减少,缺点也是因为参数大大减少了,性能不如field private。
通过论文中给出的实验表明,field private方式的模型效果要好于field sharing方式。
下面通过形式化的公式来看下embedding层Gate的流程(尽管我觉得上面两个图已经非常清晰的展示了细节,但配合公式来一波强化记忆吧),假设有 n n n个特征,每个特征的embedding维度为 d d d,则 E = [ e 1 , e 2 , . . . , e n ] E=[e_1, e_2, ..., e_n] E=[e1,e2,...,en], e i e_i ei为特征 i i i对应的embedding向量, e i ∈ R d e_i \in R^d ei∈Rd,下面为整个计算步骤:
第一步:计算gate value: g i = σ ( W i ⋅ e i ) g_i=\sigma(W_i \cdot e_i) gi=σ(Wi⋅ei),如果是bit-wise方式,则 W i ∈ R d W_i \in R^d Wi∈Rd, W ∈ R d × d W \in R^{d \times d} W∈Rd×d是一个矩阵;如果vector-wise方式,则 W i W_i Wi为一个标量, W ∈ R d W \in R^{d} W∈Rd是一个向量。
第二步:通过第一步中得到的gate value施加到原始embedding向量上, g i e i = g i ⊙ e i g_ie_i = g_i\odot e_i giei=gi⊙ei, ⊙ \odot ⊙表示哈达玛积,也就是element-wise product,对应元素相乘。
最后,得到新的gate-aware embeddings, G E = [ g 1 e 1 , g 2 e 2 , . . . . , g n e n ] GE=[g_1e_1, g_2e_2,....,g_ne_n] GE=[g1e1,g2e2,....,gnen]输入到MLP中。
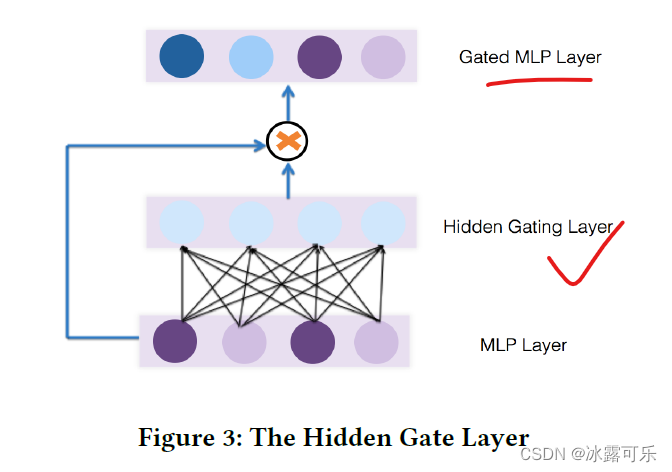
1.2、隐藏层Gate(Hidden Gate)
另外一种施加Gate网络的地方就是MLP的隐藏层,这个我也不上图了,直接参考图1吧,结构一模一样。计算步骤公式直接看1.1中bit-wise就可以。
二、GateNet论文实验结论
论文中做了大量的实验来验证了几个问题(只基于论文的实验结论,具体业务场景可能结论不一样,大家参考下就可以)
问题1:gate参数field private方式与field sharing方式那个效果好?
实验结果表明,field private方式的模型效果优于field sharing方式。
问题2:gate施加方式 bit-wise与vector-wise哪个效果好?
在Criteo数据集上,bit-wise的效果比vector-wise的好,但在ICME数据集上得不到这样的结论。
问题3:gate施加在embedding层和隐藏层哪个效果好?
论文中没有给出结论,但从给出的数据来看在隐藏层的比在embedding层效果好。此外,两种方式都用的话,相比较只用一种,效果提升不大。
问题4:gate网络用哪个激活函数好?
embedding层是linear,隐藏层是tanh。
三、自己实践中一些结论
我们自己的场景下(多任务下,ctcvr)实践结果来看,有几个结论仅供参考:
- gate作用在embedding层与输入层之间效果比作用在隐藏层之间好。
- gate使用bit-wise效果好于vector-wise。
- gate网络的激活函数sigmoid无论在收敛性和auc增益上都要显著好于其它的激活函数。
参考文献:
[1] Huang T , She Q , Wang Z , et al. GateNet: Gating-Enhanced Deep Network for Click-Through Rate Prediction[J]. 2020.