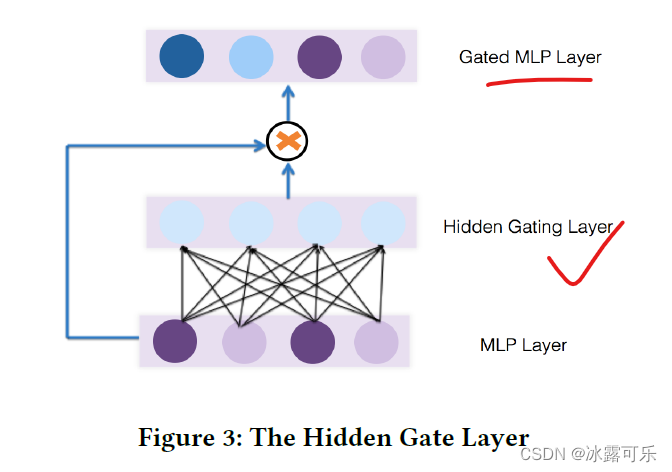
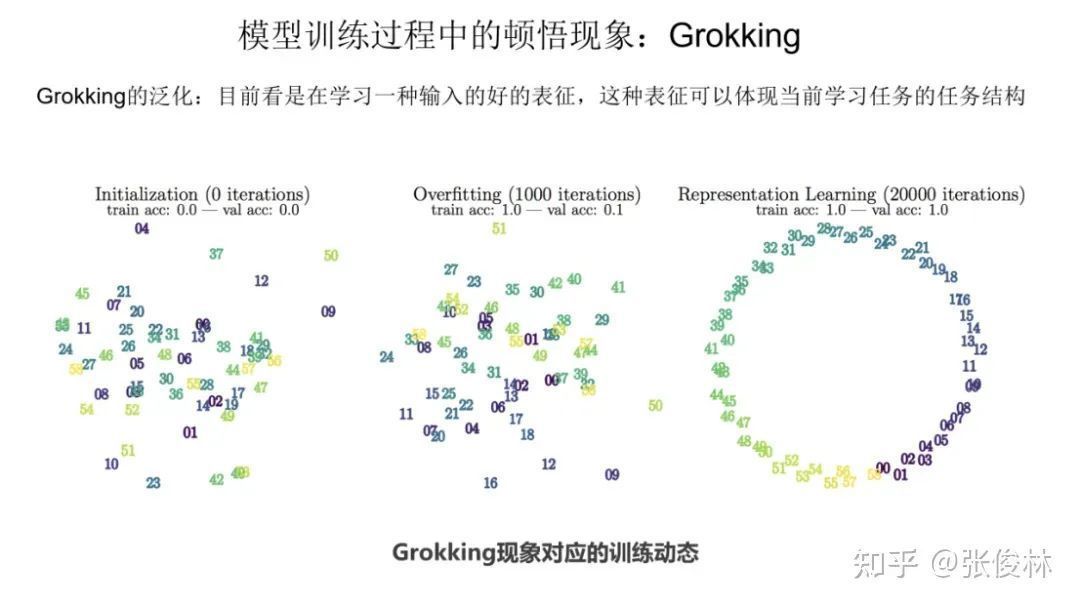
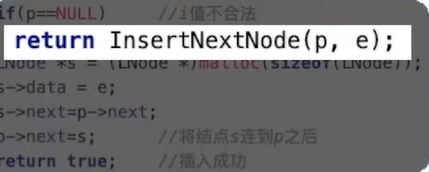
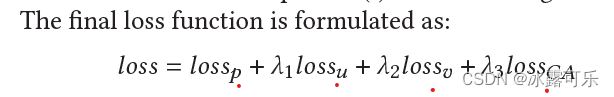知乎:张俊林
链接:https://zhuanlan.zhihu.com/p/622365988
编辑:深度学习自然语言处理 公众号
先说第一个现象。
自从LLaMA和ChatGLM开源后,再加上各种五花八门的“Self Instruct”数据在网上逐渐汇合,大模型两大要素都齐备了,基座模型有了,命令调教数据也越来越多了。于是,最近新冒出的大模型与日俱增。也许,我们可以重新定义新阶段的大模型“涌现能力”:当开源模型与instruct数据数量小于一定规模的时候,就几乎看不到新的大模型出现,而当开源模型及instruct数据数量达到一定规模,新的“大模型”数量就会以指数速度增长,进而达到“人手一个大模型”的阶段。现在大家发愁的不是没有”大模型“,而是发愁给大模型起个啥名字才好,起名字的时间成本可能要高于炼大模型的时间成本,貌似动物园里动物的名字快被用光了,需要换个赛道起名字了。
当然,我是举双手赞成大模型的各种形式的开源的,开源促进生态繁荣,毫无疑问是个好事情,虽然我不认为通过开源可以复制出GPT 4这种水准的大模型。但是,对于目前每天一个大模型的现象,个人感觉”既有意义也没意义“,要分两头来看。”有意义“之处在于:每个人都能通过这种方式来练练手试试水,感知下大模型这个新物种,而且可以利用这种方式,去构建或测试一些对模型能力要求不那么高的垂直场景的应用效果。“没有意义”之处在于:如果大家都是拿个LLaMA 7B/ChatGLM 6B基座,之后再从网上下载instruct数据去instruct fine-tune模型,然后起个名字发出来,作为新的开源模型。这种做法意思不大,自己练练手就得了,没必要起个名字再发出来,除非与当前已经开源的模型比真有独特的优点,或新的增益。
我觉得可以做下面几件事情,然后开源出来,意义相对比较大:
其一,最起码的,把基座模型规模再往大放一放,比如把LLaMA放到30B甚至65B,再加上目前能收集到最全的instruct,再把模型推理方面对资源需求降低些,起个名字,开源放出来,也有意义;
其二,在LLaMA这种中文支持不太好的模型,加上一个中文数据继续预训练过程(很可能会损害基座模型的能力),把中文能力做个大幅提升,再加上最全的Instruct去Fine-tune。通过这种方式,构建一个虽然小,但是中文能力相对比较强的大模型,也挺有意义;
其三,在当前开源的大模型基础上,结合某些垂直领域的数据,改造出开源的领域大模型,这个很有意义;
其四,在LLaMA+instruct之后,或者ChatGLM基础上,探索点新的技术改进路线,为LLM社区提供些技术启发,这个是很有意义的;
接下来说第二个现象。
目前来看,构建全面的权威中文LLM评测集合,是个当务之急。正因为不存在这种评测数据,再加上上面说的第一个现象,复现出一个看着貌似效果还可以的大模型成本很低,才会出现我们现在看到的现象:每天一个新模型冒出来,很多都说自己效果特别好,反正没有标准答案,我就挑自己的一两个优点来说,或者自己挑选几个比ChatGPT回答得好的例子发出来,然后说自制的大模型效果接近于ChatGPT的效果,别人除了说“没毛病”外,确实也说不出啥。这个现象好吗?肯定是不好的,因为对于那些真正效果好的大模型来说很不公平,它们会被淹没在众多嘈杂的声音中,完全得不到本该有的关注度,而且公众的热情也会被消耗殆尽。比如,现在您看看,还有多少人有热情去参与各种新模型的公测?我估计已经不太多了,这对于真正效果好的大模型后续收集用户反馈进一步迭代,冲击是很大的。
如果有一个权威的LLM中文评测集,我相信对于解决目前的现象是有极大帮助的,估计再过两个月会出来一批中文评测集,而再过一阵子,估计下半年,那个或那几个好的评测集合会跑出来。新的大模型效果好不好,大家都拿权威评测集合来说话,而不是目前自说自话的状态。
当然,构建好的LLM评测集合,本身其实也很有难度,比如选择哪些评测维度?评测指标怎么设计?评测数据如何而来?怎样保证这些评测数据不会出现在大模型的预训练数据里?而当你发布评测结果的时候,评测例子要不要给出来?如果给出来,那么下一个新的大模型会不会把它拿来放到训练数据里?或者专门拿这种类型的数据去强化自己的模型?这都是问题,也很考验LLM评测设计者的水平。
而且最好是有两套评测数据,一套是评测基座模型各项能力的,另外一套是测试带上instruct调试之后能力的。因为根据目前的情况看,如果只能测试带Instruct之后的模型,就像上面提到的,很可能很多基座能力强的模型,都没机会和足够的关注度,去拿到用户的反馈数据,都走不到第二阶段。如果能有单独的一个基座能力测试,就会好很多,起码基座能力强的,可能还有些机会。否则,大家做大模型,很可能即使基座大模型效果很强,但没法拿到用户反馈数据进入第二阶段,就只能落入拿GPT 4接口收集”Self Instruct“的怪圈,如果那样,恐怕想赶上GPT 4,难比登天。
无论如何,目前百花齐放的情景总体而言还是挺好的,虽然有些混沌,但是大概也是作为技术追赶者必经的阶段。
进NLP群—>加入NLP交流群(备注nips/emnlp/nlpcc进入对应投稿群)
加入星球,你将获得:
1. 每日更新3-5篇论文速读
2. 最新入门和进阶学习资料
3. 每日1-3个AI岗位招聘信息