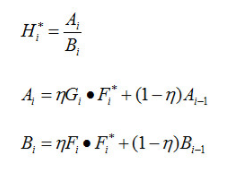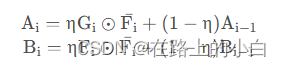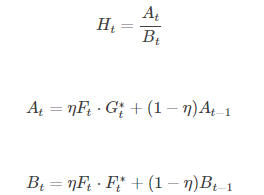引言
MOSSE是在Visual Object Tracking using Adaptive Correlation Filters这篇文章中提出来的,MOSSE的全称是Minimum Output Sum of Squared Error,令平方误差和最小来计算得到滤波器。
算法流程
相关滤波很容易理解,一帧图像经过相关运算(滤波器)之后得到的响应图中,响应最大的位置就是目标所在的位置。这个相关计算的模板也就是滤波器,它滤除了和它不相关的内容。
相关运算和卷积运算
相关Correlation和卷积Convolution有着紧密的联系。以一维的情况考虑。 f [ n ] f[n] f[n]是原始序列, h [ n ] h[n] h[n]是滤波器,在它们都是实数的情况下,相关运算结果 g [ n ] g[n] g[n]可以表示为:
g [ n ] = ∑ τ = − ∞ ∞ f [ τ ] h [ n + τ ] g[n] = \sum^{\infty}_{\tau=-\infty}f[\tau]h[n+\tau] g[n]=τ=−∞∑∞f[τ]h[n+τ]
两者卷积的结果为:
f [ n ] ∗ h [ n ] = ∑ τ = − ∞ ∞ f [ τ ] h [ τ − n ] f[n]\ast h [n] = \sum^{\infty}_{\tau=-\infty}f[\tau]h[\tau-n] f[n]∗h[n]=τ=−∞∑∞f[τ]h[τ−n]
可以观察到,相关和卷积的计算非常相似,我们如果让 f [ n ] f[n] f[n]与 h [ − n ] h[-n] h[−n]卷积,那就能得到相关计算的结果了。有人可能会问了 h [ n ] h[n] h[n]可以理解,但是 h [ − n ] h[-n] h[−n]的话索引就小于0了,是什么呀?我们先不管这个,先定性地再理解一下卷积和相关运算的区别。在一维的情况下,相关运算就像是把一条线段在另一条线段上拖动,每次两条线段重合区域的长度就是运算结果;卷积运算则是仅仅多了把一条线段反转的步骤,同样也是拖动然后看重合的长度。这样我们就好理解了,这个 h [ − n ] h[-n] h[−n]中的负号只是起到了序列前后反转的作用。
g [ n ] = f [ n ] ∗ h [ − n ] g[n] =f[n]\ast h [-n] g[n]=f[n]∗h[−n]
那么我们就可以把相关运算表示成上面的卷积运算。很多情况下,如果 h [ n ] h[n] h[n]是一个对称的序列,那么卷积和相关运算得到的结果就是一样的。
为了简化计算,时域的卷积转化为频域的乘积,我们用DFT可以由 f [ n ] f[n] f[n]计算得到 F [ k ] F[k] F[k],下面是 h [ n ] h[n] h[n]的DFT:
H [ k ] = ∑ n = 0 N − 1 h [ n ] e − j 2 π k n N H[k]=\sum^{N-1}_{n=0}{h[n]e^{-j2\pi\frac{kn}{N}}} H[k]=n=0∑N−1h[n]e−j2πNkn
而 h [ − n ] h[-n] h[−n]经过DFT之后得到的是什么呢?因为一个序列就只有0到N-1的索引,这负的索引是什么呢?为此我又回顾了一遍DFT,我看的主要是奥本海姆的《离散时间信号处理》。书里讲的DFT和DFS非常像,确实非常像!我自己的理解是:DFS和传统意义的傅立叶变换更接近,它实现的是离散周期序列与离散周期序列之间的转换(因为存在“周期对离散”,“非周期对连续”这样的对应关系)。而DFT则是截取了DFS的一个周期的序列来表示,可以说只是一种表示方法,在处理的时候要注意它固有的周期性。
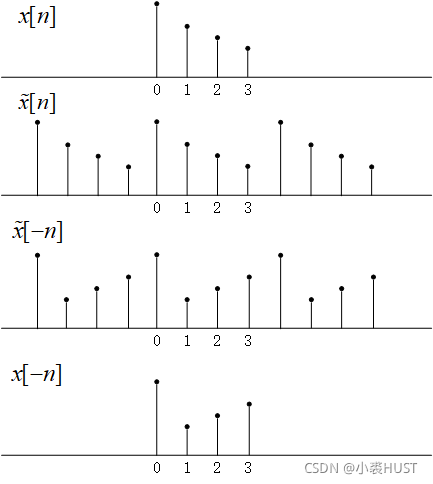
举个例子, x [ n ] x[n] x[n]是长度为4的序列, x ~ [ n ] \tilde x[n] x~[n]是周期延拓后的序列, x ~ [ − n ] \tilde x[-n] x~[−n]是翻转后的序列, x [ − n ] x[-n] x[−n]是从翻转后的序列中提取一个周期的序列。
∑ n = 0 N − 1 h [ − n ] e − j 2 π k n N = h [ 0 ] + ∑ n = 1 N − 1 h [ N − n ] e − j 2 π k n N \sum^{N-1}_{n=0}{h[-n]e^{-j2\pi\frac{kn}{N}}}=h[0]+ \sum^{N-1}_{n=1}{h[N-n]e^{-j2\pi\frac{kn}{N}}} n=0∑N−1h[−n]e−j2πNkn=h[0]+n=1∑N−1h[N−n]e−j2πNkn
令 l = N − n l=N-n l=N−n,则 n = N − l n=N-l n=N−l,代入上式得:
h [ 0 ] + ∑ l = 1 N − 1 h [ l ] e − j 2 π k ( N − l ) N = h [ 0 ] + ∑ l = 1 N − 1 h [ l ] e j 2 π k l N = ∑ l = 0 N − 1 h [ l ] e j 2 π k l N = H ∗ [ k ] h[0]+ \sum^{N-1}_{l=1}{h[l]e^{-j2\pi\frac{k(N-l)}{N}}}=h[0]+ \sum^{N-1}_{l=1}{h[l]e^{j2\pi\frac{kl}{N}}}= \sum^{N-1}_{l=0}{h[l]e^{j2\pi\frac{kl}{N}}}=H^*[k] h[0]+l=1∑N−1h[l]e−j2πNk(N−l)=h[0]+l=1∑N−1h[l]ej2πNkl=l=0∑N−1h[l]ej2πNkl=H∗[k]
到这里我们就有了 f [ n ] f[n] f[n]和 h [ − n ] h[-n] h[−n]的DFT,它们俩的卷积可以用乘积表示,我们把 g [ n ] g[n] g[n]的DFT结果记为 G [ k ] G[k] G[k],则:
G [ k ] = F [ k ] ⊙ H ∗ [ k ] G[k] = F[k]\odot H^*[k] G[k]=F[k]⊙H∗[k]
MOSSE算法
上面的式子再推广到二维的情况也一样是成立的, ⊙ \odot ⊙表示二维矩阵 F F F和 H ∗ H^* H∗的对应元素相乘。
G = F ⊙ H ∗ G = F\odot H^* G=F⊙H∗
我们的目标是求 H ∗ H^* H∗, F F F是输入的图像, G G G是输出的响应。这个响应需要我们自己设计。目标经过滤波器后,目标所在位置的响应最大,当目标在图像中央时,我们可以把这个响应设定为峰值位置在图像中央的二维高斯函数。
如果只有一幅训练图片的话,这就已经能算出来了, H ∗ = G F H^*=\frac{G}{F} H∗=FG(这里的除法指的是对应元素相除),但是一般不只一幅图,所以要求一个最优的 H ∗ H^* H∗。为此论文中提出的准则是使每幅图计算的结果和高斯模板之间的平方误差之和最小,用公式表示就是:
min H ∗ ∑ i ∣ F i ⊙ H ∗ − G i ∣ 2 \mathop {\min }\limits_{{H^*}} \sum\limits_i {{{\left| {{F_i} \odot {H^*} - {G_i}} \right|}^2}} H∗mini∑∣Fi⊙H∗−Gi∣2
接下来就是想办法求这个最优化问题了,可以看到它类似一个一元二次函数,但这里又都是复数运算,所以还是有点不同。求解 H ∗ H^* H∗可以分解为求解它的每一个元素。对于 w w w行, v v v列的元素,有:
min H ∗ ∑ i ∣ F i w v ⊙ H w v ∗ − G i w v ∣ 2 \mathop {\min }\limits_{{H^*}} \sum\limits_i {{{\left| {{F_{iwv}} \odot {H^*_{wv}} - {G_{iwv}}} \right|}^2}} H∗mini∑∣Fiwv⊙Hwv∗−Giwv∣2
这就是标量运算了,我们先看 i = 1 i=1 i=1的情况。
min H ∗ ∣ F w v H ∗ w v − G w v ∣ = min H ∗ ( F w v H ∗ w v − G w v ) ( F w v H ∗ w v − G w v ) ∗ = min H ∗ F w v F w v ∗ H w v H ∗ w v − G w v F w v ∗ H w v − G w v ∗ F w v H ∗ w v − G w v G ∗ w v \begin{array}{l} \mathop {\min }\limits_{{H^*}} \left| {{F_{wv}}{H^*}_{wv} - {G_{wv}}} \right|\\ = \mathop {\min }\limits_{{H^*}} \left( {{F_{wv}}{H^*}_{wv} - {G_{wv}}} \right){\left( {{F_{wv}}{H^*}_{wv} - {G_{wv}}} \right)^*}\\ = \mathop {\min }\limits_{{H^*}} {F_{wv}}{F_{wv}}^*{H_{wv}}{H^*}_{wv} - {G_{wv}}{F_{wv}}^*{H_{wv}} - {G_{wv}}^*{F_{wv}}{H^*}_{wv} - {G_{wv}}{G^*}_{wv} \end{array} H∗min∣FwvH∗wv−Gwv∣=H∗min(FwvH∗wv−Gwv)(FwvH∗wv−Gwv)∗=H∗minFwvFwv∗HwvH∗wv−GwvFwv∗Hwv−Gwv∗FwvH∗wv−GwvG∗wv
求极值要涉及对复数的变量求导,有人提出了Wirtinger导数,其中 z = x + j y z=x+jy z=x+jy,
∂ ∂ z = 1 2 [ ∂ ∂ x − j ∂ ∂ y ] ∂ ∂ z ∗ = 1 2 [ ∂ ∂ x + j ∂ ∂ y ] \frac{\partial }{{\partial z}} = \frac{1}{2}\left[ {\frac{\partial }{{\partial x}} - j\frac{\partial }{{\partial y}}} \right]\\ \frac{\partial }{{\partial {z^*}}} = \frac{1}{2}\left[ {\frac{\partial }{{\partial x}} + j\frac{\partial }{{\partial y}}} \right] ∂z∂=21[∂x∂−j∂y∂]∂z∗∂=21[∂x∂+j∂y∂]
根据上面的式子可以计算得到:
∂ ∂ z z ∗ = ∂ ∂ z ∗ z = 0 \frac{\partial }{{\partial z}}{z^*} = \frac{\partial }{{\partial {z^*}}}z = 0 ∂z∂z∗=∂z∗∂z=0
据此可以知道 H w v H_{wv} Hwv在对 H w v ∗ H_{wv}^* Hwv∗求导的时候可以看作常数。因此对目标函数求导,并令导数为0可得:
∂ ∂ H w v ∗ ( F w v F w v ∗ H w v H ∗ w v − G w v F w v ∗ H w v − G w v ∗ F w v H ∗ w v − G w v G ∗ w v ) = F w v F w v ∗ H w v − G w v ∗ F w v = 0 \begin{array}{l} \frac{\partial }{{\partial {H^*_{wv}}}}\left( {{F_{wv}}{F_{wv}}^*{H_{wv}}{H^*}_{wv} - {G_{wv}}{F_{wv}}^*{H_{wv}} - {G_{wv}}^*{F_{wv}}{H^*}_{wv} - {G_{wv}}{G^*}_{wv}} \right)\\ = {F_{wv}}{F_{wv}}^*{H_{wv}} - {G_{wv}}^*{F_{wv}} = 0 \end{array} ∂Hwv∗∂(FwvFwv∗HwvH∗wv−GwvFwv∗Hwv−Gwv∗FwvH∗wv−GwvG∗wv)=FwvFwv∗Hwv−Gwv∗Fwv=0
H w v = G w v ∗ F w v F w v F w v ∗ , H w v ∗ = G w v F w v ∗ F w v F w v ∗ {H_{wv}} = \frac{{{G_{wv}}^*{F_{wv}}}}{{{F_{wv}}{F_{wv}}^*}}, {H_{wv}}^* = \frac{{{G_{wv}}{F_{wv}}^*}}{{{F_{wv}}{F_{wv}}^*}} Hwv=FwvFwv∗Gwv∗Fwv,Hwv∗=FwvFwv∗GwvFwv∗
再推广到 i > 1 i>1 i>1的情况:
H ∗ = ∑ i G i ⊙ F i ∗ ∑ i F i ⊙ F i ∗ {H^*} = \frac{{\sum\nolimits_i {{G_i} \odot {F_i}^*} }}{{\sum\nolimits_i {{F_i} \odot {F_i}^*} }} H∗=∑iFi⊙Fi∗∑iGi⊙Fi∗
最后引入了学习率 η \eta η来更新 H ∗ H^* H∗:
H n ∗ = A n B n A n = η G n ⊙ F n ∗ + ( 1 − η ) A n − 1 B n = η F n ⊙ F n ∗ + ( 1 − η ) B n − 1 \begin{array}{l} {H_n}^* = \frac{{{A_n}}}{{{B_n}}}\\ {A_n} = \eta {G_n} \odot {F_n}^* + (1 - \eta ){A_{n - 1}}\\ {B_n} = \eta {F_n} \odot {F_n}^* + (1 - \eta ){B_{n - 1}} \end{array} Hn∗=BnAnAn=ηGn⊙Fn∗+(1−η)An−1Bn=ηFn⊙Fn∗+(1−η)Bn−1
其中 n = 1 , 2 , 3... n=1,2,3... n=1,2,3...代表测试图片的帧数。 A 0 = ∑ i G i ⊙ F i ∗ A_0=\sum\nolimits_i {{G_i} \odot {F_i}^*} A0=∑iGi⊙Fi∗, B 0 = ∑ i F i ⊙ F i ∗ B_0=\sum\nolimits_i {{F_i} \odot {F_i}^*} B0=∑iFi⊙Fi∗,实践中发现, η = 0.125 \eta=0.125 η=0.125效果较好。