背景介绍
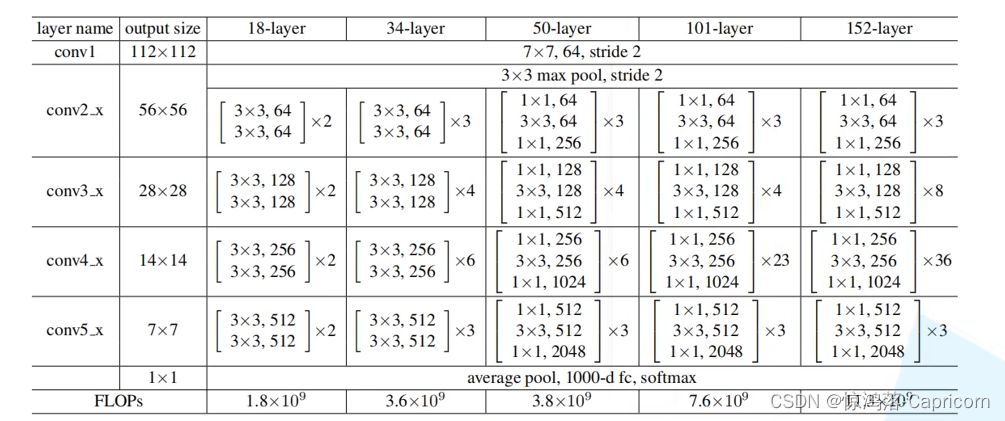
ResNet-50侧边输出形状
假设输入为352,则
output2 = 256x88x88
output3 = 512x44x44
output4 = 1024x22x22
output5 = 2048x11x11VGG-16侧边输出形状
假设输入为352,则
output1 = 64x320x320output2 = 128x160x160
output3 = 256x88x88
output4 = 512x44x44
output5 = 512x22x22

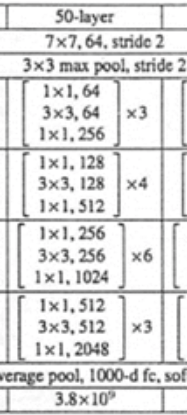
请看50-layer这一列
是本文介绍的层的结构:
resnet-50
有四组大block,
每组分别是3, 4, 6, 3个小block,
每个小block里面有三个卷积,
另外这个网络的最开始有一个单独的卷积层,
因此是:(3+4+6+3)*3+1=49
最后又一个全连接层,因而一共50层
如下图,每个大block里面的
第一个都是IN !==OUT情况,左侧支线,命名为:Conv Block
其他都是 IN ==OUT情况,右侧支线, 命名为:ID Block
3 = 左+右+右
4 = 左+右+右+右
6 = 左+右+右+右+右+右
3 = 左+右+右

0 特征图尺寸计算
1 卷积层计算: N = (W-F+2P)/2 + 1
F 卷积核
S 步长
P Padding
2 池化层计算: N = (W-F)/s + 1
F 卷积核
S 步长
P Padding
3 当尺寸不被整除时,
卷积向下取整,池化向上取整。
本题中 (200-5+2*1)/2+1 为99.5,取99
(99-3)/1+1 为97
(97-3+2*1)/1+1 为97
卷积前后尺寸不变情况: 当stride为1的时候,当kernel为 3 padding为1或者kernel为5 padding为2 ,卷积前后尺寸不变。
1 resnet用skip-connection规避梯度消失问题
梯度消失:反向传递到浅层的时候,gradient会小到接近0,
导致学习效率低,parameters更新越来越慢
多个Resnet Blocks累积起来能解决梯度消失问题。
Resnet Block = main path + skip connection

2 ResNet有2个基本的block:
Identity Block: 输入和输出的dimension是一样的, 所以可以串联多个;
串联多个,
可直接相加,
维度不变(input shape = output shape)
Conv Block: 输入和输出的dimension是不一样的,所以不能连续串联,它的作用本来就是为了改变特征向量的dimension
不能连续串联,
在skip connection里面加入了conv2d layer, 以让维度相等然后相加
改变维度 (input shape != output shape)
因为CNN最后都是要把输入图像一点点的转换成很小但是depth很深的feature map,
一般的套路是用统一的比较小的kernel(比如VGG都是用3*3),
但是随着网络深度的增加,output的channel也增大(学到的东西越来越复杂),
所以有必要在进入Identity Block之前,用Conv Block转换一下维度,这样后面就可以连续接Identity Block.
Identity Block:
Conv Block:
Conv Block 的不同之处在于:
其实就是在shortcut path的地方加上一个conv2D layer(1*1 filter size),
然后在main path改变dimension,并与shortcut path对应起来.
3 如何搭建一个跨越三层的Conv Block

1 main path
第一: Conv-BatchNorm-ReLU block
conv2d: filter=F1, kernel_size=1, stride=s, padding=valid
output shape变小
起名,random seed=0, BatchNorm axis=3 貌似是tf keras的
第二: Conv-BatchNorm-ReLU block
conv2d: filter=F2, kernel_size=f, stride=1, padding=same
output shape不变
起名,random seed=0, BatchNorm axis=3 貌似是tf keras的
第三: Conv-BatchNorm-ReLU block
conv2d: filter=F3, kernel_size=1, stride=1, padding=valid
output shape不变
得到最终的X_output
2 skip-connection
Conv-BatchNorm block
conv2d: filter=F3, kernel_size=1, stride=s, padding=valid
shape与X_output一致
axis=3
返回X_skip
3 X_skip + X_output 通过ReLU函数
4 如何搭建一个跨越三层Identity Block

1 main path
第一: Conv-BatchNorm-ReLU block
conv2d: kernel_size=1, stride=1, padding=valid
output shape不变
起名,random seed=0, BatchNorm axis=3 貌似是tf keras的
第二: Conv-BatchNorm-ReLU block
conv2d: kernel_size=f, stride=1, padding=same
output shape不变
起名,random seed=0, BatchNorm axis=3 貌似是tf keras的
第三: Conv-BatchNorm block
conv2d: 同第一
output shape不变
得到最终的X_output
2 skip-connection
3 X_identity = X + X_output 通过ReLU函数
4 整体结构:

zera-padding:
(3x3)上下左右各添加3像素
stage1:
Conv: filters=64, kernel_size=7x7, stride=2x2
BatchNorm:
RELU:
MaxPooling: windows=3x3, stride=2x2
stage2:
1xConv Block: named a
3set: [64, 64, 256], k_s=3x3, stride=1x1
2xID Block: named b,c
3set: [64, 64, 256], k_s=3x3,
stage3:
1xConv Block: named a
3set: [128, 128, 512], k_s=3x3, stride=2x2
3xID Block: named b,c,d
3set: [128, 128, 512], k_s=3x3
stage4:
1xConv Block: named a
3set: [256, 256, 1024], k_s=3x3, stride=2x2
5xID Block: named b,c,d,e,f
3set: [256, 256, 1024], k_s=3x3
stage5:
1xConv Block: named a
3set: [512, 512, 2048], k_s=3x3, stride=2x2
2xID Block: named b,c
3set: [512, 512, 2048], k_s=3x3
Average Pooling: named avg_pool
windows=(2x2)
Flatten:
Fully Connected(Dense) layer: named 'fc'
5 resnet50文字详解
block_sizes=[3, 4, 6, 3]指的是stage1(first pool)之后的4个layer的block数, 分别对应res2,res3,res4,res5,每一个layer的第一个block在shortcut上做conv+BN, 即Conv Block
inputs: (1, 720, 1280, 3)
initial_conv:conv2d_fixed_padding()1. kernel_size=7, 先做padding(1, 720, 1280, 3) -> (1, 726, 1286, 3)2. conv2d kernels=[7, 7, 3, 64], stride=2, VALID 卷积. 7x7的kernel, padding都为3, 为了保证左上角和卷积核中心点对其(1, 726, 1286, 3) -> (1, 360, 640, 64)3. BN, Relu (只有resnetv1在第一次conv后面做BN和Relu)
initial_max_pool:k=3, s=2, padding='SAME', (1, 360, 640, 64) -> (1, 180, 320, 64)
以下均为不使用bottleneck的building_block
block_layer1:(有3个block, layer间stride=1(上一层做pool了), 64个filter, 不使用bottleneck(若使用bottleneck 卷积核数量需乘4))1. 第一个block:Conv Block有projection_shortcut, 且strides可以等于1或者2Identity Block没有projection_shortcut, 且strides只能等于1`inputs = block_fn(inputs, filters, training, projection_shortcut, strides, data_format)`shortcut做[1, 1, 64, 64], stride=1的conv和BN, shape不变然后和主要分支里input做3次卷积后的结果相加, 一起Relu, 注意block里最后一次卷积后只有BN没有Reluinput: conv-bn-relu-conv-bn-relu-conv-bn 和shortcut相加后再做relushortcut: conv-bn shortcut: [1, 1, 64, 64], s=1, (1, 180, 320, 64) -> (1, 180, 320, 64)input做两次[3, 3, 64, 64], s=1的卷积, shape不变(1, 180, 320, 64) -> (1, 180, 320, 64) -> (1, 180, 320, 64)inputs += shortcut, 再relu2. 对剩下的2个block, 每个block操作相同:`inputs = block_fn(inputs, filters, training, None, 1, data_format)`shortcut直接和input卷积结果相加, 不做conv-bninput做两次[3, 3, 64, 64], s=1的卷积, shape不变(1, 180, 320, 64) -> (1, 180, 320, 64) -> (1, 180, 320, 64)inputs += shortcut, 再relu
block_layer2/3/4同block_layer1, 只是每个layer的identity block数量不同, 卷积核数量和layer间stride也不同, 不过仍然只有第一个conv block的shortcut做conv-bn
block_layer2: 4个block, 128个filter, layer间stride=2 (因为上一层出来后没有pool)1. 第一个block:对shortcut做kernel=[1, 1, 64, 128], s=2的conv和BN, (1, 180, 320, 64) -> (1, 90, 160, 128)对主要分支先做kernel=[3, 3, 64, 128], s=2的卷积, padding='VALID', (1, 180, 320, 64) -> (1, 90, 160, 128)再做kernel=[3, 3, 128, 128], s=1的卷积, padding='SAME', (1, 90, 160, 128) -> (1, 90, 160, 128)2. 剩下的3个block, 每个block操作相同:shortcut不操作直接和结果相加做Relu对主要分支做两次[3, 3, 128, 128], s=1的卷积, padding='SAME', (1, 90, 160, 128) -> (1, 90, 160, 128) -> (1, 90, 160, 128)
block_layer3: 6个block, 256个filter, layer间stride=21. 第一个block:对shortcut做kernel=[1, 1, 128, 256], s=2的conv和BN, (1, 90, 160, 128) -> (1, 45, 80, 256)对主要分支先做kernel=[3, 3, 128, 256], s=2的卷积, padding='VALID', (1, 90, 160, 128) -> (1, 45, 80, 256)再做kernel=[3, 3, 256, 256], s=1的卷积, padding='SAME', (1, 45, 80, 256) -> (1, 45, 80, 256)2. 剩下的5个block, 每个block操作相同:shortcut不操作直接和结果相加做Relu对主要分支做两次[3, 3, 256, 256], s=1的卷积, padding='SAME', (1, 45, 80, 256) -> (1, 45, 80, 256) -> (1, 45, 80, 256)
block_layer4: 3个block, 512个filter, layer间stride=21. 第一个block:对shortcut做kernel=[1, 1, 256, 512], s=2的conv和BN, (1, 45, 80, 256) -> (1, 23, 40, 512)对主要分支先做kernel=[3, 3, 256, 512], s=2的卷积, padding='VALID', (1, 45, 80, 256) -> (1, 23, 40, 512)再做kernel=[3, 3, 512, 512], s=1的卷积, padding='SAME', (1, 23, 40, 512) -> (1, 23, 40, 512)2. 剩下的2个block, 每个block操作相同:shortcut不操作直接和结果相加做Relu对主要分支做两次[3, 3, 512, 512], s=1的卷积, padding='SAME', (1, 23, 40, 512) -> (1, 23, 40, 512)
avg_pool, 7*7
FC, output1000
softmax
输出prediction6 resnet50图解