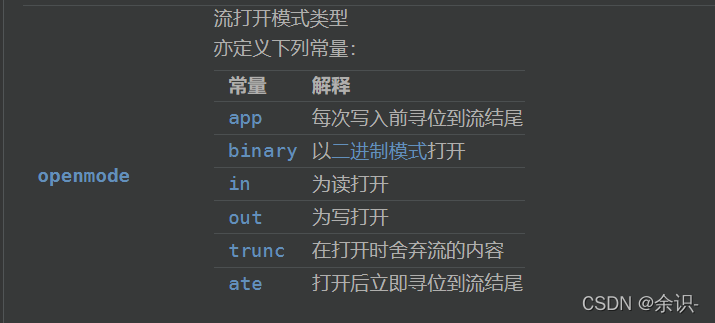
目录
1、文件读写的流程
2、文件读写的几种常见模式(你不清楚的知识点)
3、read、readline、readlines的区别
4、对于一个10G的大文件,怎么高效的查看文件中的内容呢?
1、文件读写的流程
1)类比windows中手动操作txt文档,说明python中如何操作txt文件?
① windows中手动操作txt文件的步骤
- 找到word文档
- 打开word文档
- 查看(或操作)word文档中的内容
- 关闭word文档
② python操作txt文件的步骤
- 获取被打开的文件的内存对象,该内存对象又叫做“文件句柄”。
- 通过这个内存对象(文件句柄),来对文件进行操作(读取,写入等操作)。
- 关闭文件
2)什么是文件的内存对象(文件句柄)?
使用python读取一个txt文件的时候,相当于把这个文件从硬盘上,读取到了内存中。我们如果想要操作这个文件,是不是先要获取这个文件对象?只有获取这个文件对象后,才能够真正的去操作这个文件,不管是读取文件中的内容,还是向文件中写入内容。
这个“文件句柄”包含了文件的文件名、文件的字符集、文件的大小、文件在硬盘上的起始位置。
3)演示怎么读取文件
① 演示如下
f = open(r"G:\6Tipdm\file_read_write\yesterday.txt","r",encoding="utf-8")
data = f.read()
print(data[:245])
f.close()
结果如下:

② 一个很奇怪的现象?
f = open(r"G:\6Tipdm\file_read_write\yesterday.txt","r",encoding="utf-8")
data = f.read()
data1 = f.read()
print(data[:245])
print("-------------------------------------")
print(data1[:245])
f.close()
结果如下:
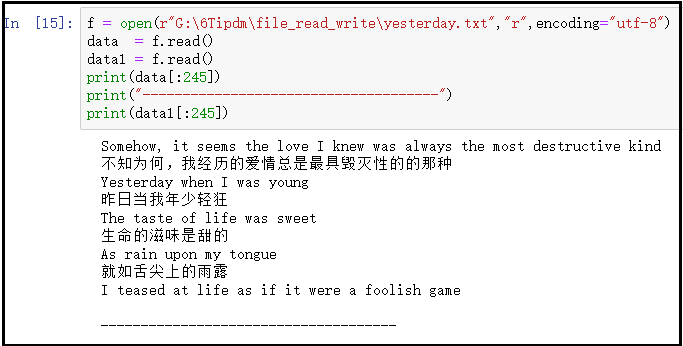
问题:我们读取了2遍内容,为什么只显示了一次读取的结果呢?对于上述问题,我们用一张图回答上述问题。
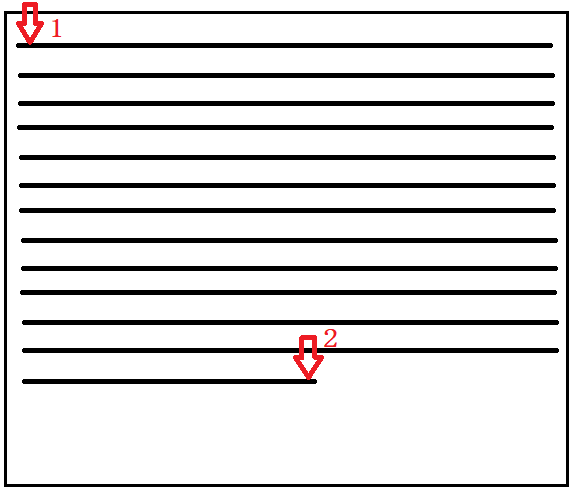
通过上图我们可以发现,当我们操作这个“文件句柄”的read()方法去读取文件的时候,这个句柄会从文件的开头位置1,移动到文件的结束位置2。如果不做任何操作,读取完毕之后,句柄就会停止在2这个位置。因此当我们再次读取文件的时候,该句柄是从2这个位置,往后面读取内容。由于后面没有任何内容,因此第二次读取为空。
那么,如果我们想要第二次同样能够读取到文件中的内容,应该怎么办呢?那么接着往下看。
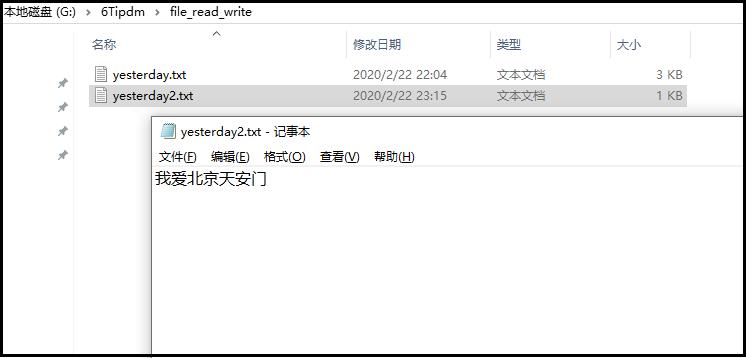
4)演示怎么写文件
f = open(r"G:\6Tipdm\file_read_write\yesterday2.txt","w",encoding="utf-8")
f.write("我爱北京天安门")
f.close()
结果如下:
假如我们在写一句“天安门上太阳升”,会出现啥情况呢?
f = open(r"G:\6Tipdm\file_read_write\yesterday2.txt","w",encoding="utf-8")
f.write("天安门上太阳升")
f.write("很好,很好")
f.close()
结果如下:
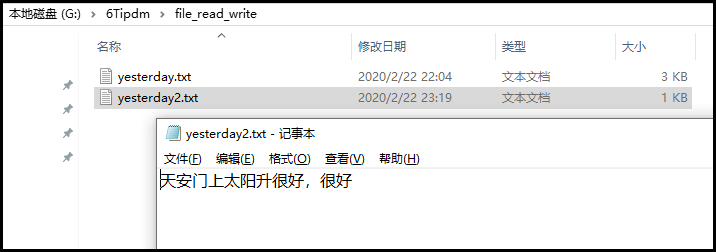
意外发生。当我们再次写入新的内容的时候,发现之前写的内容不见了,这是为啥呢?这就是我们下面要讲述的“文件读写的几种常见模式”。
2、文件读写的几种常见模式(你不清楚的知识点)
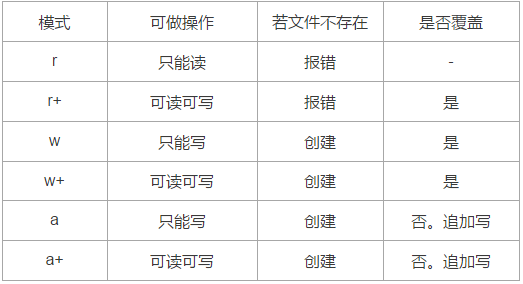
1)关于r+、w+、a+使用说明(易错点)
当我们读取某个文件,向文件中写入某些内容(覆盖写),向文件中追加写入某写内容时,最好的方式就是分别使用r、w、a这三种模式。对于这三种模式,要么读,要么写,读模式就不能写,写模式就不能读。
对于r+、w+、a+这三种模式,如果你不是特别清楚python文件读写的原理,就不要轻易使用,因为会出现很多问题,下面我们仅演示r+、w+、a+这三种模式。
2)r+模式:可读可写
对于这种模式,不管是读取文件中的内容,还是朝文件中写入内容。前提条件:文件存在。
# 只读取文件中的内容
f = open(r"G:\6Tipdm\file_read_write\yesterday1.txt","r+",encoding="utf-8")
data = f.read()
print(data)
f.close()# 朝文件中写入内容后,立即读取,会出现啥问题?
f = open(r"G:\6Tipdm\file_read_write\yesterday1.txt","r+",encoding="utf-8")
f.write("丽丽姑娘")data = f.read()
print(data)
f.close()# 朝文件中写入内容后,调整句柄位置后,再读取,会出现啥问题?
f = open(r"G:\6Tipdm\file_read_write\yesterday1.txt","r+",encoding="utf-8")
f.write("丽丽姑娘")
f.seek(0)
data = f.read()
print(data)
f.close()
结果如下:

结果分析:
使用r+模式,当只读文件的时候,可以读取到其中的内容。
当写入内容后,立即读取文件内容,发现什么也读取不到。这是由于当你写入内容后,文件句柄会放在写入内容的最后面,因此当你立即读取的时候,句柄会从上次内容最后的位置,朝后面读,因此读取为空。
当朝文件中写入内容后,调整句柄位置后,再读取文件中的内容,发现就有了内容。这是由于我们使用了f.seek(0)方法,将句柄由内容末尾调整到了内容开头,因此就又有了内容。
3)w+:可读可写
# 直接往文件中写入内容
f = open(r"G:\6Tipdm\file_read_write\yesterday3.txt","w+",encoding="utf-8")
f.write("bbbbbb")
f.close()# 直接读取上述文件,看看会发生啥问题?(特别注意这一步)
f = open(r"G:\6Tipdm\file_read_write\yesterday3.txt","w+",encoding="utf-8")
data = f.read()
print(data)
f.close()# 朝文件中写入内容后,立即读取,又会发生什么?
f = open(r"G:\6Tipdm\file_read_write\yesterday3.txt","w+",encoding="utf-8")
f.write("哈哈哈哈哈")
data = f.read()
print(data)
f.close()# 朝文件中写入内容后,调整句柄位置后,再读取,会发生什么?
f = open(r"G:\6Tipdm\file_read_write\yesterday3.txt","w+",encoding="utf-8")
f.write("嘿嘿嘿嘿嘿")
f.seek(0)
data = f.read()
print(data)
f.close()
结果如下:
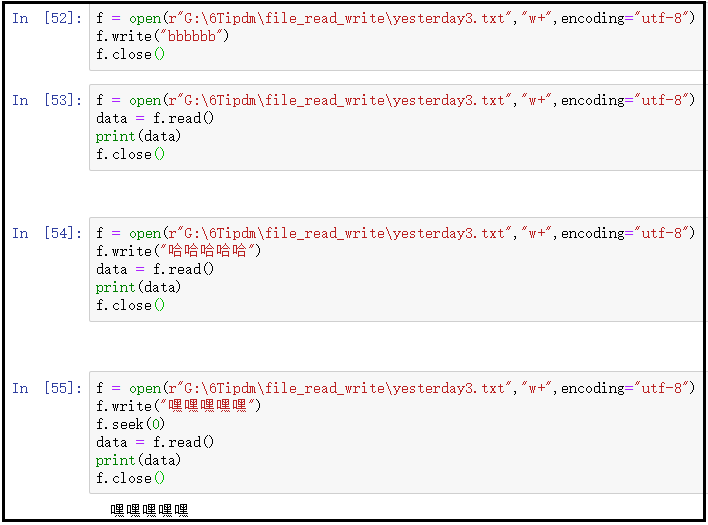
结果分析:
使用w+模式,当我们直接朝文件中写入bbbbbb,毋庸置疑,肯定是可以的。
接着,我们直接读取这个文件中的内容,奇怪的现象发生了,什么都读取不到。这是因为w+模式,在进行文件读取的时候,默认是先写再读。但是我们确实没有写入任何东西呀?这是由于系统默认帮我们写入了一个空值,因此把原有内容覆盖了。所以再当我们读取文件中的内容的时候,发现读取为空。
再接着,我们朝文件中,写入内容后再立即读取,这下仍然读取不到任何内容,这又是为什么呢?这是由于我们第一次写入“哈哈哈哈哈哈”的时候,句柄移动到了内容最后。当我们立即读取的时候,句柄从内容最后的位置,继续朝后面读,因此啥也没有。
最后,当朝文件中写入内容后,调整句柄位置后,再读取文件中的内容,发现就有了内容。这是由于我们使用了f.seek(0)方法,将句柄由内容末尾调整到了内容开头,因此就又有了内容。
4)a+:可读可写
# 直接朝文件中写入内容
f = open(r"G:\6Tipdm\file_read_write\yesterday4.txt","a+",encoding="utf-8")
f.write("哈哈")
f.close()# 直接读取文件中的内容
f = open(r"G:\6Tipdm\file_read_write\yesterday4.txt","a+",encoding="utf-8")
data = f.read()
print(data)
f.close()# 调整句柄位置后,再读取文件中的内容
f = open(r"G:\6Tipdm\file_read_write\yesterday4.txt","a+",encoding="utf-8")
f.seek(0)
data = f.read()
print(data)
f.close()
结果如下:
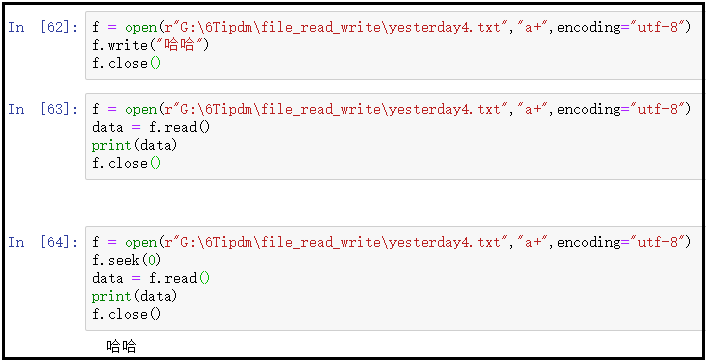
结果分析:
使用a+模式,朝文件中写入内容,毋庸置疑,肯定是没问题的。
接着,当我们读取上述文件中的内容,会发现什么也读取不到。这是由于,使用r+模式打开文件,文件句柄默认放在内容的最后面,因此你直接读取其中的内容,什么也没有。
最后,在读取文件中内容之前,我们使用了f.seek(0)方法,将句柄由内容末尾调整到了内容开头,再次读取文件中的内容,发现就有了内容。
3、read、readline、readlines的区别
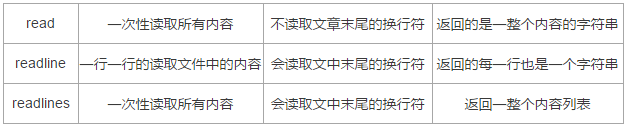
1)read()方法的使用说明
f = open(r"G:\6Tipdm\file_read_write\test.txt","r",encoding="utf-8")
data = f.read()
print(type(data))
print(data)
f.close()
结果如下:

2)readline()方法的使用说明
f = open(r"G:\6Tipdm\file_read_write\test.txt","r",encoding="utf-8")
data = f.readline()
print(type(data))
print(data)
f.close()f = open(r"G:\6Tipdm\file_read_write\test.txt","r",encoding="utf-8")
for i in range(3):data = f.readline()print(data)
f.close()
结果如下:
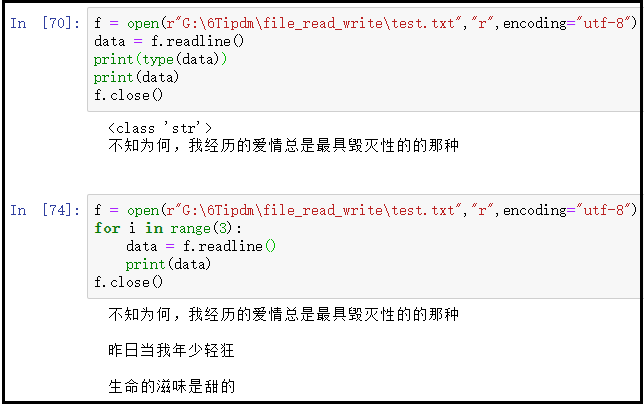
去掉每一行末尾的换行符:
f = open(r"G:\6Tipdm\file_read_write\test.txt","r",encoding="utf-8")
for i in range(3):data = f.readline().strip()print(data)
f.close()
结果如下:

3)readlines()方法的使用说明
f = open(r"G:\6Tipdm\file_read_write\test.txt","r",encoding="utf-8")
data = f.readlines()
print(type(data))
print(data)
f.close()
结果如下:

4、对于一个10G的大文件,怎么高效的查看文件中的内容呢?
1)相关说明
当我们读取文件中的内容,相当于是把写在硬盘上的东西,读取到内存中。不管你是使用read()或者readlines()一次性读取到到内存中,还是使用readline()一行行的将整个内容读取到内存中,如果文件很大,都将会耗用很大的内存。同时,从硬盘读取文件内容到内存中,也会很慢。
因此,有没有一种高效的方式?既让我们看到了文件中的内容,又不会占用内存呢?下面我们将进行说明。
2)操作说明
f = open(r"G:\6Tipdm\file_read_write\yesterday.txt","r",encoding="utf-8")
for line in f:print(line.strip())
部分截图如下:
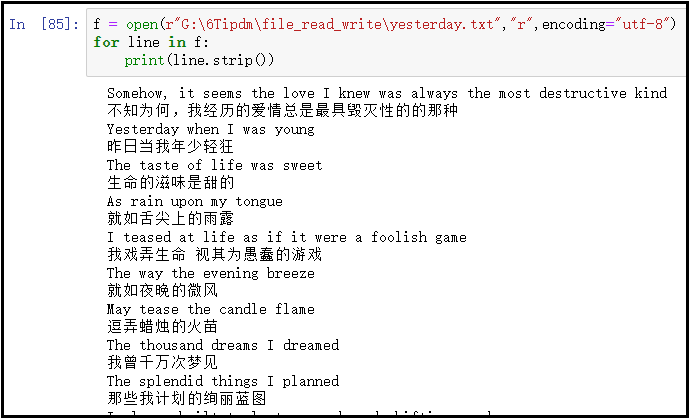
结果说明:
上述方式中,f相当于一个迭代器,我们使用for循环迭代f中元素。每循环一次,就相当于读取一行到内存中,并记住这一次读取到的位置。当进行下次迭代的时候,上一次读取到内存中的内容,就会被销毁了,当前内存中读取的就是第二行的内容。当进行第三次循环的时候,内存中第二行的内容也会被销毁,此时内存中只会保存第三行的内容,这样依次进行下去。直到最后一次循环,读取最后一行的内容,此时,内存中保留的也只是最后一行的内容。
迭代器有一个特性:每次进行迭代的时候,就会记住当前读取的位置。当进行下一次迭代的时候,前面的内容会被销毁掉,在内存中只会保留当前循环得到的内容。