机器人跟踪
The code project can be found on https://github.com/josephbima/sleep-tracker
该代码项目可在https://github.com/josephbima/sleep-tracker上找到
I’ve always wondered the exact time I actually spend sleeping at night. So when I needed ideas for the final project of my Mobile Health and Sensing class, I knew making a sleep tracking application was on the top of my list. So that is what me and my partner decided to do; to use our Android phone and a bit of machine learning to determine if the user is sleeping or not.
我一直想知道我实际上在晚上睡觉的确切时间。 因此,当我需要有关移动健康和传感课程的最终项目的想法时,我知道制作睡眠跟踪应用程序是我的首要任务。 这就是我和我的伴侣决定做的事; 使用我们的Android手机和一些机器学习来确定用户是否在睡觉。
To track our sleep, we used the phone’s tri-axial accelerometer to determine the user is sleeping or in a vigil state. The accelerometer serves as an indicator on how much movement there is on the phone. The more movement there is, the more likely the user is not sleeping, and vice versa. We will use hourly intervals and determine how much of that hour is spent sleeping.
为了跟踪我们的睡眠,我们使用了手机的三轴加速度计来确定用户正在睡觉还是处于警惕状态。 加速度计可以指示手机上有多少移动。 运动越多,用户就越有可能没有睡觉,反之亦然。 我们将使用小时间隔,并确定该小时中有多少时间用于睡眠。
数据采集 (Data Collection)
So first of all, we need to collect some data. We used an Android phone to do this, because it is much more easier to use its accelerometer and retrieve its data compared to using an iOS phone.
因此,首先,我们需要收集一些数据。 我们使用Android手机来执行此操作,因为与使用iOS手机相比,使用其加速度计和检索其数据要容易得多。
We used two methods of collecting data; real-time and simulated. We collected our real-time data by putting our phones in our pockets and going to bed as normal. We composed a rough sleeping log in which we tried to write down at what time we would go to bed and when we would wake up.
我们使用了两种收集数据的方法: 实时和模拟。 我们通过将手机放在衣袋中并照常上床睡觉来收集实时数据。 我们编写了一个粗糙的睡眠日志,试图在其中写下我们什么时候上床睡觉和什么时候醒来。
We wanted to strictly use real-sleep data because we feel it would result in a better activity recognition. However, there are two main problems that came up during this process of collecting data. The first one is the phone stops collecting data after 4 hours and this could be seen when the final timestamp of the generated CSV file was hours before we actually woke up, making us lose half or more than half of our collected data.
我们希望严格使用实时睡眠数据,因为我们认为它会带来更好的活动识别能力。 但是,在收集数据的过程中出现了两个主要问题。 第一个是电话在4小时后停止收集数据,这可以在生成的CSV文件的最终时间戳记是在我们真正醒来之前的几个小时看到的,这会使我们丢失一半或一半以上的收集数据。
Another problem that we encountered is that it becomes increasingly difficult to know the exact time we fall asleep. We knew it wouldn’t be precise but more often than not we just end up guessing to estimate the time when we were tossing and turning and when we were falling asleep. We did this process of data collection for 4 or 5 nights before moving on to another method, because of the problems that would require a lot of work to solve.
我们遇到的另一个问题是,越来越难以知道我们入睡的确切时间。 我们知道这并不精确,但更多时候我们最终只是猜测来估计我们折腾和转弯以及入睡的时间。 由于需要大量工作来解决这些问题,因此在进行另一种方法之前,我们已经进行了4到5个晚上的数据收集过程。
We then came up with a solution, we figured it would save a lot of time and be easier if we just simulated the activities. We then performed two different activities, sleep and vigil. Simulating sleep was easier, as you can just lie down and make minimal movement. Simulating a vigilant state however, is more complex. Simply moving a lot would not work as that is not how people sleep, so you had to gauge how much movement we should make that would a) be realistic and b) would be different enough to the sleep data, so our machine can differentiate between the two.
然后,我们提出了一个解决方案,我们认为,如果仅模拟活动,它将节省大量时间并且更加容易。 然后,我们进行了两种不同的活动:睡眠和守夜。 模拟睡眠比较容易,因为您可以躺下来并尽量减少运动。 但是,模拟警戒状态会更加复杂。 简单地移动很多东西是行不通的,因为这不是人们的睡眠方式,因此您必须衡量我们应该做多少运动,这将使a)逼真的b)与睡眠数据有足够的差异,因此我们的机器可以区分他们俩。
The problem with this approach is obviously the fact that we are not getting ‘real’ data, but we figured it was close enough to the real data and the time it saved was very beneficial for us.
这种方法的问题显然是我们没有得到“真实”数据,但我们认为它与真实数据足够接近,并且节省的时间对我们非常有益。
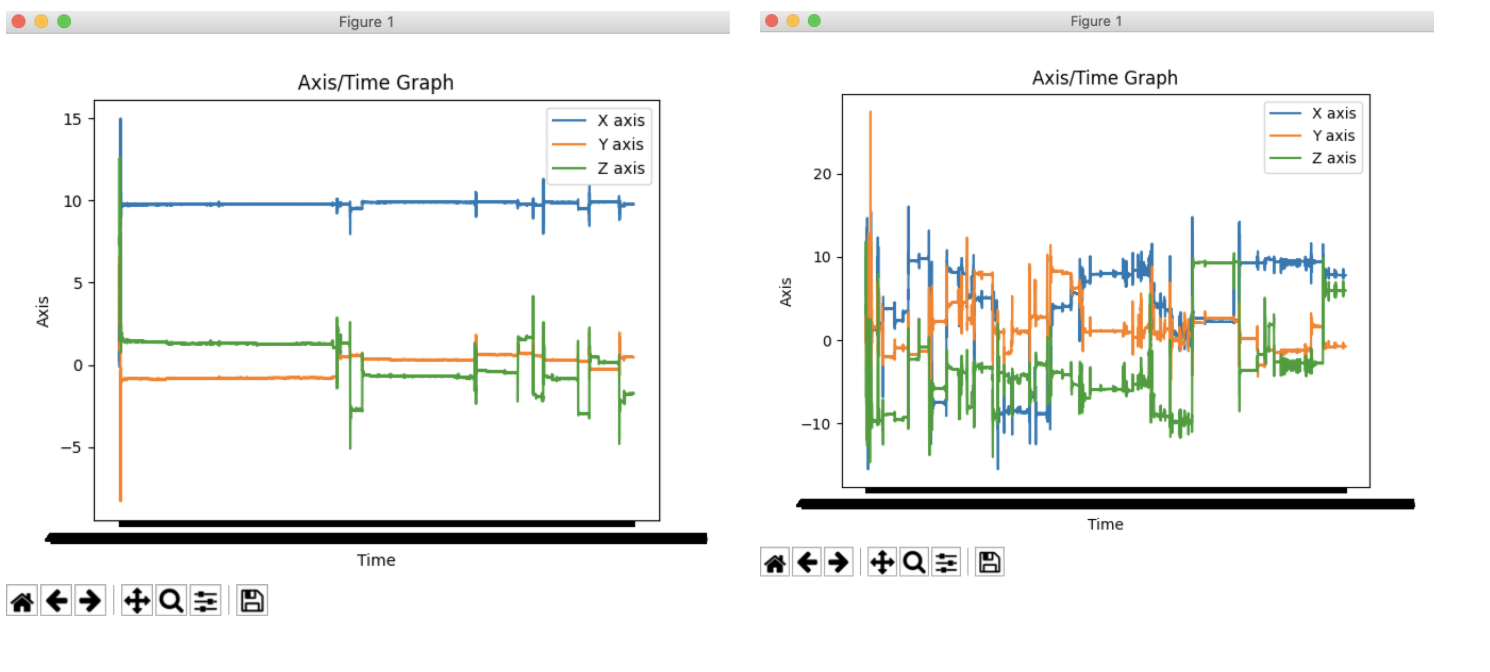
机器学习 (Machine Learning)
So now that we have all our data, it is time to do the fun machine learning stuff and train our model to predict if someone is sleeping or not. But before that, we made sure to remove the noise in our datas by applying a butter filter.
因此,既然我们拥有了所有数据,就该做有趣的机器学习知识并训练我们的模型以预测某人是否在睡觉了。 但在此之前,我们确保通过应用黄油过滤器消除数据中的噪音。
First, we need to extract some features from our data, the classifier will be looking at these features to determine the output later on. Those features are; mean, standard deviation, peak length, magnitude, dominant frequency, and entropy.
首先,我们需要从数据中提取一些特征,分类器将查看这些特征以确定稍后的输出。 这些功能是; 均值,标准差,峰长,幅度,主导频率和熵。
We picked these features because we are going to detect the difference in accelerometer movement, so it makes sense to pick features that can represent how ‘great’ the accelerometer movements are.
我们之所以选择这些功能,是因为我们要检测加速度计运动的差异,因此选择可以代表加速度计运动“有多大”的特征是有意义的。
Below is the code for the feature extraction part.
以下是特征提取部分的代码。
def _compute_mean_features(window):"""Computes the mean x, y and z acceleration over the given window. """return np.mean(window, axis=0)def _compute_std_features(window):'''Computes the standard deviation of x, y and z acceleration over the given window. Returns an array of numbers corresponding to the x, y and z values'''return np.std(window, axis = 0)def _compute_dominant_frequency(window):'''Computes the dominant frequency of x, y and z acceleration over the given window. '''return np.fft.rfft(window,axis=0).astype(float)[0]def _compute_peak_length(window):'''Computes the peak length of x, y and z acceleration over the given window. '''magnitude = _compute_magnitude(window)peaks, _ = find_peaks(magnitude, prominence=1)return [len(peaks)]Now it is time for us to use a classifier to, well classify the data based on the features we have extracted.
现在是时候使用分类器,根据我们提取的特征对数据进行分类了。
We created a random forest decision tree using a Stratified KFold cross validation across 10 folds in the data. First we split up the data into 5 minutes intervals and randomly split them up into folds of 10 using the stratifiedKFold method from scikit-learn. We then used a Random Forest classifier to generate a random forest decision tree for our model. We found that this approach yields the best result rather than using the model_selection.KFold method and the regular decision tree.
我们使用跨10折数据的分层KFold交叉验证创建了随机森林决策树。 首先,我们将数据分成5分钟间隔,并使用scikit-learn的stratifiedKFold方法将其随机分为10倍。 然后,我们使用随机森林分类器为模型生成随机森林决策树。 我们发现,这种方法比使用model_selection.KFold方法和常规决策树可获得最佳结果。
total_accuracy = 0.0
total_precision = 0.0
total_recall = 0.0# Iterate over the cv and fit the decision tree using the training set
# https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.htmlfor i, (train_index, test_index) in enumerate(cv.split(X, Y)):X_train, X_test = X[train_index], X[test_index]y_train, y_test = Y[train_index], Y[test_index]tree = DecisionTreeClassifier(criterion="entropy", max_depth=3)print("Fold {} : Training decision tree classifier over {} points...".format(i, len(y_train)))sys.stdout.flush()tree.fit(X_train, y_train)print("Evaluating classifier over {} points...".format(len(y_test)))# predict the labels on the test datay_pred = tree.predict(X_test)# show the comparison between the predicted and ground-truth labelsconf = confusion_matrix(y_test, y_pred, labels=[0,1])accuracy = np.sum(np.diag(conf)) / float(np.sum(conf))precision = np.nan_to_num(np.diag(conf) / np.sum(conf, axis=1).astype(float))recall = np.nan_to_num(np.diag(conf) / np.sum(conf, axis=0).astype(float))total_accuracy += accuracytotal_precision += precisiontotal_recall += recallprint("The average accuracy is {}".format(total_accuracy/10.0))
print("The average precision is {}".format(total_precision/10.0))
print("The average recall is {}".format(total_recall/10.0))# Set this to the best model we found, trained on all the data:
best_classifier = RandomForestClassifier(n_estimators=100)
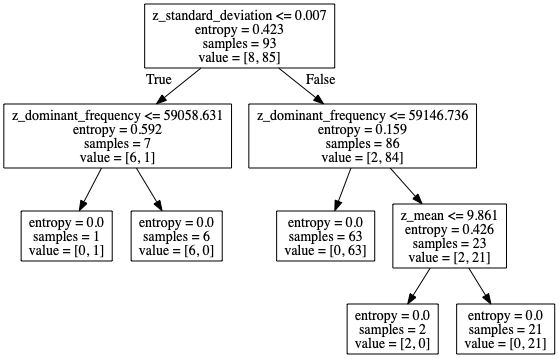
best_classifier.fit(X,Y) export_graphviz(tree, out_file='tree-random.dot', feature_names = feature_names)classifier_filename='classifier.pickle'print("Saving best classifier")with open(classifier_filename, 'wb') as f:pickle.dump(best_classifier, f)And after exporting the tree file with graphviz, we can actually visualize how the random forest tree looks like after training it.
在使用graphviz导出树文件之后,我们实际上可以直观地看到随机森林树经过训练后的样子。
最后结果(Final Result)
And voila! We are done with our classifier, and the next step is just running the program and the Android app for the full demonstration of the app. For this, I have made a video demonstration of the program working.
瞧! 我们已经完成了分类器的工作,下一步就是运行程序和Android应用程序以进行应用程序的完整演示。 为此,我已经对该程序的工作进行了视频演示。
演示地址
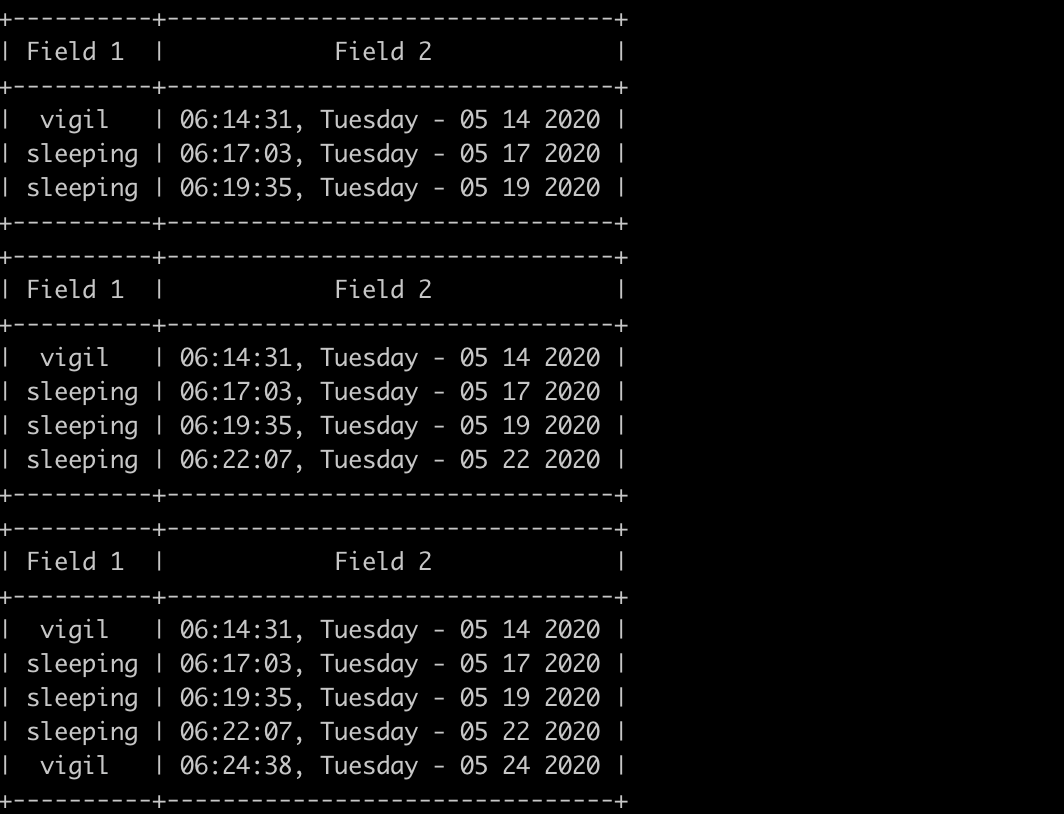
Here are also some of the outputs that is generated by the program;
这也是程序生成的一些输出。

Difficulties
难点
It was hard but we are done! I am very proud that we finished this project, although we did encounter some difficulties while making this project, such as;
很难,但是我们完成了! 尽管完成该项目确实遇到了一些困难,但我为完成该项目感到自豪。
- Script would have to run for the whole night to collect sleeping data so the CSV file was very large which meant that it would took a long time to process and graph the data 脚本必须整夜运行以收集睡眠数据,因此CSV文件非常大,这意味着需要很长时间来处理和绘制数据图
- Data collection between two people is extremely difficult as a lot of people will have different sleeping postures, etc.两个人之间的数据收集非常困难,因为许多人的睡眠姿势等会有所不同。
- Occasionally, the final timestamp on the CSV file would be before we woke up, meaning the script ended in the middle of the night 有时候,CSV文件的最终时间戳记是在我们醒来之前,这意味着脚本在深夜结束
- Since data collection are only done by the two of us (and comes with the problems mentioned above) , there is the case of not having enough data to train由于数据收集仅由我们两个人完成(并且存在上面提到的问题),因此存在无法训练足够数据的情况
- Creating a sleep-dedicated page on Android proved difficult, especially when sending messages to the Python script.在Android上创建睡眠专用页面非常困难,尤其是在向Python脚本发送消息时。
Overall, I am proud on how this project turned out. I certainly learned a lot of things, such as data collection in Android, extracting features from a dataset, using the scikitlearn library, and understanding how a Decision Tree Classifier works just to name a few.
总体而言,我对这个项目的结果感到骄傲。 我当然学到了很多东西,例如Android中的数据收集,使用scikitlearn库从数据集中提取特征以及了解决策树分类器的工作原理,仅举几例。
If you made it this far then I certainly hope you’ve enjoyed the read and I hope to create more write-ups like this soon. Thank you for reading!
如果您走了这么远,那么我当然希望您喜欢阅读,也希望不久以后能创建更多这样的文章。 感谢您的阅读!
翻译自: https://medium.com/@bima.jenie/tracking-sleep-using-your-phone-and-machine-learning-5d313a9d811d
机器人跟踪
相关文章

活动 | 腾讯×Nature Research:提问AI与机器人的未来

机器人影视对接_机器学习对接会

【AI视野·今日Robot 机器人论文速览 第十六期】Tue, 29 Jun 2021
![[Linux]基于网络编程的智能机器小伴侣](https://img-blog.csdnimg.cn/20190720235132303.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3pob25nX3NlbnZp,size_16,color_FFFFFF,t_70)
[Linux]基于网络编程的智能机器小伴侣

【AI视野·今日Robot 机器人论文速览 第十三期】Wed, 23 Jun 2021

为什么你买不到一台好用的机器人?因为没有你的代码
活动 | 腾讯×Nature Research:42问AI与机器人的未来
十款最具发展前景机器人

智搜盘点:来看看各大公司都推出了哪些机器人?

20篇聊天机器人领域必读论文速递!
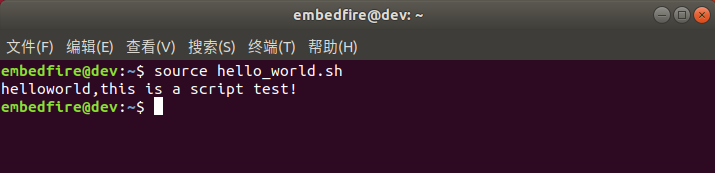
野火i.MX Linux开发实战指南
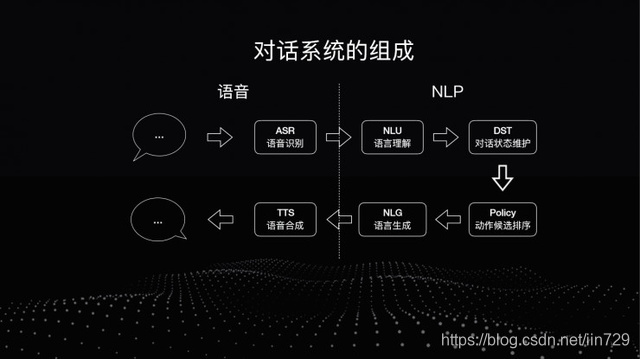
让你的MSN更精彩!聊天伴侣小i机器人试用体验
讯飞离线语音命令词+TTS离线发音,实现命令词交互(windows dll for unity插件)

【Qbot】6.讯飞文字转语音Api使用/VITS派蒙复读机实现

android免费离线讯飞语音合成
Linux下 python调用讯飞离线语音合成(tts)

使用讯飞tts+ffmpeg自动生成视频
构建简单的智能客服系统(三)——基于 UniMRCP 实现讯飞 TTS MRCP Server
