文章目录
- 🍳 前言
- 一、求字符串长度
- 💦 strlen
- 二、长度不受限制的字符串函数
- 💦 strcpy
- 💦 strcat
- 💦 strcmp
- 三、长度受限制的字符串函数
- 💦 strncpy
- 💦 strncat
- 💦 strncmp
- 四、字符串查找
- 💦 strstr
- 💦 strtok
- 五、错误信息报告
- 💦 strerror
- 💦 perror
- 六、字符操作函数
- 1、字符分类函数
- 💦 isdigit
- 💦 islower
- 2、字符转换函数
- 💦 tolower
- 七、内存操作函数
- 💦 memcpy
- 💦 memmove
- 💦 memset
- 💦 memcmp
- 八、函数的模拟实现
- 💦 strlen
- 1、计数器的版本(需要临时变量)
- 2、递归版本(不使用临时变量)
- 3、指针版本(指针-指针)
- 💦 strcpy
- 💦 strcat
- 💦 strstr
- 💦 strcmp
- 💦 memcpy
- 💦 memmove
🍳 前言
C语言对于字符和字符串的处理是很频繁的,但是C语言本身没有字符串类型,字符串通常放在常量字符串或者字符数组中。
一、求字符串长度
💦 strlen
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{char arr1[] = "abc";char arr2[] = { 'a', 'b', 'c' };printf("arr1的长度是:%d\n", strlen(arr1));printf("arr2的长度是:%d\n", strlen(arr2));return 0;
}
⭕ 输出结果:

📝 分析结果:
▶ “abc” 这种类型的字符串有4个元素 - > ‘a’ ‘b’ ‘c’ ‘\0’
这里说明了strlen这个函数在求字符串长度时计算的是 ‘\0’ 之前的字符,且以 ‘\0’ 为字符串的结束标志
▶ { ‘a’, ‘b’, ‘c’ } 这种类型的字符串只有3个元素 -> ‘a’, ‘b’, ‘c’
这里的结果是一个随机数,因为字符串里并没有 ‘\0’ 作为结束标志,所以它会继续往下数
❓ 观察以下代码,输出的结果是什么
#include<string.h>
#include<stdio.h>
int main()
{if(strlen("abc") - strlen("abcdef") > 0){printf(">\n");}else{printf("<\n");}return 0;
}
⭕ 输出结果:

📝 分析结果:

strlen函数的返回值类型无符号的
💨 总结:
▶ 字符串以 ‘\0’ 作为结束标志,strlen函数的返回值是在字符串中 ‘\0’ 前面出现的字符个数(不包含 ‘\0’ )
▶ 参数指向的字符必须要以 ‘\0’ 结束
▶ 注意函数的返回值为size_t,是无符号的(易错)
二、长度不受限制的字符串函数
💦 strcpy
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
int main()
{char arr[20] = { 0 };strcpy(arr, "hello");printf("%s\n", arr);return 0;
}
⭕ 输出结果:hello
📝 分析结果:strcpy会把源字符串中的内容拷贝到目标空间,并返回目标空间的起始位置
❓ strcpy在拷贝的过程中是以 ‘\0’ 为结束标志吗
📐 验证如下
#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "##########";char arr2[] = "ab\0cdef";strcpy(arr1, arr2);return 0;
}
⭕ 结果:
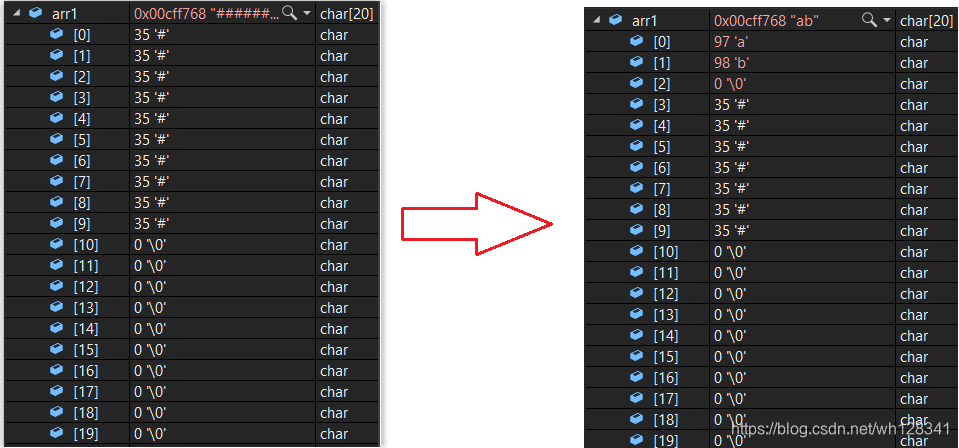
📝 分析:
strcpy在拷贝字符串时是以’\0’为标志的,且会将’\0’也拷贝
❓ 当原字符串要拷贝的空间比目标字符串的空间大时
#include<stdio.h>
#include<string.h>
int main()
{char arr[5] = { 0 };char* p = "hello world";strcpy(arr, p);printf("%s\n", arr);return 0;
}
⭕ 结果:
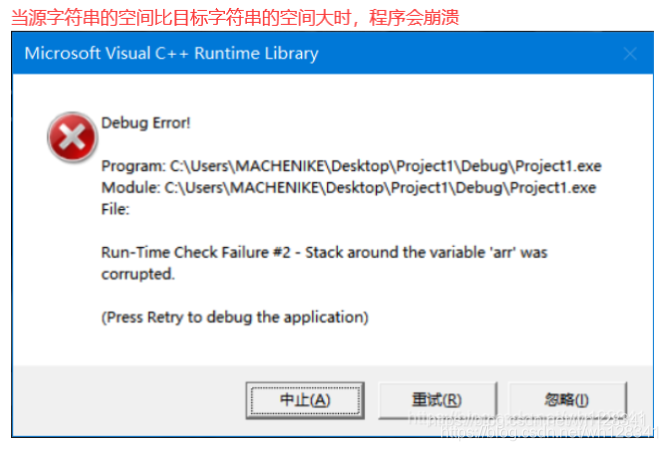
❓ 目标空间为常量字符串时
#include<stdio.h>
#include<string.h>
int main()
{char* str = "xxxxxxxxxx";char* p = "hello world";strcpy(str, p);printf("%s\n", str);return 0;
}
⭕ 结果:
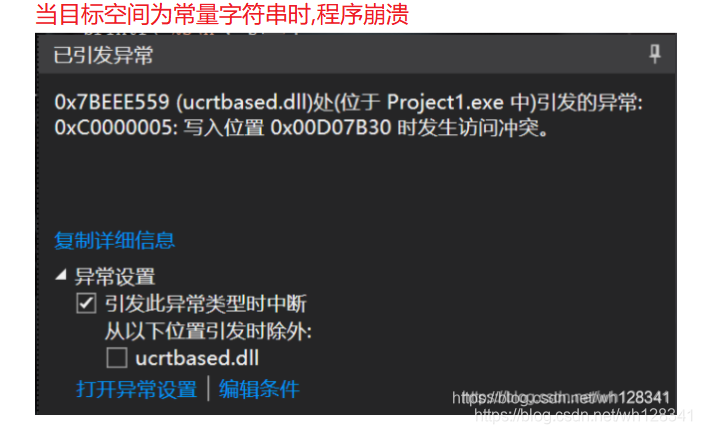
💨 总结:
▶ 源字符串必须以 ‘\0’ 结束
▶ strcpy在拷贝的过程中是以 ‘\0’ 为结束标志,且会将 ‘\0’ 也拷贝
▶ 目标空间必须足够大,以确保能存放源字符串
▶ 目标空间必须可变
💦 strcat
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
int main()
{char arr1[20] = "hello";char arr2[] = "bit";strcat(arr1, arr2);printf("%s\n", arr1);return 0;
}
⭕ 输出结果:

📝 分析结果:
从结果可以知道源字符串在追加时会找到目标字符串最后的 ‘\0’ 并将它给覆盖,然后开始追加
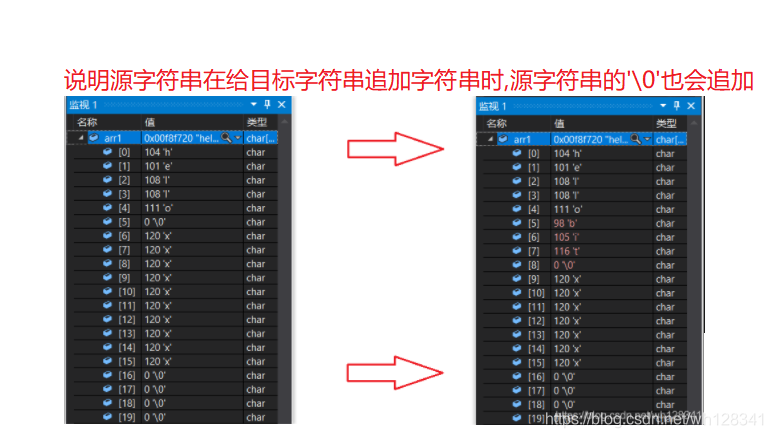
❓ 在源字符串追加给目标字符串时,源字符串的 ‘\0’ 会不会也追加
📐 验证如下
#include<stdio.h>
int main()
{char arr1[20] = "hello\0xxxxxxxxxx";char arr2[] = "bit";strcat(arr1, arr2);printf("%s\n", arr1);return 0;
}
⭕ 结果:
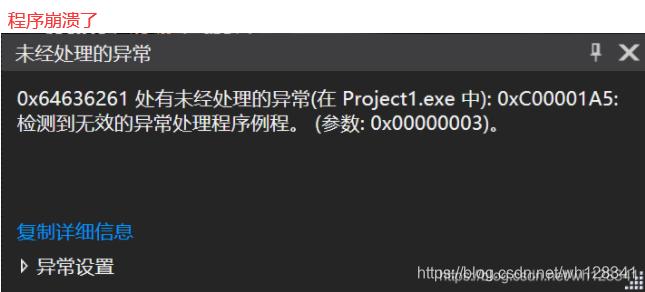
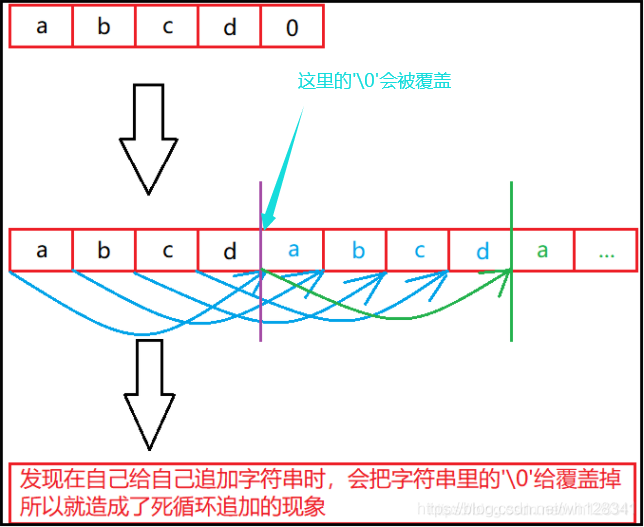
❓ strcat能不能自己给自己追加
#include<stdio.h>
int main()
{char arr[20] = "abcd";strcat(arr, arr);//?printf("%s\n", arr);return 0;
}
⭕ 结果:
📝 分析:
💨 总结:
▶ 源字符串必须以 ‘\0’ 结束
▶ 目标空间必须足够大,以足以容纳字符串
▶ 目标字符串必须可修改
▶ 不能自己追加自己
💦 strcmp
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

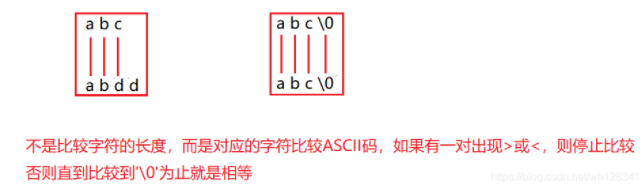
❌ 字符串的比较
#include<stdio.h>
#include<string.h>
int main()
{char* p1 = "def";char* p2 = "abc";if(p1 > p2)printf(">\n");else printf("<\n");return 0;
}
📝 分析:

✔ 字符串的比较
#include<stdio.h>
#include<string.h>
int main()
{char* p1 = "def";char* p2 = "abcdef";printf("%d\n", strcmp(p1, p2));return 0;
}
📝 分析:
三、长度受限制的字符串函数
💦 strncpy
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "abcdef";char arr2[] = "qwer";strncpy(arr1, arr2, 2);printf("%s\n", arr1);return 0;
}
⭕ 结果:

❓ 当指定的个数num大于源字符串时
#include<stdio.h>
#include<string.h>
int main()
{char arr1[20] = "abcdef";char arr2[] = "qwe";strncpy(arr1, arr2, 6);printf("%s\n", arr1);return 0;
}
⭕ 结果:

💨 总结:
▶ 拷贝num个字符从源字符串到目标空间
▶ 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后面追加0,直到num个
💦 strncat
🔗 函数原型和头:

🔗 函数的返回值:
🔗 功能:

#include<stdio.h.>
#include<string.h>
int main()
{char arr1[20] = "hello ";char arr2[] = "world";strncat(arr1, arr2, 3);printf("%s\n", arr1);return 0;
}
⭕ 结果:
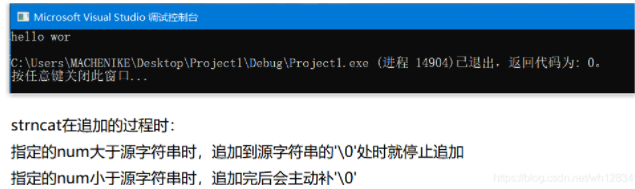
❓ strncat能否自己给自己追加
#include<stdio.h.>
#include<string.h>
int main()
{char arr1[20] = "hello";strncat(arr1, arr1, 6);printf("%s\n", arr1);return 0;
}
⭕ 结果和分析:

💦 strncmp
🔗 函数原型和头:

🔗 函数的返回值:
🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{char* p1 = "abcdef";char* p2 = "abcpdf";int ret = strncmp(p1, p2, 4);printf("%d\n", ret);return 0;
}
⭕ 结果:

四、字符串查找
💦 strstr
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{char arr1[] = "abcdefabcdef";char arr2[] = "bcd";char* ret = strstr(arr1, arr2);if(ret == NULL)printf("没找到\n");elseprintf("找到了:%s\n", ret);return 0;
}
⭕ 结果:

📝 分析:
strstr在目标字符串中查找子串,如果找到了就返回目标字符串中首次出现的源字符串的地址,否则返回一个空指针
💦 strtok
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

🔗 函数详解:
▶ strDelimit的参数是一个字符串,定义了用作分隔符的字符集合
▶ strToken指定一个字符串,它包含了0个或者多个由strDelimit串中一个或者多个分隔符分割的标记
▶ strtok函数找到strToken中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改)
▶ strtok函数的第一个参数不为NULL,函数将找到strToken中的第一个标记,strtok函数将保存它在字符串中的位置
▶ strtok函数的第一个参数为NULL,函数将在同一个字符串中被保存的位置开始,查找下一个标记
▶ 如果字符串中不存在更多的标记,则返回NULL指针
▶ strtok函数被调用一次,只会切割一次,所以想要切割多次,就需要多次调用
#include<stdio.h>
#include<string.h>
int main()
{char arr[] = "wanghong@deboke.csdn";char* p = "@.";char temp[30] = { 0 };//拷贝一份arr于temp,让temp去切割strcpy(temp, arr);char* ret = NULL;ret = strtok(temp, p);printf("%s\n", ret);ret = strtok(NULL, p);printf("%s\n", ret);ret = strtok(NULL, p);printf("%s\n", ret);return 0;
}
⭕ 结果与分析:

✔ 但是我们通常会将多次分割的这个操作使用循环来实现,非常的妙啊 !!!
#include<stdio.h>
#include<string.h>
int main()
{char arr[] = "wanghong@deboke.csdn";char* p = "@.";char temp[30] = { 0 };strcpy(temp, arr);char* ret = NULL;for(ret = strtok(temp, p); ret != NULL; ret = strtok(NULL, p)){printf("%s\n", ret);}return 0;
}
五、错误信息报告
💦 strerror
🔗 函数原型和头:

🔗 函数的返回值:
🔗 功能:

🔗 函数详解:
在调用库函数失败时,都会设置错误码
C语言中有一个全局的错误码 -> int errno ,只要调用库函数发生了错误,就会把错误码放到errno里去
这里strerror就会把错误码翻译成对应的错误信息,然后再把错误信息以字符串首地址返回回来
通常strerror都会和errno一起使用
使用errno需要头文件errno.h
#include<stdio.h>
#include<string.h>
int main()
{printf("%s\n", strerror(0));printf("%s\n", strerror(1));printf("%s\n", strerror(2));printf("%s\n", strerror(3));printf("%s\n", strerror(4));printf("%s\n", strerror(5));return 0;
}
⭕ 结果与分析:

❓ 具体是怎么用的
注:以下所使用的对文件操作的一些函数会在后面进行了解
#include<stdio.h>
#include<string.h>
#include<errno.h>
int main()
{//以读的形式打开test.txt文件,这个文件如果不存在就会打开失败,然后返回一个空指针FILE* pf = fopen("test.txt", "r");//失败就输出失败的原因,也就题错误信息if(pf == NULL){printf("%s\n", strerror(errno)); return 1;}//...fclose(pf);//关闭文件pf == NULL;return 0;
}
⭕ 结果:

💦 perror
🔗 函数原型和头:

🔗 函数的返回值:
🔗 功能:

#include<stdio.h>
#include<stdio.h>
int main()
{FILE* pf = fopen("test.txt", "r");if(pf == NULL){perror("fopen"); return 1;}//...fclose(pf);pf == NULL;return 0;
}
⭕ 结果与分析:

六、字符操作函数
1、字符分类函数

🧿 注:简单介绍几个,其余的函数可以照猫画虎
💦 isdigit
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<ctype.h>
int main()
{char ch = '@';//如果是数字字符返回非0的值,否则返回0int ret = isdigit(ch);printf("%d\n", ret);return 0;
}
💦 islower
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<ctype.h>
int main()
{char ch = 'A';//如果是小写字母返回非0的值,否则返回0int ret = islower(ch);printf("%d\n", ret);return 0;
}
2、字符转换函数
| 函数 | 功能 |
|---|---|
| tolower | 大写转小写 |
| toupper | 小写转大写 |
💦 tolower
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<ctype.h>
int main()
{char arr[20] = { 0 };scanf("%s", arr);int i = 0;while(arr[i] != '\0'){printf("%c ", tolower(arr[i]));i++;}return 0;
}
⭕ 结果:

七、内存操作函数
💦 memcpy
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };int arr2[20] = { 0 };memcpy(arr2, arr1, 20);//注意第3个参数的单位是字节return 0;
}
⭕ 结果:

❓ 我们注意到memcpy的前2个参数是void*类型的,那是不是说它可以拷贝不同的数据
#include<stdio.h>
#include<string.h>
int main()
{char arr1[] = "abcdef";char arr2[20] = { 0 };memcpy(arr2, arr1, 6);printf("%s\n", arr2);return 0;
}
⭕ 结果:

❓ 对于strcpy函数在拷贝字符串时,如果遇到’\0’它会停止拷贝,那么思考memcpy在拷贝字符串时遇到’\0’是否也会停止
#include<stdio.h>
#include<string.h>
int main()
{char arr1[] = "abc\0def";char arr2[20] = { 0 };memcpy(arr2, arr1, 6);printf("%s\n", arr2);return 0;
}
⭕ 结果:

这里有一个场景 ❓

#include<stdio.h>
#include<string.h>
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };memcpy(arr1 + 2, arr1, 20);return 0;
}
⭕ 结果与分析:

💦 memmove
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };memmove(arr1 + 2, arr1, 20);return 0;
}
⭕ 结果与分析:

💦 memset
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{int arr[10] = { 0 };memset(arr, 1, 20);return 0;
}
⭕ 结果与分析:

❓ 使用memset设置一个10个元素的数组的元素为1
#include<stdio.h>
#include<string.h>
int main()
{int arr[10] = { 0 };int i = 0;for (i = 0; i < 10; i++){memset(&arr[i], 1, 1);}return 0;
}
⭕ 结果:

💦 memcmp
🔗 函数原型和头:

🔗 函数的返回值:

🔗 功能:

#include<stdio.h>
#include<string.h>
int main()
{float arr1[] = { 1.0, 2.0, 3.0, 4.0 };float arr2[] = { 1.0, 3.0 };int ret = memcmp(arr1, arr2, 8);//注意第3个参数的单位是字节printf("%d\n", ret);return 0;
}
八、函数的模拟实现
💦 strlen
1、计数器的版本(需要临时变量)
#include<stdio.h>
int my_strlen(char* str)
{int count = 0;while(*str != '\0'){count++;str++;}return count;
}
int main()
{char arr[] = "abc";int len = my_strlen(arr);printf("%d\n", len);return 0;
}
❗ 缺陷和不足:
❌ 在my_strlen函数里对指针直接进行解引用这是不安全的,因为指针一定得是有效的
❌ my_strlen函数的功能是求字符串的长度,而这个my_strlen函数有权限去改变字符串里的内容,因此这是不安全的
❌ my_strlen这个函数的返回值是int,如果返回的是一个负数,那可能就当场懵逼
💯优化
✔ 使用断言assert,需要引头文件<assert.h>
✔ 使用const对str进行限制
✔ 将函数的返回值int更改为size_t
✔ 对代码整体进行更简洁的优化
#include<stdio.h>
#include<assert.h>
size_t my_strlen(const char* str)
{assert(str != NULL);int count = 0;while (*str++)count++;return count;
}
int main()
{char arr[] = "abc";printf("%d\n", my_strlen(arr));return 0;
}
2、递归版本(不使用临时变量)
#include<stdio.h>
#include<assert.h>
int my_strlen(const char* str)
{assert(str);if(*str)return 1 + my_strlen(str+1);else return 0;
}
int main()
{char arr[] = "abc";printf("%d\n", my_strlen(arr));return 0;
}
3、指针版本(指针-指针)
字符串长度 = '\0’的地址 - 首元素的地址
#include<stdio.h>
#include<assert.h>
int my_strlen(char* first, char* end)
{assert(first);assert(end);return end - first;
}
int main()
{char arr[] = "abc";int left = 0;int right = sizeof(arr)/sizeof(arr[0]) - 1;printf("%d\n", my_strlen(&arr[left], &arr[right]));return 0;
}
💦 strcpy
#include<stdio.h>
#include<assert.h>
void my_strcpy(char* dest, char* src)
{while(*src != 0){*dest = *src;dest++;src++;}src = 0;//将str1的最后一个元素拷贝为0
}
int main()
{char arr1[20] = { 0 };char arr2[] = "hello bit";my_strcpy(arr1, arr2);printf("%s\n", arr1);return 0;
}
❗ 缺陷和不足:
❌ 在my_strcpy函数里对指针直接进行解引用这是不安全的,因为指针一定得是有效的
❌对于my_strcpy这个函数的2个参数,其一是目标字符串,其二是源字符串,目标字符串必须保证可被修改,而源字符串不能被修改
❌ 这里是先把除 ‘\0’ 其它字符先拷贝,再拷贝 ‘\0’
❌ 这个函数的返回值是void,而在库里是char*,返回的是目标字符串的首地址 :

💯优化
✔ 使用断言assert,需要引头文件<assert.h>
✔ 使用const对str2进行限制
✔ 将 ‘\0’ 和其它字符一起进行拷贝
✔ 将函数的返回值设置为char*
#include<stdio.h>
#include<assert.h>
char* my_strcpy(char* dest, const char* src)
{assert(dest);assert(src);char* temp = dest;//备份一份首地址while (*dest++ = *src++){;}return temp;//返回备份的首地址
}
int main()
{char arr1[20] = { 0 };char arr2[] = "hello bit";printf("%s\n", my_strcpy(arr1, arr2));return 0;
}
💦 strcat
#include<stdio.h>
#include<assert.h>
char* my_strcat(char* dest, const char* src)
{assert(dest && src);char* temp = dest;//备份一份首地址 //找到目标字符串中的'\0'while(*dest){dest++;}while(*dest++ = *src++){;}return temp;//返回首地址
}
int main()
{char arr1[20] = "hello";char arr2[] = "bit";printf("%s\n", my_strcat(arr1, arr2));return 0;
}
💦 strstr
#include<stdio.h>
#include<assert.h>
char* my_strstr(const char* father, const char* son)
{assert(father && son);const char* f1 = NULL; const char* s2 = NULL;const char* ret = father; while(*ret){f1 = ret;s2 = son;if(*son == '\0'){return (char*)father;}while(*f1 && *s2 && (*f1 == *s2)){f1++;s2++; }if(*s2 == '\0'){return (char*)ret;}ret++;}return NULL;
}
int main()
{char arr1[] = "abbbcdef";char arr2[] = "bbc";char* ret = my_strstr(arr1, arr2);if(ret == NULL){printf("没找到\n");} else{printf("找到了:%s\n", ret);}return 0;
}
⭕ 分析:
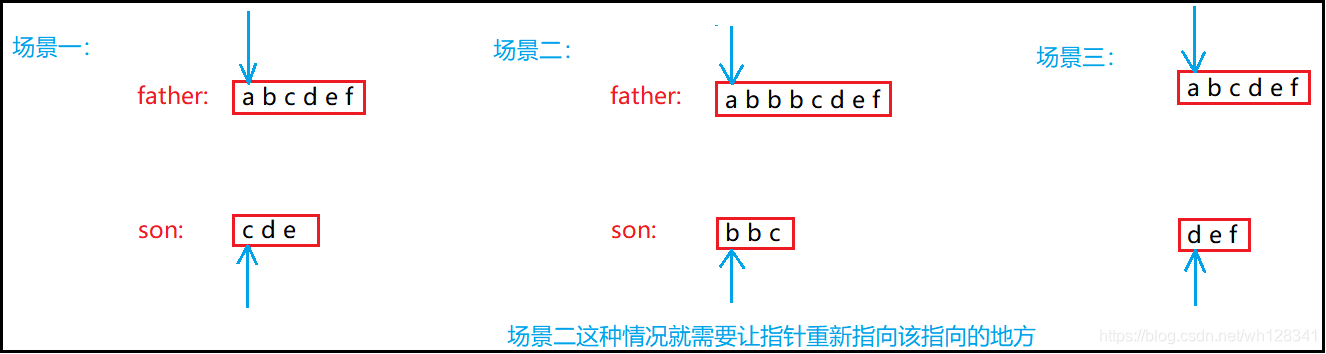
▶ 考虑到如果查找失败的情况,不一定是找不到子串,所以要从新再匹配直到*father == '\0’就找不到子串
▶ 需要定义2个指针f1(指向father首地址)和s2(指向son首地址)来帮我们往下去匹配
▶ 如果匹配失败指针要回到该回到的地方
对于s2:s2 = son
对于f1:这里就还需要另1个指针ret(指向fther首地址)来记录,每一次匹配失败,都让ret++,然后f1 = ret
🍳拓展:KMP算法 - 字符串查找算法 - 大家可以了解一下
💦 strcmp
#include<stdio.h>
#include<assert.h>
int my_strcmp1(const char* str1, const char* str2)
{assert(str1 && str2);while(1){if(*str1 > *str2)return 1;else if(*str1 < *str2)return -1;else{if(*str1 == *str2 && *str1 == '\0')return 0;else{str1++;str2++; }} }
}
int my_strcmp2(const char* str1, const char* str2)
{assert(str1 && str2);while(*str1 == *str2){if(*str1 == '\0')return 0;str1++;str2++;} if(*str1 > *str2)return 1;elsereturn -1;
}int main()
{char* p1 = "def";char* p2 = "abcdef";//int ret = my_strcmp1(p1, p2);//版本1int ret = my_strcmp2(p1, p2);//版本2if(ret > 0)printf("p1 > p2\n");else if (ret < 0)printf("p1 < p2\n");else printf("p1 = p2\n");return 0;
}
⭕ 优化冗余:
#include<stdio.h>
#include<assert.h>
int my_strcmp(const char* str1, const char* str2)
{assert(str1 && str2);while(*str1 == * str2){if(*str1 == '\0')return 0;str1++;str2++;}return *str1 - *str2;
}
int main()
{char* p1 = "def";char* p2 = "abcdef";int ret = my_strcmp(p1, p2);if(ret > 0)printf("p1 > p2\n");else if (ret < 0)printf("p1 < p2\n");else printf("p1 = p2\n");return 0;
}
💦 memcpy
#include<stdio.h>
#include<assert.h>
void* my_memcpy(void* dest, const void* src, size_t num)
{assert(dest && src);void* ret = dest;while(num--){/**(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;*/*((char*)dest)++ = *((char*)src)++;}return ret;
}
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };int arr2[20] = { 0 };my_memcpy(arr2, arr1, 20);
}
❗ 注意:

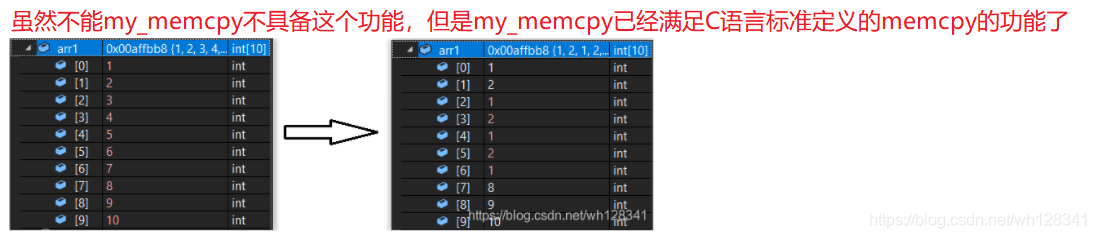
❓ my_memcpy能否拷贝重叠的内存空间
#include<stdio.h>
#include<assert.h>
void* my_memcpy(void* dest, const void* src, size_t num)
{assert(dest && src);void* ret = dest;while(num--){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;}return ret;
}
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };my_memcpy(arr1 + 2, arr1, 20);
}
⭕ 结果:
💦 memmove
❓ 相信小伙伴们都很好奇memmove是怎么处理内存重叠的情况的
🔎 分析一波

#include<stdio.h>
#include<assert.h>
void* my_memmove(void* dest, const void* src, size_t num)
{assert(dest && src);void* ret = dest;if(dest < src){//从前向后拷贝while(num--){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;}}else{//从后向前拷贝while(num--){*((char*)dest + num) = *((char*)src + num); }}return ret;
}
int main()
{int arr1[10] = { 1,2,3,4,5,6,7,8,9,10 };my_memmove(arr1 + 2, arr1, 20);return 0;
}