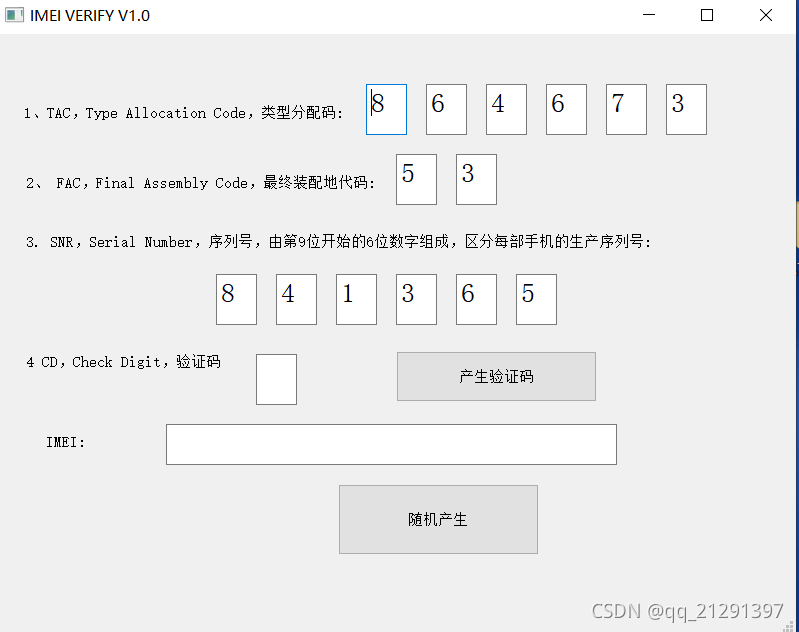
下面结合官方文档和实验介绍下HWM:
以下英文摘自11gR2官方文档:
HWM(high water mark):The boundary between used and unused space in a segment.
ORACLE9i之后开始使用自动段空间管理即ASSM,它使用位图来管理段空间的使用情况,如果表空间ASSM,则表空间中的段也是ASSM.
At table creation, the HWM is at the beginning of the segment on the left. Because no data has been inserted yet, all blocks in the segment are unformatted and never used.
当表创建时,HWM开始于段的最左边。因为从来没有数据插入,所有在段里的块没有被格式化和使用。

Suppose that a transaction inserts rows into the segment. The database must allocate a group of blocks to hold the rows. The allocated blocks fall below the HWM. The database formats a bitmap block in this group to hold the metadata, but does not preformat the remaining blocks in the group.In Figure 12–24, the blocks below the HWM are allocated, whereas blocks above the HWM are neither allocated or formatted. As inserts occur, the database can write to any block with available space. The low high water mark (low HWM) marks the point below which all blocks are known to be formatted because they either contain data or formerly contained data.
假设一个事务将行插入到段。数据库必须分配一个组块的行。低于HWM分配的块。这组数据库格式的位图块的元数据,但不预先格式剩下的组块。在图12 - 24中,下面的块HWM分配,而块上面HWM既不分配或格式化。插入时,数据库可以写任何块可用空间。高水标低(低HWM)标志着点下面这所有的块都被格式化的,因为他们要么包含数据或以前包含数据。

In Figure 12–25, the database chooses a block between the HWM and low HWM and writes to it. The database could have just as easily chosen any other block between the HWM and low HWM, or any block below the low HWM that had available space. In Figure 12–25, the blocks to either side of the newly filled block are unformatted.
在图12-25,数据库选择HWM和低HWM和之间的一块写道。数据库也可以轻易选择其他块之间HWM和低HWM,或任何块低于低HWM可用空间。在图12-25,块的新填充块无格式。

The low HWM is important in a full table scan. Because blocks below the HWM arformatted only when used, some blocks could be unformatted, as in Figure 12–25. Fthis reason, the database reads the bitmap block to obtain the location of the low HWM. The database reads all blocks up to the low HWM because they are known tbe formatted, and then carefully reads only the formatted blocks between the low HWM and the HWM.Assume that a new transaction inserts rows into the table, but the bitmap indicates that insufficient free space exists under the HWM. In Figure 12–26, the database advances the HWM to the right, allocating a new group of unformatted blocks.
HWM低是重要的在一个全表扫描。因为块低于HWM基于“增大化现实”技术格式化只使用时,一些街区可以无格式,如图12-25所示。F因此,数据库读取位图块获得低的位置HWM。数据库读取所有块的低HWM因为它们是已知的被格式化,然后仔细阅读只有格式化块之间的低HWM HWM。假设一个新的事务将行插入到表中,但位图显示HWM空闲空间不足存在。图12-26数据库右边的HWM进步,分配一个新组的非格式化块。

When the blocks between the HWM and low HWM are full, the HWM advances to the right and the low HWM advances to the location of the old HWM. As the database inserts data over time, the HWM continues to advance to the right, with the low HWM always trailing behind it. Unless you manually rebuild, truncate, or shrink the object, the HWM never retreats.
当HWM之间的块和低HWM充满,HWM进步的正确的和低老HWM HWM进步的位置。作为数据库插入数据随着时间的推移,右边的HWM不断进步,HWM偏低总是落后。除非你手动重建、截断或缩小对象,HWM从不撤退。
以上通过官方文档理论的分析了HWM,下面我们通过实验来分析:
[oracle@localhost ~]$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 5.5 (Tikanga)
SQL> select * from v$version where rownum=1;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
SQL> show user;
USER 为 "HR"
SQL> desc t;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(38)
NAME VARCHAR2(10)
SQL> select count(*) from t;
COUNT(*)
----------
327680
SQL> exec dbms_stats.gather_table_stats('HR','T'); oracle提供了这个分析包
PL/SQL 过程已成功完成。
当然你也可以使用之前版本提供的工具:
SQL> analyze table t1 compute statistics;
表已分析。
表已分析。


上面的参数不一一介绍,感兴趣的可以研究。
通过执行计划分析:
SQL> set autotrace traceonly;
SQL> select * from t;(执行了两次,此为第二次结果)
已选择327680行。
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 327K| 2240K| 172 (2)| 00:00:03 |
| 1 | TABLE ACCESS FULL| T | 327K| 2240K| 172 (2)| 00:00:03 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
22418 consistent gets
0 physical reads
0 redo size
6379306 bytes sent via SQL*Net to client
240710 bytes received via SQL*Net from client
21847 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
327680 rows processed
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
从上面可以看出,逻辑读了22418次。
我们此时delete表t,但是不会降低HWM:


表t虽然被delete的那部分被删除,但是被占用的那部分内空间存仍然没被释放,可以通过alter table t move来释放存储空间:
alter table move 主要有两方面的作用:
表已更改。
此时rows的rowid也会改变。
SQL> select * from t; (执行了两次,此为第二次结果)
已选择131072行。
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 327K| 2240K| 172 (2)| 00:00:03 |
| 1 | TABLE ACCESS FULL| T | 327K| 2240K| 172 (2)| 00:00:03 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
9274 consistent gets
0 physical reads
0 redo size
4020151 bytes sent via SQL*Net to client
96533 bytes received via SQL*Net from client
8740 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
131072 rows processed
但是此时造成建立在id上的索引不可用:

此时我们可以通过重建索引来解决:
alter index index_t rebuild (tablespace users) online;(此时如果不加online,则不能进行delete,update,insert操作,对于大表来说,很慢)
SQL> alter index index_t rebuild online;
索引已更改。

以下英文摘自11gR2官方文档:
HWM(high water mark):The boundary between used and unused space in a segment.
ORACLE9i之后开始使用自动段空间管理即ASSM,它使用位图来管理段空间的使用情况,如果表空间ASSM,则表空间中的段也是ASSM.
At table creation, the HWM is at the beginning of the segment on the left. Because no data has been inserted yet, all blocks in the segment are unformatted and never used.
当表创建时,HWM开始于段的最左边。因为从来没有数据插入,所有在段里的块没有被格式化和使用。
Suppose that a transaction inserts rows into the segment. The database must allocate a group of blocks to hold the rows. The allocated blocks fall below the HWM. The database formats a bitmap block in this group to hold the metadata, but does not preformat the remaining blocks in the group.In Figure 12–24, the blocks below the HWM are allocated, whereas blocks above the HWM are neither allocated or formatted. As inserts occur, the database can write to any block with available space. The low high water mark (low HWM) marks the point below which all blocks are known to be formatted because they either contain data or formerly contained data.
假设一个事务将行插入到段。数据库必须分配一个组块的行。低于HWM分配的块。这组数据库格式的位图块的元数据,但不预先格式剩下的组块。在图12 - 24中,下面的块HWM分配,而块上面HWM既不分配或格式化。插入时,数据库可以写任何块可用空间。高水标低(低HWM)标志着点下面这所有的块都被格式化的,因为他们要么包含数据或以前包含数据。
In Figure 12–25, the database chooses a block between the HWM and low HWM and writes to it. The database could have just as easily chosen any other block between the HWM and low HWM, or any block below the low HWM that had available space. In Figure 12–25, the blocks to either side of the newly filled block are unformatted.
在图12-25,数据库选择HWM和低HWM和之间的一块写道。数据库也可以轻易选择其他块之间HWM和低HWM,或任何块低于低HWM可用空间。在图12-25,块的新填充块无格式。
The low HWM is important in a full table scan. Because blocks below the HWM arformatted only when used, some blocks could be unformatted, as in Figure 12–25. Fthis reason, the database reads the bitmap block to obtain the location of the low HWM. The database reads all blocks up to the low HWM because they are known tbe formatted, and then carefully reads only the formatted blocks between the low HWM and the HWM.Assume that a new transaction inserts rows into the table, but the bitmap indicates that insufficient free space exists under the HWM. In Figure 12–26, the database advances the HWM to the right, allocating a new group of unformatted blocks.
HWM低是重要的在一个全表扫描。因为块低于HWM基于“增大化现实”技术格式化只使用时,一些街区可以无格式,如图12-25所示。F因此,数据库读取位图块获得低的位置HWM。数据库读取所有块的低HWM因为它们是已知的被格式化,然后仔细阅读只有格式化块之间的低HWM HWM。假设一个新的事务将行插入到表中,但位图显示HWM空闲空间不足存在。图12-26数据库右边的HWM进步,分配一个新组的非格式化块。
When the blocks between the HWM and low HWM are full, the HWM advances to the right and the low HWM advances to the location of the old HWM. As the database inserts data over time, the HWM continues to advance to the right, with the low HWM always trailing behind it. Unless you manually rebuild, truncate, or shrink the object, the HWM never retreats.
当HWM之间的块和低HWM充满,HWM进步的正确的和低老HWM HWM进步的位置。作为数据库插入数据随着时间的推移,右边的HWM不断进步,HWM偏低总是落后。除非你手动重建、截断或缩小对象,HWM从不撤退。
以上通过官方文档理论的分析了HWM,下面我们通过实验来分析:
[oracle@localhost ~]$ cat /etc/redhat-release
Red Hat Enterprise Linux Server release 5.5 (Tikanga)
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
SQL> show user;
USER 为 "HR"
SQL> desc t;
名称 是否为空? 类型
----------------------------------------- -------- ----------------------------
ID NUMBER(38)
NAME VARCHAR2(10)
SQL> select count(*) from t;
COUNT(*)
----------
327680
t是用户hr里的一张比较大的表。
我们在列id上建索引index_t:(下面有用)
SQL> create index index_t on t(id);
索引已创建。
分析一下表: 我们在列id上建索引index_t:(下面有用)
SQL> create index index_t on t(id);
索引已创建。
SQL> exec dbms_stats.gather_table_stats('HR','T'); oracle提供了这个分析包
PL/SQL 过程已成功完成。
当然你也可以使用之前版本提供的工具:
SQL> analyze table t1 compute statistics;
表已分析。
删除分析:
SQL> analyze table t1 delete statistics; 表已分析。
Total Blocks 表示分配给表的总的blocks 数。
Unused Blocks 表示位于高水位线以上的从未使用的数据块个数。
通过执行计划分析:
SQL> set autotrace traceonly;
SQL> select * from t;(执行了两次,此为第二次结果)
已选择327680行。
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 327K| 2240K| 172 (2)| 00:00:03 |
| 1 | TABLE ACCESS FULL| T | 327K| 2240K| 172 (2)| 00:00:03 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
22418 consistent gets
0 physical reads
0 redo size
6379306 bytes sent via SQL*Net to client
240710 bytes received via SQL*Net from client
21847 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
327680 rows processed
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
从上面可以看出,逻辑读了22418次。
我们此时delete表t,但是不会降低HWM:
表t虽然被delete的那部分被删除,但是被占用的那部分内空间存仍然没被释放,可以通过alter table t move来释放存储空间:
alter table move 主要有两方面的作用:
1、用来移动table 到其他表空间。
2、用 来减少table 中的存储碎片,优化存储空间和性能。
SQL> alter table t move (tablespace users) online;(此时别的会话可以正常访问此表) 表已更改。
此时rows的rowid也会改变。
SQL> select * from t; (执行了两次,此为第二次结果)
已选择131072行。
执行计划
----------------------------------------------------------
Plan hash value: 1601196873
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 327K| 2240K| 172 (2)| 00:00:03 |
| 1 | TABLE ACCESS FULL| T | 327K| 2240K| 172 (2)| 00:00:03 |
--------------------------------------------------------------------------
统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
9274 consistent gets
0 physical reads
0 redo size
4020151 bytes sent via SQL*Net to client
96533 bytes received via SQL*Net from client
8740 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
131072 rows processed
此时的逻辑读已经降低为9274。
但是此时造成建立在id上的索引不可用:
此时我们可以通过重建索引来解决:
alter index index_t rebuild (tablespace users) online;(此时如果不加online,则不能进行delete,update,insert操作,对于大表来说,很慢)
SQL> alter index index_t rebuild online;
索引已更改。
索引重新可以使用: