一、如何下载科大讯飞语音听写的SDK包
1.1、注册下载语音听写SDK包
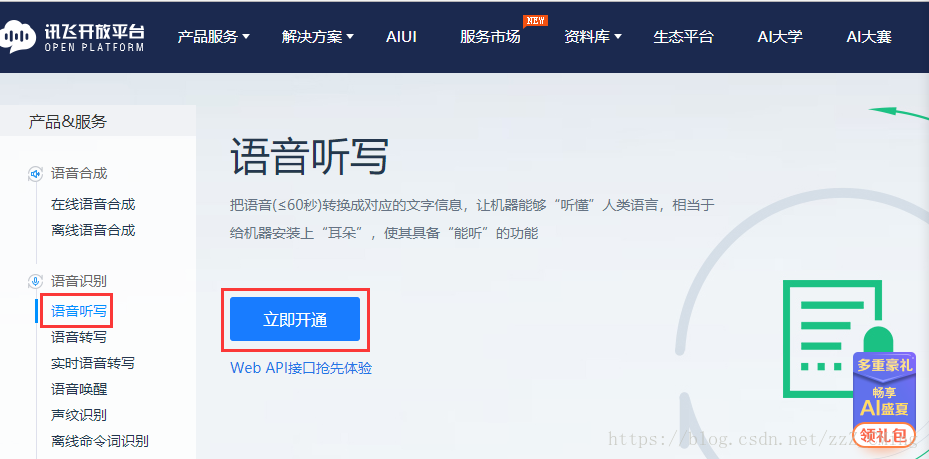
**第一步:**登录讯飞开放平台,找到产品服务——“语音听写”,点击“立即开通”
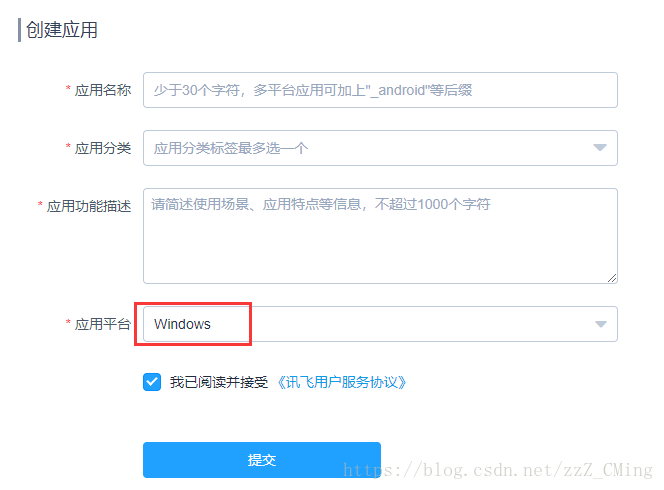
**第二步:**创建新应用
**第三步:**创建应用,填写信息,应用平台选择windows
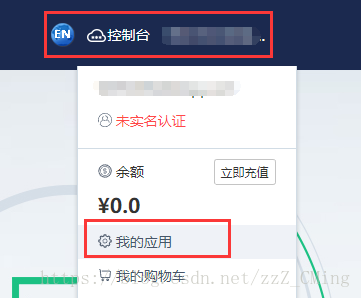
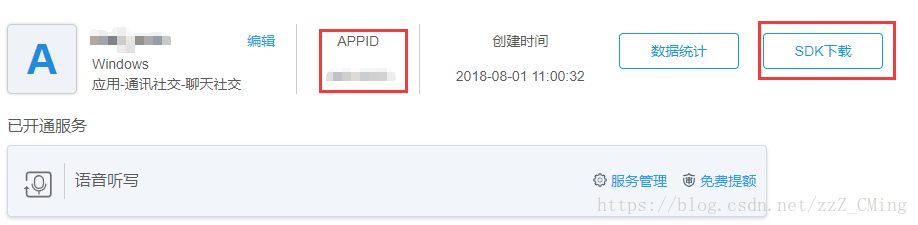
**第四步:**完成创建后,点击右上角控制台旁边你的登录名,点击我的应用,进入后就可以看到你注册的应用
**第五步:**注意你的APPID号,这个后来有用处,请注意,然后点击SDK下载
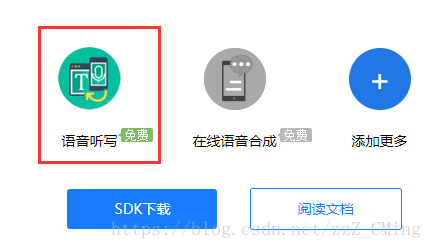
**第六步:**选择你的AL能力,勾选语音听写后,点击SDK下载
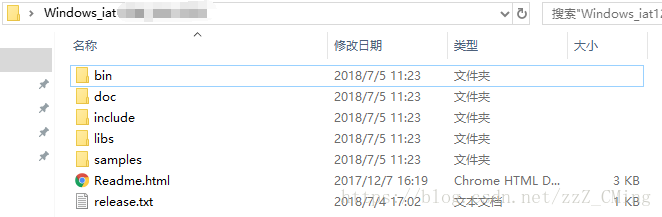
**第七步:**这时候你会从网上得到一个压缩包,为方便查看,你新建一个和这个SDK压缩包名字一样的文件夹(这个文件名后面有用处),再将包内的所有文件拖入新建的文件夹中,得到如下文件夹,到这里,语音听写的SDK包就下载完成了。

二、调用科大讯飞语音听写的SDK包
新建keda_API.py文件,将如下代码写入,并将你的APPID号、文件夹名,在21行、23行位置进行修改
还有特别说明在代码后,不看你会出错的,一定要看
还有特别说明在代码后,不看你会出错的,一定要看
# -*- coding:utf-8 -*-
# -*- author:zzZ_CMing CSDN address:https://blog.csdn.net/zzZ_CMing
# -*- 2018/08/11; 10:19
# -*- python3.5
"""
参考代码地址:https://blog.csdn.net/fang_yang_wa/article/details/78791137
"""
from ctypes import *
import time
import win32com.clientFRAME_LEN = 640 # Byte
MSP_SUCCESS = 0
# 返回结果状态
MSP_AUDIO_SAMPLE_FIRST = 1
MSP_AUDIO_SAMPLE_CONTINUE = 2
MSP_AUDIO_SAMPLE_LAST = 4
MSP_REC_STATUS_COMPLETE = 5# 调用动态链接库
dll = cdll.LoadLibrary("../SDK文件名/bin/msc_x64.dll")
# 登录参数,apppid一定要和你的下载SDK对应
login_params = b"appid = 你的APPID号, work_dir = SDK文件名."class Msp:def __init__(self):passdef login(self):ret = dll.MSPLogin(None, None, login_params)# print('MSPLogin =>', ret)def logout(self):ret = dll.MSPLogout()# print('MSPLogout =>', ret)def isr(self, audiofile, session_begin_params):ret = c_int()sessionID = c_voidp()dll.QISRSessionBegin.restype = c_char_psessionID = dll.QISRSessionBegin(None, session_begin_params, byref(ret))#print('QISRSessionBegin => sessionID:', sessionID, '\nret:', ret.value)# 每秒【1000ms】 16000 次 * 16 bit 【20B】 ,每毫秒:1.6 * 16bit 【1.6*2B】 = 32Byte# 1帧音频20ms【640B】 每次写入 10帧=200ms 【6400B】# piceLne = FRAME_LEN * 20piceLne = 1638 * 2epStatus = c_int(0)recogStatus = c_int(0)wavFile = open(audiofile, 'rb')wavData = wavFile.read(piceLne)ret = dll.QISRAudioWrite(sessionID, wavData, len(wavData), MSP_AUDIO_SAMPLE_FIRST, byref(epStatus),byref(recogStatus))#print('len(wavData):', len(wavData), '\nQISRAudioWrite ret:', ret,'\nepStatus:', epStatus.value, '\nrecogStatus:', recogStatus.value)time.sleep(0.1)while wavData:wavData = wavFile.read(piceLne)if len(wavData) == 0:breakret = dll.QISRAudioWrite(sessionID, wavData, len(wavData), MSP_AUDIO_SAMPLE_CONTINUE, byref(epStatus),byref(recogStatus))# print('len(wavData):', len(wavData), 'QISRAudioWrite ret:', ret, 'epStatus:', epStatus.value, 'recogStatus:', recogStatus.value)time.sleep(0.1)wavFile.close()ret = dll.QISRAudioWrite(sessionID, None, 0, MSP_AUDIO_SAMPLE_LAST, byref(epStatus), byref(recogStatus))# print('len(wavData):', len(wavData), 'QISRAudioWrite ret:', ret, 'epStatus:', epStatus.value, 'recogStatus:', recogStatus.value)#print("\n所有待识别音频已全部发送完毕\n获取的识别结果:")# -- 获取音频laststr = ''counter = 0while recogStatus.value != MSP_REC_STATUS_COMPLETE:ret = c_int()dll.QISRGetResult.restype = c_char_pretstr = dll.QISRGetResult(sessionID, byref(recogStatus), 0, byref(ret))if retstr is not None:laststr += retstr.decode()#print('333',laststr)# print('ret:', ret.value, 'recogStatus:', recogStatus.value)counter += 1time.sleep(0.2)counter += 1"""if counter == 50:laststr += '讯飞语音识别失败'break"""#print(laststr)# 不知道为什么注解了?#ret = dll.QISRSessionEnd(sessionID, '\0')# print('end ret: ', ret)return laststrdef XF_text(filepath, audio_rate):msp = Msp()#print("登录科大讯飞")msp.login()#print("科大讯飞登录成功")session_begin_params = b"sub = iat, ptt = 0, result_encoding = utf8, result_type = plain, domain = iat"if 16000 == audio_rate:session_begin_params = b"sub = iat, domain = iat, language = zh_cn, accent = mandarin, sample_rate = 16000, result_type = plain, result_encoding = utf8"text = msp.isr(filepath, session_begin_params)msp.logout()print(text)# 文本转语音speaker = win32com.client.Dispatch("SAPI.SpVoice")speaker.Speak(text)return text# 如果代码作为外置包被其他程序调用,请注释掉下两行;单独使用时保留
path = "你音频存储位置"
XF_text(path,16000)
特别说明:
1、我对这个代码做了一定的修改(源码可以在科大讯飞官网中找到:源码在这里)。这段代码单独使用时——可以将你的音频翻译成文本输出;而被其他主程序调用使用的时候,要先注释掉本篇代码的最后两行,还要在你的主程序代码中导入这个.py文件,怎么导入!!!—— 就像你导入其他外置包一样——import keda_API;
2、调用这个.py文件也和其他外置包一样,它的接口只有def XF_text(filepath, audio_rate):函数,这个函数包含两个参数:参数filepath是一个文件夹地址,这个地址下保存你录制好的音频(请存放一个音频,若有多个音频,你可以做个循环挨个输入文件名),audio_rate是音频率,一般都是16000;
3、如果你显示缺少ffmpeg文件,我也有——ffmpeg文件下载地址, 密码:xl2z,下载后放到你程序主目录下;
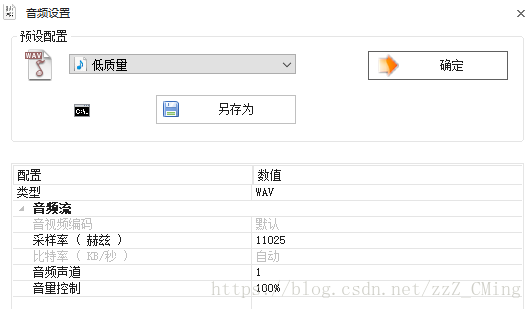
4、如果你导入的地址都已经正确,音频也能放出声,代码也能跑通,但就是语音听写得不到输出文本——可能是你的音频不合要求——右击你的音频文件,点开属性,查看详细信息,找到音频比特率——一般超过300kbps的音频,科大的音频听写就翻译不出来给不出结果,怎么办?——格式工厂啊,转为wav文件,配置降到最低——采用率:11025,声道数:1,用转化后的音频再试一试——还不行?那就关注我的下一篇博客——Python调用麦克风录音生成wav文件,我帮你写一个录音Python脚本。