文章目录
- 应用
- 替换其他数据结构
- 字典表达
- 术语索引
- 算法
- 排序
- 全文检索
- 实现
- Bitwise tries
- Compressing tries
- External memory trie
- About Me
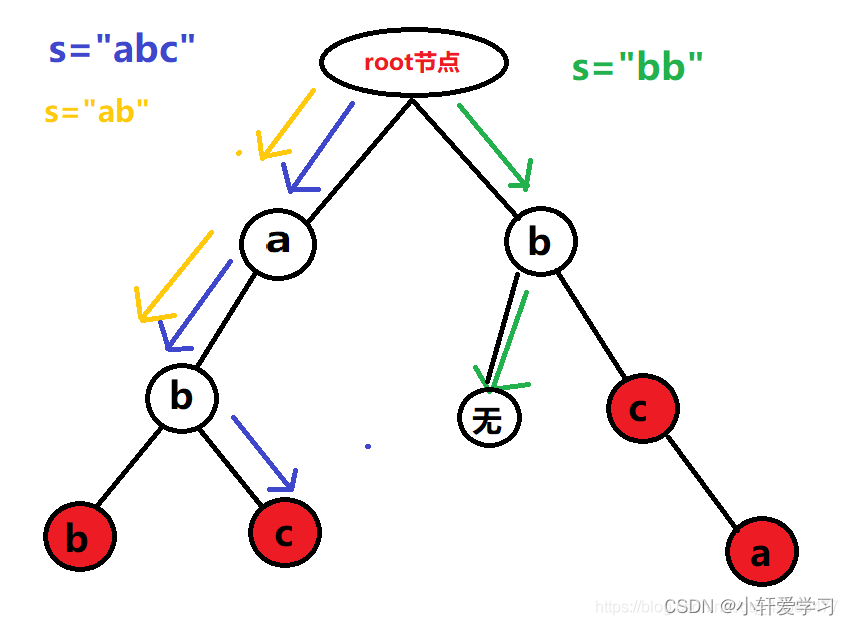
Trie ,也叫做 digital tree(数字树) 有时候也是 radix tree(基数树) 或者 prefix tree(前缀树) (因为他们可以通过前缀进行搜索) 是一种 search tree - 一种用来存储通常键为 strings 的dynamic set 或者 associative array 有序的 tree 数据结构. 不像 binary search tree(二叉搜索树) , Trie 树里的节点不存储与该节点关联的键,而是使用他在树里的位置来表明它所关联的键.一个节点的所有子节点都有该节点关联的字符串前缀,并且根节点关联的是一个空字符串.键倾向于与叶子关联,也有一些内部节点也有关联了键.因此,并不是每一个节点都会有关联的键.有关于前缀树的空间优化,可以参考 compact prefix tree .

如同示例所示,键展示在节点中,而值在节点的下面.每一个英文单词都有一个值.一个 trie 可以视为一个 树形的 deterministic finite automaton . 每一个 有限语言(finite language) 都是由一个 trie 自动机(automaton)生成的,并且每个 trie 可以被压缩成一个 deterministic acyclic finite state automaton .
它的键不仅仅可以使用字符串的字符,它同样可以使用相同的算法来适配一些相同功能的任何构造组成的有序列表,比如数字或者形状(shapes)的列表排序.特别是,一个 bitwise trie 是使用二进制数据的固定长度的 bit 来当做建,比如使用一个整数或者存储器地址.
应用
替换其他数据结构
trie 和 binary search tree 相比有很多的优点. Trie 同样可以用来替换 hash table ,它拥有以下的优点:
- Trie 对比一个不完美的 hash table 在最差的情况下查找数据更快,使用了 O ( m ) O(m) O(m) 的时间( m 是查找的字符串的长度),而一个不完美的 hash table 会产生键碰撞.即不同的键被映射到相同的位置.它在最差的情况下的查找速度是 O ( N ) O(N) O(N) ,但是通常情况下是 O ( 1 ) O(1) O(1) 加上 O ( m ) O(m) O(m) 的计算 hash 的时间.
- 在 trie 里不存在不同的键的碰撞.
- 当一个键对应了多个值的情况下,trie 结构里的 bucket 和 hash table 的 bucket 类似,都会产生键碰撞.
- 当更多的键加入到 trie 里的时候不需要提供 hash 函数或者是改变 hash 函数.
- trie 可以对条目的键进行字符排序.
trie 也有一些缺点:
- trie 在某些情况下会比使用 hash table 来查找数据更加费时,特别是在当数据直接在硬盘驱动上访问或者在一些其他的存储设备也就是在那些 随机存取( random-access) 时间会高于使用 内存(main memory).
- 某些键,比如 floating point numbers, 会导致要检索一个很长的链条,使得前缀很长但是没有什么特别的意义.虽然如此,使用 bitwise trie 可以处理标准 IEEE single 和 double format floating point number.
- 有些 trie 会比 hash table 需要更多的空间,因为内存可能会给每一个查找的字符串里的字符分配空间,而不是如何大部分的 hash table 一样分配一大块的内存给全部条目.
字典表达
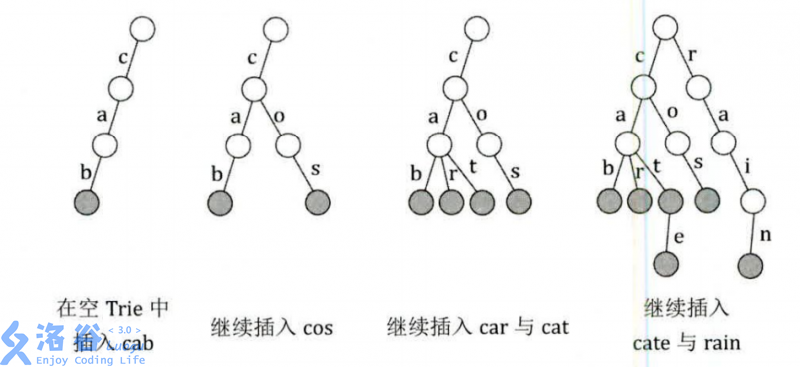
trie 常用于存储 预测性文本(predictive text) 或者 自动补全(autocomplete) 的字典,比如mobile telephone 上的查找功能.这样的应用程序利用了 trie 便于搜索,插入,和删除条目的优点;然而,如果只需要存储字典单词(不需要存储每个单词的附加信息),使用最小的 deterministic acyclic finite state automaton (DAFSA)(将同级的不同路径到达的代表相同字符的两个节点合并.) 将会占用更少的空间.这是因为它会在不同的单词开始存储的时候压缩 trie 中相同的分支(即拥有相同后缀或者部分后缀).
Trie 同样适用于实现近似匹配算法,包括那些 spell checking and hyphenation 软件
术语索引
discrimination tree term index 将他的信息存储在 Trie 中.
算法
Trie 是一个支持查找和插入操作的节点树.
查找返回 键对应的值,插入则插入一个字符串(键) 和它对应的值到 Trie 里.这两个操作的耗时都是 O ( n ) O(n) O(n) ,n 是键的长度.
下面这个简单 Node 类可以用来代表 Trie 中的节点:
# a class representation for trie node
class Node():def __init__(self):# NOde that using dictionary for children (as in this implementation) would not allow# lexicographic sorting mentioned in the next section (Sorting),# because ordinary dictionary would not preserve the order of the keys# mapping from character ==> Nodeself.children = {} self.value = None
注意 children 是这个节点的后代的字符键字典;并且"终端"节点是一个代表完整字符串的节点.
查找 Trie 的值的方法如下:
# find a node value with key
def find(node,key):for char in key:# if char in the node's children ,then go on to find next charif char in node.children:node = node.children[char]else:return Nonereturn node.value
插入操作通过要插入的键字符串来执行 Trie ,当出现 Trie中没有出现的字符层级的时候就添加新的节点给这个后缀.
# insert a node with key and value
def insert(root,string,value):node = rootindex_last_char = Nonefor index_char ,char in enumerate(string):if char in node.children:node = node.children[char]else:index_last_char = index_charbreak# append new nodes for the remaining characters , if anyif index_last_char is not None:for char in string[index_last_char:]:node.children[char] = Node()node = node.children[char]# store value in the terminal nodenode.value = value
这里有一个 main 方法可以用来测试
# a main method check for the trie
if __name__ == '__main__':root = Node()insert(root,"apple",43)insert(root,"else",41)insert(root,"banana",435)insert(root,"leon",2)insert(root,"application",55)insert(root,"app",11)print(find(root,"app"))排序
词典(Lexicographic) 可以通过构建一个 Trie 来对它键的集合进行排序,使用pre-order(左子树优先于右子树处理)进行遍历,只打印出叶子值.这个算法是 radix sort 的一种形式.trie 是组成Burstsort 数据结构的基础,Burstsort 是2007年已知的最快的字符串排序算法.然而现在已经有了更快的字符串排序算法.
全文检索
我们可以使用一种特殊的 trie — suffix tree 来索引所有该文本的后缀来进行更快的全文检索.
实现
这里有几种方式来表示 Trie,根据内存使用和操作的效率做一个权衡.一个基础的形式是在一个 linked set 的节点,每个节点包含了一个 array 的子指针,一种方式是使用 alphabet 中的每个符号(所以对于英语字母表来说,每个会存储26个子指针,如果使用字节的字符表的话要256个指针).这样处理是很简单的,但是会很浪费内存:使用字节字符表(总数256个)和四字节指针,每一个节点需要千字节的存储,并且当字符串的前缀没多少重复的时候,需要的节点数量大致是存储的字符串的总长度.换句话说,很多树底部附近的节点只有很少的子节点,这个结构浪费了大量的空间来存储空指针.
存储的问题可以通过 alphabet reduction 这个实现技术来优化,它通过将原始的字符串使用一个更小的字符集来重新解释为一个更长的字符串.比如,一个 n bytes 的字符串可以当做一个 2n 个 four-bit units 的字符串,这样存储在 Trie 中的时候每个节点只需要16个指针.在最差的情况下查找需要访问两倍数量的节点,但是存储空间变为原来的八分之一.
另一种实现方法是使用一个三元元素(symbol,child,next)来代表节点并且使用singly linked list 来链接子节点:child 指向节点的第一个子节点,next 指向父节点的下一个 child .子节点的集合还可以使用 binary search tree 来表示.比如 Bentley and Sedgewick 开发的 ternary search tree 就是这个思想的实例.
为了避免使用256个指针(ASCII)数组,就像前面建议的那样,我们可以通过使用256 bit 的 bitmap来表示 ASCII 字符集,来显著的减少节点的数量.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GajPmWxU-1595946728995)(Resources/Pointer_implementation_of_a_trie.png)]
一个 trie 实现的如同一个 doubly chained tree 一样:垂直的箭头是 child 指针,水平虚线箭头是 next 指针.这个 trie 中的存储的字符串集合是 {baby, bad, bank, box, dad, dance} .这个列表按照允许字典顺序遍历还排序的.
Bitwise tries
Bitwise trie 和常用的基于字符的 trie 是相同的除了它将遍历每一 bit 的方式变成了二叉树来提高了效率. 通常情况下,它的实现会使用一个特殊的 CPU 指令来快速的查找定长的键的第一个位的集合(比如,GCC 内置的__builtin_clz() ). 这个值用于索引一个 32- 或者 64- 位表指向 bitwise trie 的第一个项目包含这个数字所带有的前导零. 然后通过处理键后面的位来选择合适的 child[0] 或者 child[1] 知道找到对应的项目.
尽管这个处理听起来很慢,但是它由于对不依赖寄存器支持本地缓存并且具有高并发特性,所以他在现代的 out-of-order execution CPU 中可以有优秀的性能. red-black tree 在理论上拥有更好的性能表现,但是它对缓存很不友好并且会导致多通道并且 TLB 在现代 CPU 情况下算法的性能受限于内存的延迟而不是 CPU 的速度.相比之下, bitwise trie 很少访问内存,当它需要使用的时候,它只需要读取,从而避免了 SMP 缓存一致性开销.因此,它快速成为许多快速插入和删除的代码算法的选择,就像内存分配器一样(最近流行的版本是 Doug Lea’s allocator (dlmalloc) and its descendents ).
Compressing tries
压缩 trie 并且合并相同分支这在有时候会提高很多性能.这个方法在以下情况中表现最佳:
- 这个 trie 大部分是静态的(禁止在预先填充的 trie 中进行键的插入和删除)
- 只需要进行查找操作
- trie 节点不是根据节点特定数据进行组键,或者节点的数据是通用的.
- 存储的键的集合在它的表现空间里非常的稀疏.
比如,它可能被用来表示稀疏的 bitsets ,也就是一个更大固定可以枚举的子集.在这种情况下,trie 是通过全部的集合内的位元素位置进行排键,这个键是根据字符串里的每一个元素需要被编码的完整的 bit 生成的.这种 trie 有一种非常退化的形式它的大量分支都消失了.在检测了通用模式的重复情况或者填充了不适用的缺口,独特的叶子节点( bit 字符串)可以存储并且轻松的压缩,减少了 trie 整体的大小.
这样的压缩方式同样适用于多个 Unicode 字符的表的快速查找.这些包括了条件映射表(比如 希腊字母 pi,从Π 到 π),还包含了组合字符如德语等.
External memory trie
几种变体适用于在外部存储器中维护字符串集和,包括后缀树。还建议将trie和B-tree组合称为B-trie用于此任务;与后缀树相比,它们在受支持的操作中受到限制,但也更紧凑,同时更快地执行更新操作。
About Me
我的博客 leonchen1024.com
我的 GitHub https://github.com/LeonChen1024
微信公众号