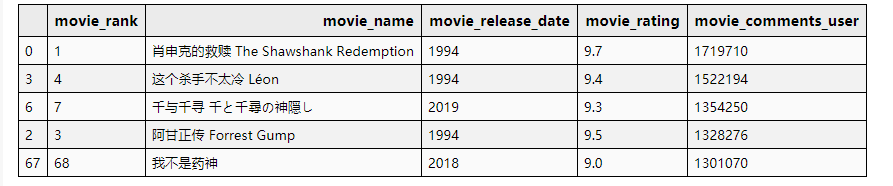电影信息爬取与聚类分析
要求:爬取电影相关数据,条数不小于1000,结构自定,要求包含情感信息,类别,评论关键词等,然后基于这些信息根据用户的喜好做相关性聚类。
一、总体设计
(1)爬取豆瓣电影中的50部电影数据,包括片名、国家、时长、主演、导演、类型、评分、评价人数等信息
(2)爬取各部电影的短评数据,包括用户名、评价、评论、赞同数等
(3)对爬取的数据进行处理并写入相应的csv文件中
(4)读取csv文件,对数据进行分析处理,抛去不参与聚类的特征,将非数值型特征转换为数值型特征。
(5)对数据进行降维处理,并通过K-means进行聚类
(6)将聚类结果可视化,并进行结果分析与总结
二、详细设计
(1)爬取豆瓣电影中的50部电影数据,包括片名、国家、时长、主演、导演、类型、评分、评价人数等信息
//导入库函数
import json
import re
import requests
from lxml import etree
import numpy as np
import csvheader = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
res = requests.get(url="https://movie.douban.com/top250?start=0&filter=",headers=header)#排名1-20的影片地址
res1 =requests.get(url="https://movie.douban.com/top250?start=225&filter=",headers=header)#排名21-40的影片地址
res.encoding = 'utf8'
res1.encoding = 'utf8'
text = res.text
text1=res1.text
tree = etree.HTML(text)
tree1 = etree.HTML(text1)
items = tree.xpath('//ol/li/div/div[@class="info"]')
items1 = tree1.xpath('//ol/li/div/div[@class="info"]')
director = [] #导演
film = [] #影片名
film_date = [] #上映时间
film_country = [] #拍摄国家
film_type = [] #类型
star = [] #评分
assess_num = [] #评价人数
quote = [] #推荐语
url = [] #影片地址
#获取排名1-20的电影信息
for item in items:film_url = item.xpath("./div[@class='hd']/a/@href")url.append(film_url[0])film_name = item.xpath("./div[@class='hd']/a/span[1]/text()")[0]film.append(film_name)f_info = item.xpath("./div[@class='bd']/p[1]/text()")info_1 = f_info[1].replace("\xa0","").replace("\n"," ").split("/")film_date.append(info_1[0].replace(" ",""))country =info_1[1]film_country.append(country)film_type.append(info_1[2].replace(" ",""))f_info = f_info[0].replace("\n","").split(' ')director_deal = f_info[4].split(":")[1].replace("主演","").replace("...","").replace("主","").replace("\xa0","").replace("\n"," ")director.append(director_deal) film_star = item.xpath("./div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()")star.append(film_star[0])film_assess = item.xpath("./div[@class='bd']/div[@class='star']/span/text()")[1].replace("人评价","")assess_num.append(film_assess)film_quote = item.xpath("./div[@class='bd']/p/span[@class='inq']/text()")if len(film_quote)==0:film_quote = "无"else:film_quote = film_quote[0]quote.append(film_quote)#获取排名21-40的电影信息
for item in items1:film_url = item.xpath("./div[@class='hd']/a/@href")url.append(film_url[0])film_name = item.xpath("./div[@class='hd']/a/span[1]/text()")[0]film.append(film_name)f_info = item.xpath("./div[@class='bd']/p[1]/text()")info_1 = f_info[1].replace("\xa0","").replace("\n"," ").split("/")film_date.append(info_1[0].replace(" ",""))country =info_1[1]film_country.append(country)film_type.append(info_1[2].replace(" ",""))f_info = f_info[0].replace("\n","").split(' ')director_deal = f_info[4].split(":")[1].replace("主演","").replace("...","").replace("主","").replace("\xa0","").replace("\n"," ")director.append(director_deal)film_star = item.xpath("./div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()")star.append(film_star[0])film_assess = item.xpath("./div[@class='bd']/div[@class='star']/span/text()")[1].replace("人评价","")assess_num.append(film_assess)film_quote = item.xpath("./div[@class='bd']/p/span[@class='inq']/text()")if len(film_quote)==0:film_quote = "无"else:film_quote = film_quotequote.append(film_quote[0])#获取电影的时长以及主演
actor = []
time = []
for URL in url:header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}res = requests.get(url=URL,headers=header)res.encoding = 'utf8'text = res.texttree = etree.HTML(text)items = tree.xpath('//body/div/div[@id="content"]')for item in items:film_actor = item.xpath('./div[@class="grid-16-8 clearfix"]/div[@class="article"]/div[@class="indent clearfix"]/div[@class="subjectwrap clearfix"]/div[@class="subject clearfix"]/div[@id="info"]/span[@class="actor"]/span[@class="attrs"]//text()')film_actor = set(film_actor)film_actor = list(film_actor)film_actor.remove(' / ')p = ' '.join(film_actor)actor.append(p)film_runtime =item.xpath('./div[@class="grid-16-8 clearfix"]/div[@class="article"]/div[@class="indent clearfix"]/div[@class="subjectwrap clearfix"]/div[@class="subject clearfix"]/div[@id="info"]/span[@property="v:runtime"]//text()')time.append(film_runtime[0])//获取电影好评的短评信息,包括用户名、评分、评论内容、赞同人数
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"}
coments_data = []
p = 0
for i in url:print(film[p])k = 0;while k < 10:short_view_url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&sort=new_score&status=P&percent_type=h".format(i.split('/')[-2],str(k*20))r = requests.get(short_view_url,headers=header).texts = etree.HTML(r)infos = s.xpath("//div[@id='comments']/div[@class='comment-item']")check = s.xpath("//div[@id='comments']/div[@class='comment-item']/text()")check = check[0].replace(" ","").replace("\n","")if check !="还没有人写过短评":for info in infos:c_data = []coments_user = info.xpath('./div[@class="comment"]/h3/span[@class="comment-info"]/a/text()')if len(coments_user) == 0:coments_user = "无用户名"else:coments_user = coments_user[0]coments_info = info.xpath('./div[@class="comment"]/p/span/text()')if len(coments_info) == 0:coments_info = ""else:coments_info = coments_info[0]coments_agree_num = info.xpath('./div[@class="comment"]/h3/span[@class="comment-vote"]/span/text()')if len(coments_agree_num) == "":coments_agree_num="0"else:coments_agree_num=coments_agree_num[0]coments_rate = info.xpath('./div[@class="comment"]/h3/span[@class="comment-info"]/span/@title')if(len(coments_rate)==1):coments_rate = "无"coments_time = info.xpath('./div[@class="comment"]/h3/span[@class="comment-info"]/span/@title')[0]else:coments_rate = info.xpath('./div[@class="comment"]/h3/span[@class="comment-info"]/span/@title')[0]coments_time = info.xpath('./div[@class="comment"]/h3/span[@class="comment-info"]/span/@title')[1]c_data.append(film[p])c_data.append(coments_user)c_data.append(coments_info)c_data.append(coments_rate)c_data.append(coments_time)c_data.append(coments_agree_num)coments_data.append(c_data)k += 1p += 1
(2)将爬取的数据进行处理并写入相应的csv文件中
short_view_feature = ["片名","用户名","短评","评价","时间","赞同数"]
with open("short_view.csv","w",encoding="utf8",newline="") as f:writer =csv.writer(f)writer.writerow(short_view_feature)writer.writerows(coments_data)
all_data = []
for i in range(len(film)):A_data = []A_data.append(film[i]) #片名A_data.append(time[i])#时长A_data.append(director[i])#导演 A_data.append(actor[i])#主演A_data.append(film_date[i])#年份A_data.append(film_country[i])#国家/地区A_data.append(film_type[i]) #类型A_data.append(star[i]) #评分A_data.append(assess_num[i])#评价人数A_data.append(quote[i])#推荐语all_data.append(A_data)
feature_name = ["片名","时长","导演","主演","年份","国家/地区","类型","评分","评价人数","推荐语"]
all_data.insert(0,feature_name)
with open("movies.csv","w",encoding="utf8",newline="") as f:writer =csv.writer(f)writer.writerows(all_data)
Csv文件内容如下图


(3)读取csv文件,对数据进行分析处理,抛去不参与聚类的特征,将非数值型特征转换为数值型特征。
对数据进行处理,去掉不参与聚类的信息,比如“导演”、“主演”、“推
荐语”等。
import numpy as np
import csv
import pandas as pd
np.set_printoptions(suppress=True)
pd.set_option('display.float_format', lambda x: '%.2f' % x) #为了直观的显示数字,不采用科学计数法movies = pd.read_csv("movies.csv")
movies = movies.drop(["导演","主演","推荐语"],axis = 1)
将非数值型特征转换为数值型特征,比如国家特征,通过对所有电影排序,按照从高到低的出现频率,修改特征值
for i in range(len(movies["时长"])):p=movies["时长"][i].split("分钟")movies["时长"][i] = p[0]for i in range(len(movies["国家/地区"])):p=movies["国家/地区"][i].split(" ")movies["国家/地区"][i] = p[0]country = movies["国家/地区"].value_counts(normalize=True)
country=list(country.index)
for i in range(len(movies["国家/地区"])):p=country.index(movies["国家/地区"][i])movies["国家/地区"][i] = p+1country_chart = {}
for i in country:country_chart[country.index(i)+1] = itype_num = []
type = []
for i in range(len(movies["类型"])):p=len(movies["类型"][i].split(" "))type.append(movies["类型"][i].split(" "))type_num.append(p)movies["类型数量"] = type_num
for x in range(len(type)):for y in range(max(type_num)-len(type[x])):type[x].append("")type = np.array(type)
movies["第一类型"] = type[:,0]
movies["第二类型"] = type[:,1]
movies["第三类型"] = type[:,2]
movies["第四类型"] = type[:,3]
movies = movies.drop(["类型"],axis = 1)type_all = []
for i in type:for x in range(4):type_all.append(i[x])
type_all = np.array(type_all)data = pd.DataFrame(data = type_all,index = None,columns = ["ALL"])
type_list=data["ALL"].value_counts()
type_name = list(type_list.index)
for i in range(len(movies["第一类型"])):p=type_name.index(movies["第一类型"][i])movies["第一类型"][i] = p
for i in range(len(movies["第二类型"])):p=type_name.index(movies["第二类型"][i])movies["第二类型"][i] = p
for i in range(len(movies["第三类型"])):p=type_name.index(movies["第三类型"][i])movies["第三类型"][i] = p
for i in range(len(movies["第四类型"])):p=type_name.index(movies["第四类型"][i])movies["第四类型"][i] = p
type_chart = {}
for i in type_name:type_chart[type_name.index(i)] = ishort_view = pd.read_csv("short_view.csv")
short_view = short_view.drop(["用户名","短评","时间"],axis = 1)
short_view["评价"].value_counts()
for i in range(len(short_view["评价"])):if short_view["评价"][i] == "力荐":short_view["评价"][i] = 10elif short_view["评价"][i] == "推荐":short_view["评价"][i] = 8elif short_view["评价"][i] == "还行":short_view["评价"][i] = 6elif short_view["评价"][i] == "较差":short_view["评价"][i] = 4else:short_view["评价"][i] = 2
对短评数据进行处理,去除用户名和评论内容,将评价和赞同人数作为聚类特征值,对所有数据进行统计
film_name = list(movies["片名"].values)
goal_10 = []
goal_10_agree = []
goal_8 = []
goal_8_agree = []
goal_6 = []
goal_6_agree = []
goal_4 = []
goal_4_agree = []
goal_2 = []
goal_2_agree = []
for i in film_name:goal_10.append(len(short_view[(short_view["片名"]== i )& (short_view["评价"]==10)]))goal_10_agree.append(sum(short_view[(short_view["片名"]== i )& (short_view["评价"]==10)]["赞同数"]))goal_8.append(len(short_view[(short_view["片名"]== i )& (short_view["评价"]==8)]))goal_8_agree.append(sum(short_view[(short_view["片名"]== i )& (short_view["评价"]==8)]["赞同数"]))goal_6.append(len(short_view[(short_view["片名"]== i )& (short_view["评价"]==6)]))goal_6_agree.append(sum(short_view[(short_view["片名"]== i )& (short_view["评价"]==6)]["赞同数"]))goal_4.append(len(short_view[(short_view["片名"]== i )& (short_view["评价"]==4)]))goal_4_agree.append(sum(short_view[(short_view["片名"]== i )& (short_view["评价"]==4)]["赞同数"]))goal_2.append(len(short_view[(short_view["片名"]== i )& (short_view["评价"]==2)]))goal_2_agree.append(sum(short_view[(short_view["片名"]== i )& (short_view["评价"]==2)]["赞同数"]))movies["力荐人数"] = goal_10
movies["力荐赞同数"] = goal_10_agree
movies["推荐人数"] = goal_8
movies["推荐赞同数"] = goal_8_agree
movies["还行人数"] = goal_6
movies["还行赞同数"] = goal_6_agree
movies["较差人数"] = goal_4
movies["较差赞同数"] = goal_4_agree
movies["很差人数"] = goal_2
movies["很差赞同数"] = goal_2_agree
处理完成后的数据集:

(4)通过肘部法则和轮廓系数确定聚类的类别数
from matplotlib import pyplot as plt
from sklearn.cluster import k_means
import pandas as pd
from sklearn.metrics import silhouette_score
#肘部法则
file = movies.drop(["片名"],axis = 1)
index = []
inertia = []for i in range(0,10):model = k_means(file,n_clusters = i + 1)index.append(i+1)inertia.append(model[2])plt.plot(index,inertia,"-o")
plt.show()

from matplotlib import pyplot as plt
from sklearn.cluster import k_means
import pandas as pd
from sklearn.metrics import silhouette_score
#轮廓系数
file = movies.drop(["片名","评分"],axis = 1)
index = []
silhouette = []
for i in range(9):model = k_means(file,n_clusters = i + 2)index.append(i+2)silhouette.append(silhouette_score(file,model[1]))
plt.plot(index,silhouette,"-o")
plt.show()

(5)通过主成分分析法(pca)对数据进行降维处理
from sklearn.decomposition import PCA
pca=PCA(n_components=3)
X3D=pca.fit_transform(file)
model = k_means(X3D,n_clusters = 2)
cluster_centers = model[0] # 聚类中心数组
cluster_labels = model[1] # 聚类标签数组
ax = plt.subplot(111, projection='3d')
ax.scatter(X3D[cluster_labels ==0,0],X3D[cluster_labels ==0,1],X3D[cluster_labels ==0,2], c='#ff1493', s=20, alpha=1, marker='o')
ax.scatter(X3D[cluster_labels ==1,0], X3D[cluster_labels ==1,0], X3D[cluster_labels ==1,0], c='#3333cc', s=20, alpha=1, marker='^')
ax.scatter(X3D[cluster_labels ==2,0], X3D[cluster_labels ==2,0], X3D[cluster_labels ==2,0], c='#4d3333', s=20, alpha=1, marker='*')
ax.scatter(cluster_centers[:][:,0],cluster_centers[:][:,1],cluster_centers[:][:,2], c='#FF0000', s=50, alpha=1, marker='o')
plt.show()

pca=PCA(n_components=3)
model = k_means(X3D,n_clusters = 2)
X2D=pca.fit_transform(file)
cluster_centers1 = model[0] # 聚类中心数组
cluster_labels1 = model[1] # 聚类标签数组
plt.scatter(X2D[:,0],X2D[:,1],c=cluster_labels1)

分析:本来是希望可能将50部电影依据评分聚类成三类,但是结果并不是很理想,虽然在二维的坐标上可以看出数据能被成功划分为三类。其中的原因可能是爬取的50部电影都是9.0评分的优秀电影,所以区分度有点小,于是我决定9分以上的电影爬取25部,9-8分的电影爬取25部,重新用上述方法进行聚类。结果如下:
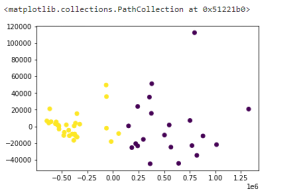
查看数据的划分情况


从图片中可以看到,除了少数几个点的干扰外,这次聚类的效果还是很不错的,比较成功地将9.0评分的电影和9.0评分以下的电影区分开。分析原因也可以得出,在数据中,某些数据的基数比较大,可能对最后聚类结果的影响也比较大,比如力荐赞同数等数据。