点赞再看,养成好习惯
Python版本3.8.0,开发工具:Pycharm
写在前面的话:
如果你是因为看到标题进来的,那恭喜你,又多了一个涨(入)知(坑)识的机会。
在这篇豆瓣电影Top250的分析文章中,你并不会得到一个像标题那样确切的答案。
但是你可以因此否定很多看似正确的答案,比如下面这些:
“豆瓣电影Top250是根据评分排序的?”
“难道是根据评论数排序?”
“那一定是评分和评论数两者一起影响的?”
以上的想法或许你曾经也想过,但是都不对。
“为什么不对?”
“怀疑我!那我今天就给你分析一下为什么!”

数据来源上一节:
- 爬虫实战-手把手教你爬豆瓣电影
不想运行代码,只想要数据,行!文末有数据获取方式。
另外,和上篇一样,重点是分析的流程(敲黑板了)
下面,开始今天的——豆瓣电影分析之路。
假设
“小一哥,怎么一上来就是假设?假设又是什么?”
“假设,是针对我们的分析结果而言。你希望最后输出一个什么结果,或者你需要证明什么结果,都可以当做假设!”
数据分析是由结果导向的,什么是结果导向?
说白了,其实是根据目的去完成任务。
你经历什么学到什么,是你自己的经验教训,领导不关心,其他人也不关心。你工作是否合格业绩、是否优秀,要看结果论成败。
根据目的去完成任务,总是会事半功倍。你可以用分析去研究你想要的结果
就像周末有朋友要请小一我吃超过两百块的大餐,这就是假设。根据假设小一可以选择去吃什么,像什么海底捞、烤全羊统统可以安排,海鲜大餐什么的也可以啊,那个说吃沙县的你过分了昂。

但我们的假设可不像两百块一样,是一个定数。我们的假设可能是一个范围,一个问题,或者一个未知的点。
那对应于这次的分析,我们的假设可以是:
- 哪个星级评分更能体现影片整体评分?
- 影片整体评分与评论数相关吗?
- 影片整体评分与哪些指标相关?
以上三个问题,你们可以先思考一下,然后再继续下一节
数据分析法则
可能你在入门数据分析的时候周围的人会告诉你帕累托法则,这个法则最开始是用来形容人类社会的财富分布:百分之二十的人掌握有百分之八十的财富。
但是现在似乎已经普遍适用,大家都已经认识到:重要的因子通常只占少数。
“小一哥,根据帕累托法则,哪个环节最重要?”
“这个就不能用帕累托法则了,数据的重要性毋庸置疑!”
在整个数据分析的周期中,数据清洗直接决定分析结果是否准确,可视化可以发现事实问题,并寻找出现的原因,在数据探索中你可以进行更深层次的数据挖掘。
数据分析大家现在有个概念就好了,后面会补充一节数据分析的理论知识
数据清洗
“小一哥,数据清洗之前,我们需要先了解什么?”
“做事之前,肯定要先了解目的啊”
数据清洗的目的是为了清洗脏数据,为后期的数据可视化、特征工程,保证数据的合理性、准确性。
“嗷,就是我数据必须得干净,不能有错的”
“不止这些,当你的数据存在异常值,你可能还需要借助可视化图表对数据进行异常值检测”
举个例子,你的数据中存在年龄字段的时候,你不能只认为不是整数的就是脏数据。年龄小于0的,大于150的,都需要注意
本次数据因为脏数据不多,大家理解概念即可,具体清洗方法会补充在理论知识那一节。
准备好了吗
拿到数据之后,需要先检查数据的整体缺失情况
''' 1. 查看整体数据类型与缺失情况'''
df_data.info()
可以看到,豆瓣电影 Top250 的数据缺失情况如下:
Data columns (total 21 columns):
id 250 non-null int64
movie_rank 250 non-null object
movie_name 250 non-null object
movie_director 250 non-null object
movie_writer 250 non-null object
movie_starring 250 non-null object
movie_type 250 non-null object
movie_country 250 non-null object
movie_language 250 non-null object
movie_release_date 250 non-null object
movie_run_time 250 non-null object
movie_second_name 2 non-null object
movie_imdb_href 250 non-null object
movie_rating 250 non-null object
movie_comments_user 250 non-null object
movie_five_star_ratio 250 non-null object
movie_four_star_ratio 250 non-null object
movie_three_star_ratio 250 non-null object
movie_two_star_ratio 250 non-null object
movie_one_star_ratio 250 non-null object
movie_note 250 non-null object
“小一哥,这个能看出什么呢?”
“整体数据字段,以及每个字段的缺失情况!”
可以看到,我们的数据集共有21个字段,其中只有电影又名字段有两个空数据。
我们爬取的豆瓣电影 Top250 数据本就规整,所有没有缺失属于正常情况,后面实战的其他数据可能就没有这么规整了。
对于部分影片缺失又名信息,用影片名称去填充即可
# 用影片名称填充影片又名字段
df_data['movie_second_name'].fillna(df_data['movie_name'],inplace=True)
带着整体数据的统计情况,我们去检查每一个字段
''' 2. 查看单个指标的数据,并进行相应的清洗操作'''
首先是影片排序数据:
# 1. 影片排名数据
df_data['movie_rank'].head(5)
0 No.1
1 No.2
2 No.3
3 No.4
4 No.5
Name: movie_rank, dtype: object
可以看到数据形式是 No.XX 类型,若是建模的话,这种数据类型是不符合要求。
这里我们将 No.XX 数据的 No. 删掉,只保留后面的数字即可。
df_data['movie_rank'] = df_data['movie_rank'].str.replace('No.', '').astype(int)
接下来是影片类型字段:
# 2. 影片类型
df_data['movie_type'].head(5)
0 剧情/犯罪
1 剧情/爱情/同性
2 剧情/爱情
3 剧情/动作/犯罪
4 剧情/喜剧/爱情/战争
Name: movie_type, dtype: object
可以看到数据形式是 xx/xx/xx 的形式,数据规整,不需要处理,若是建模的话可以对其进行独热编码。
接下来是影片制作国家/地区字段:
# 3. 影片制作国家
print(df_data['movie_country'].head(10))
0 美国
1 中国大陆 / 中国香港
2 美国
3 法国
4 意大利
Name: movie_country, dtype: object
可以看到数据形式是 xx / xx 的形式, 用 / 分割,数据规整,但因为存在空格,需要对空格进行处理。
“这个简单,小一哥,我会!”
# 这里直接对空格进行替换
df_data['movie_country'] = df_data['movie_country'].str.replace(' ', '')
“学以致用,很不错,小伙子!”
接下来是影片语言字段:
和影片制作国家字段一样,存在空白字符,同样的处理方法。
# 同理,直接对空格进行替换
df_data['movie_language'] = df_data['movie_language'].str.replace(' ', '')
接下来是影片上映日期:
# 5. 影片上映日期
df_data['movie_release_date'].head(5)
0 1994-09-10(多伦多电影节)/1994-10-14(美国)
1 1993-01-01(中国香港)/1993-07-26(中国大陆)
2 1994-06-23(洛杉矶首映)/1994-07-06(美国)
3 1994-09-14(法国)
4 1997-12-20(意大利)
Name: movie_release_date, dtype: object
可以看到部分影片存在多个上映日期和上映城市。
“小一哥,这个怎么处理?有多个上映日期和上映城市”
“这里只保留首映日期,日期保留年份即可,并新增一列上映城市”
df_data['movie_release_date'] = df_data['movie_release_date'].apply(lambda e: re.split(r'/', e)[0])
df_data['movie_release_city'] = df_data['movie_release_date'].apply(lambda e: e[11:-1])
df_data['movie_release_date'] = df_data['movie_release_date'].apply(lambda e: e[:4])
接下来是影片片长:
# 6. 影片片长
df_data['movie_run_time'].head(10))
0 142分钟
1 171 分钟
2 142分钟
3 110分钟(剧场版)
4 116分钟
Name: movie_run_time, dtype: object
可以看到影片片长为 XX分钟 这种形式,还有部分是 110分钟(剧场版)这种形式
这里直接保留影片分钟数即可
df_data['movie_run_time'] = df_data['movie_run_time'].apply(lambda e: re.findall(r'\d+', e)[0]).astype(int)
接下来是影片总评分,影片评论数:
# 7. 影片总评分,影片评论人数
df_data[['movie_rating', 'movie_comments_user']].head(5)
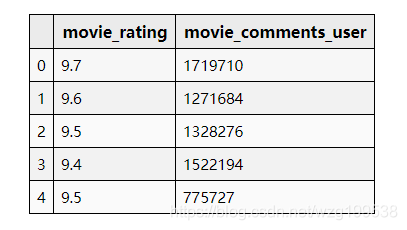
设置为相应的数据格式即可,影片总评分是浮点类型,影片评论数是整数型
# 这里将影片总评分转换为 float、影评人数转换为 int(默认都是 object类型)
df_data['movie_rating'] = df_data['movie_rating'].astype(float)
df_data['movie_comments_user'] = df_data['movie_comments_user'].astype(int)
接下来是影片星级评分占比:
# 8. 影片星级评分占比
df_data[['movie_five_star_ratio', 'movie_four_star_ratio', 'movie_three_star_ratio','movie_two_star_ratio', 'movie_one_star_ratio']].head(5)
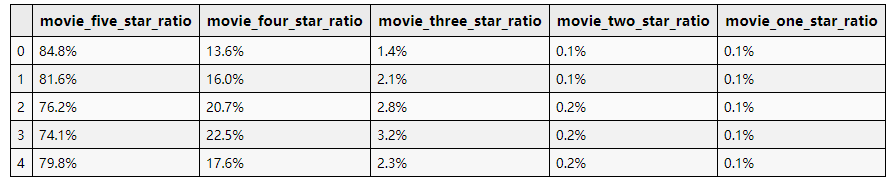
可以看出星级评分占比为 xx% 的形式。
这里对所有星级的影片进行处理,将百分比转换成小数即可。
“小一哥,数据清洗算是完成了吗?”
“前面的步骤只是为了我们可以更好的进行数据可视化。在接下来的可视化过程中,我们会针对性的进行数据清洗”
所以,接下来的,重点(第二次敲黑板)
数据可视化
通过对数据可视化,发现数据的分布情况,甚至是数据之间的关联信息。
”可视化需要用到什么模块?
可视化可以使用 matplotlib, 但是我使用了 seaborn。
“为什么使用 seaborn 作图?“
seaborn同matplotlib一样,也是 Python 进行数据可视化分析的重要第三方包。但
seaborn是在matplotlib的基础上进行了更高级的 API 封装,使得作图更容易,图形更漂亮。针对一些特殊情况,还是需要用到
matplotlib的,应该把seaborn视为matplotlib的补充,而不是替代物。
seaborn 的相关操作大家能看懂即可,后期会抽空出简单使用教程。
准备好了吗
上一步中我们已经针对每个字段进行了初步检测。看一下整体数据的描述性统计:
对数值型特征进行简单的描述性统计,包括均值,中位数,众数,方差,标准差,最大值,最小值等
# 描述性数据统计
df_data.describe()
接下来需要判断数据类型,定类?定序?定距?还是定比?
弄清楚这一步主要是为了后续正确找对方法进行可视化
'''数据类型划分
影片类型、影片制片国家、影片语言: 定类数据<br>
影片片长、影片总评分、影片评论数、影片时间:定距数据
影片5/4/3/2/1星占比:定比数据
'''
根据上面对各个特征数据类型的判断,选择合适的可视化方法完成可视化。
定类/定序特征分析
将影片类型数据通过 / 分割后统计每个类型出现的次数
'''统计影片类型数据'''
df_data['movie_type'] = df_data['movie_type'].map(lambda e: e.split('/'))
# 将数据转换成一维数组
movie_type_list = np.concatenate(df_data['movie_type'].values.tolist())
# 将一维数组重新生成 Dataframe 并统计每个类型的个数
movie_type_counter = pd.DataFrame(movie_type_list, columns=['movie_type'])['movie_type'].value_counts()
# 生成柱状图的数据 x 和 y
movie_type_x = movie_type_counter.index.tolist()
movie_type_y = movie_type_counter.values.tolist()
画出影片类型的柱状图
# 画出影片类型的柱状图
ax1 = sns.barplot(x=movie_type_x, y=movie_type_y, palette="Blues_r", )
# Seaborn 需要通过 ax.set_title() 来添加 title
ax1.set_title('豆瓣影片Top250类型统计 by:『知秋小一』')
# 设置 x/y 轴标签的字体大小和字体颜色
ax1.set_xlabel('影片类型', fontsize=10)
ax1.set_ylabel('类型出现次数', fontsize=10)
# 设置坐标轴刻度的字体大小
ax1.tick_params(axis='x', labelsize=8)
# 显示数据的具体数值
for x, y in zip(range(0, len(movie_type_x)), movie_type_y):ax1.text(x - 0.3, y + 0.3, '%d' % y, color='black')plt.show()
后面的画图代码就不一一显示,整体代码太长你们看着也不舒服。需要源码的在文末有获取方式。
影片类型统计如下:
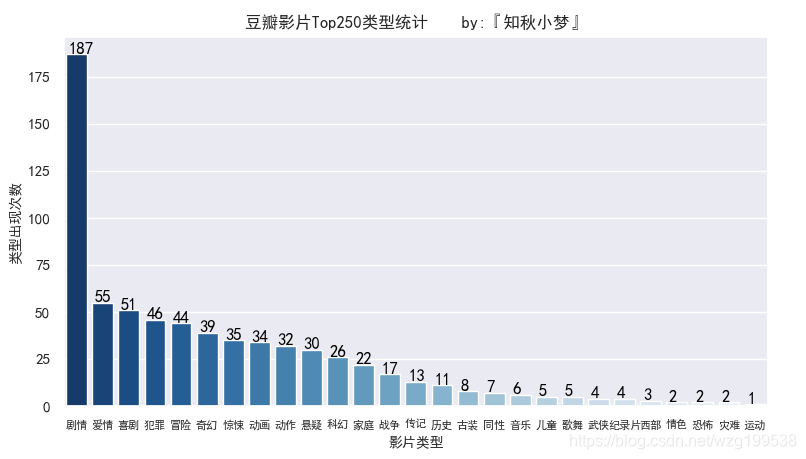
可以看到,剧情类占比特别高,类型前五分别是:剧情、爱情、喜剧、犯罪和冒险。
其中,还有两个情色类的,emmm,我就不告诉你们是什么了。
同理,将影片语言数据通过 / 分割后统计每个语言出现的次数
影片语言统计如下:
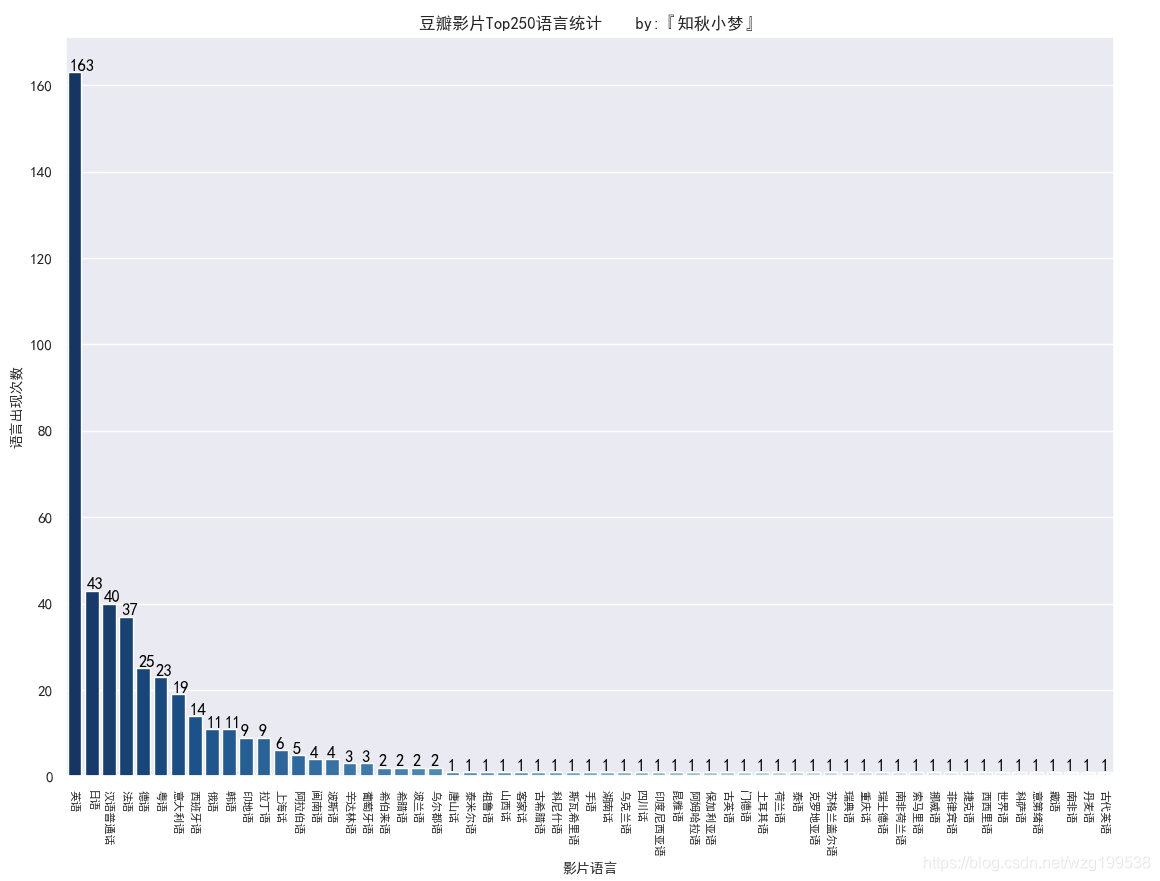
可以看到,英语类占比特别高,语言前五分别是:英语、日语、汉语普通话、法语和德语。
发现一个更有意思的现象,可以看到粤语、上海话、闽南语、重庆话、山西话、湖南话、唐山话、客家话、四川话也都有出现,等会可以看一下具体是哪些影片。
同理将影片制片国家/地区数据通过 / 分割后统计每个国家/地区出现的次数
影片制片国家统计如下:
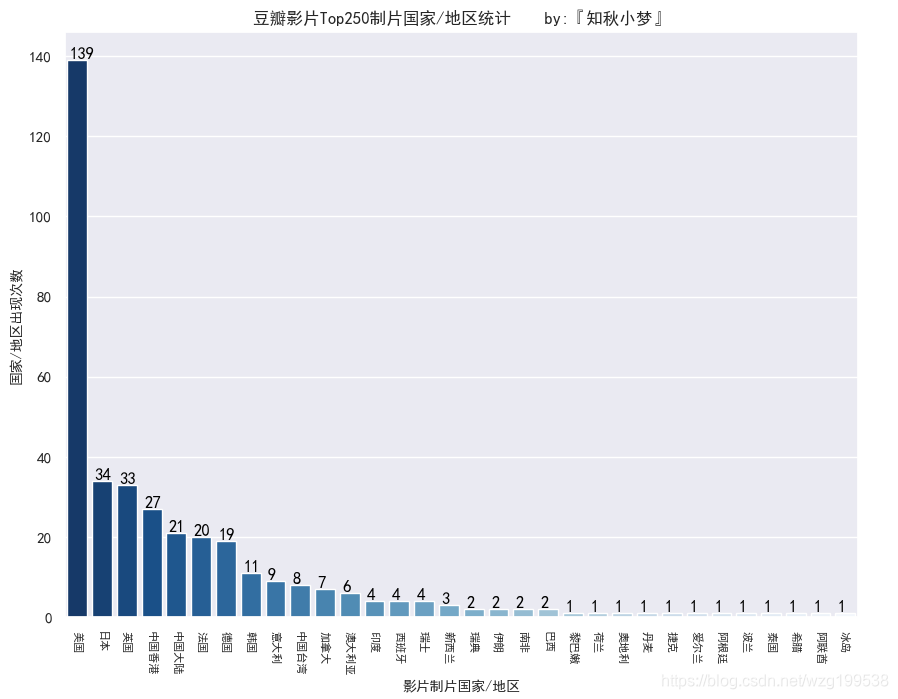
好莱坞大国稳居榜首,制片国家/地区前五分别是美国、日本、英国、中国香港和中国大陆。
港片还是有很多经典之作的,比起大陆来说相对多一些吧。
定距/定比特征分析
影片片长、影片总评分、影片评论人数都属于定距定比特征,我们来依次分析一下。
影片片长统计如下:
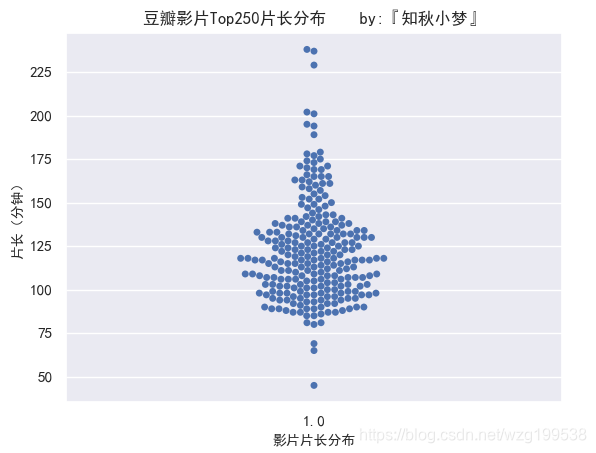
影片片长大多在75~175之间,这个也是目前大多数影片的片长。
可以看出还有一个影片在50分钟以下,难道是个短纪录片?我们等会把它揪出来瞅瞅
影片总评分统计如下:
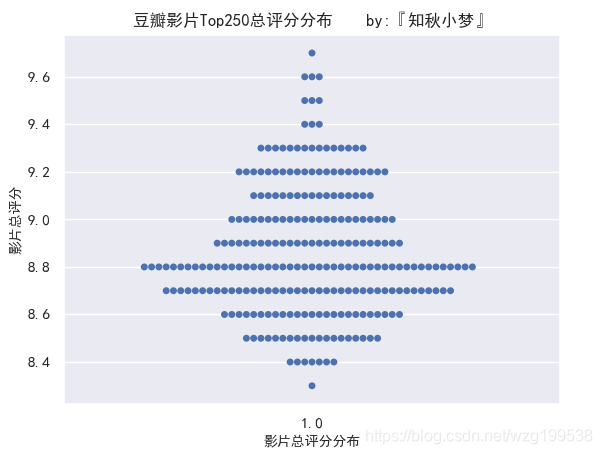
影片总评分最高分9.7,最低分8.3,8.8分的最多。
总评分9.4及以上的有十部,不知道是不是对应的 Top10?
影片评论数统计如下
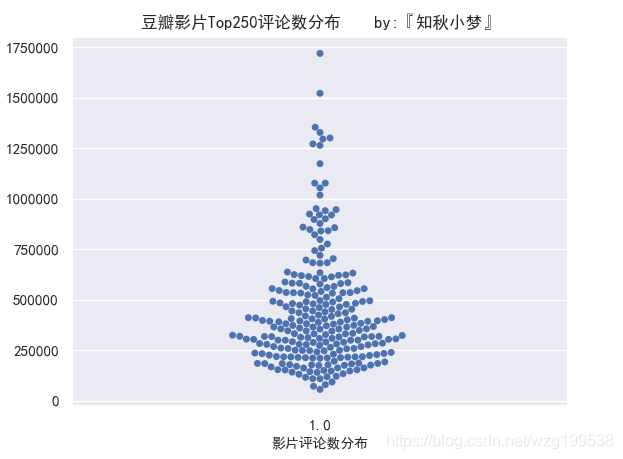
大部分影片的评论数比较集中,评论数在75w人以下。
评论数最多的接近175w人,可以看出差别还是挺明显的。
“思考一下,我们前面提起的 帕累托法则(二八原则)是否适用?”
影片上映日期统计如下:
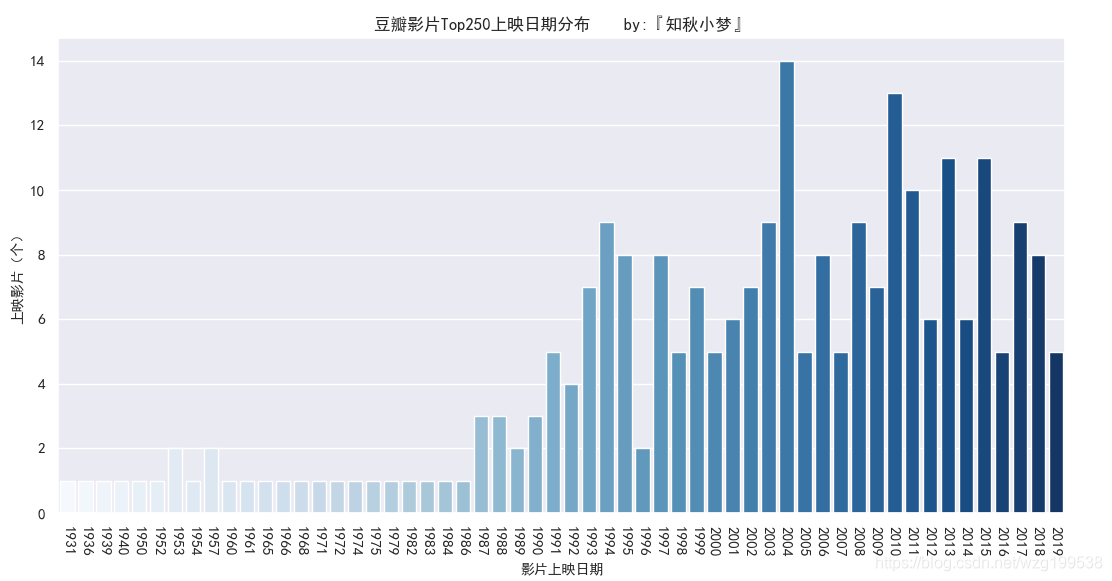
Top250的影片集中在 2000年~2017年,其中2004年上映影片最多,达到14部。
“请问一个月一部大片是什么感觉?小一我也想体验一下!”
影片星级评论占比统计如下:
影片星级分为五级,我们来看一下每个星级的评论数分布:
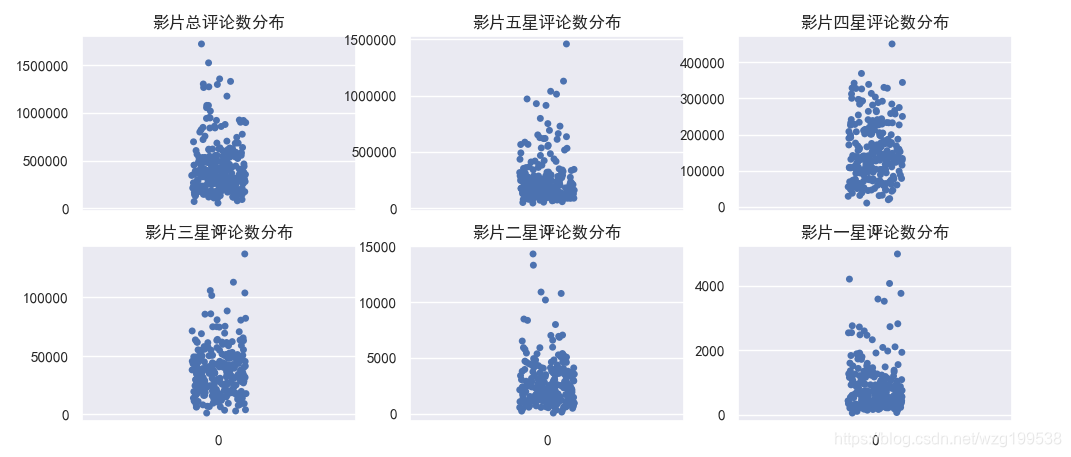
星级分布差别不是很大,但是五星和一星的分布似乎和总评论数的分布更符合。
“看来二八原则的适用性还是挺强的!”
数据探索
上一节我们留下了一些问题,同时还有我们今天的目的:总评分到底与什么相关?都会在这一节去探索
准备好知道答案了吗?
先解决上节问题:
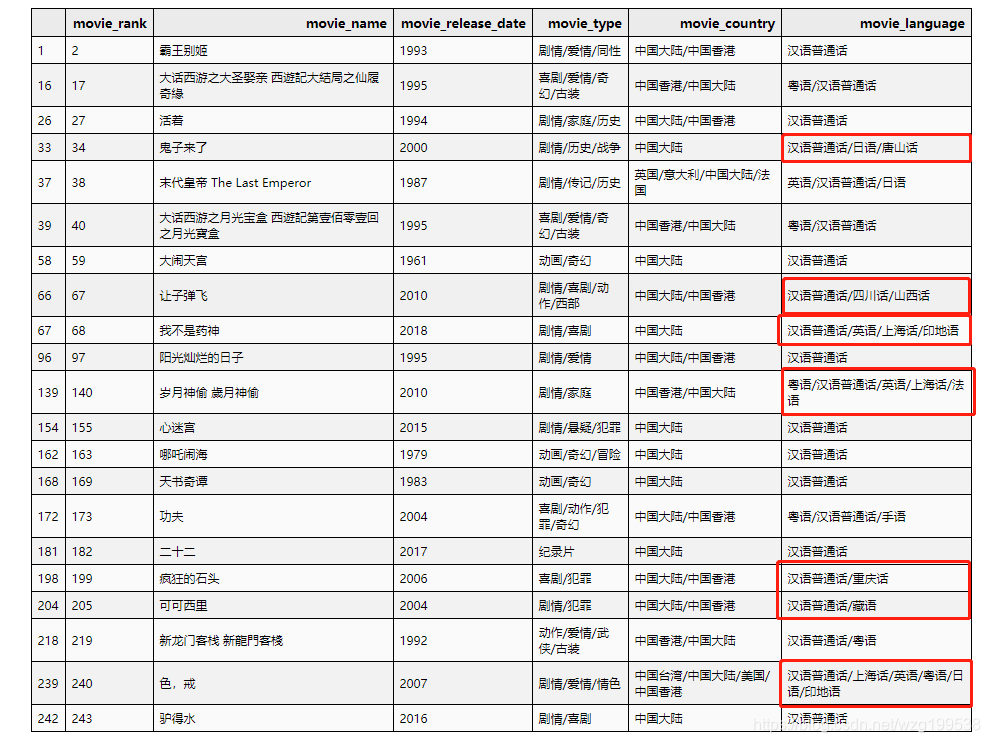
影片语言是中国大陆语言的影片:
# 中国大陆参与制作的影片
df_data[df_data['movie_country'].str.contains('中国大陆')][['movie_rank', 'movie_name', 'movie_release_date', 'movie_type', 'movie_country', 'movie_language']]
影片时长在五十分钟以下的影片:
df_data.sort_values(by='movie_run_time')[['movie_rank', 'movie_name', 'movie_release_date', 'movie_run_time','movie_rating', 'movie_comments_user']].head(1)
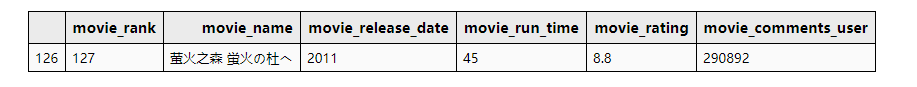
“emmm,是小一我孤陋寡闻了,写完文章我就去看!”
评论数最多的前五部影片:
# 评论数最多的前五条影片
df_data.sort_values(by='movie_comments_user', ascending=False)[['movie_rank', 'movie_name', 'movie_release_date', 'movie_rating','movie_comments_user']].head(5)
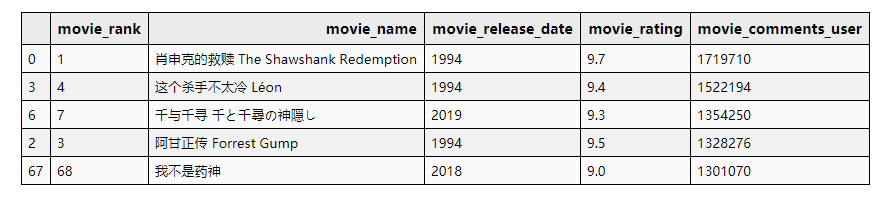
总评论数最多的影片【肖申克的救赎】实至名归。
但是,豆瓣电影Top250排序真的不是按照评论数排序的(①)
评分最高的前五部影片
# 评分最高的前五部影片
df_data.sort_values(by='movie_rating', ascending=False)[['movie_rank', 'movie_name', 'movie_release_date', 'movie_rating','movie_comments_user']].head(5)
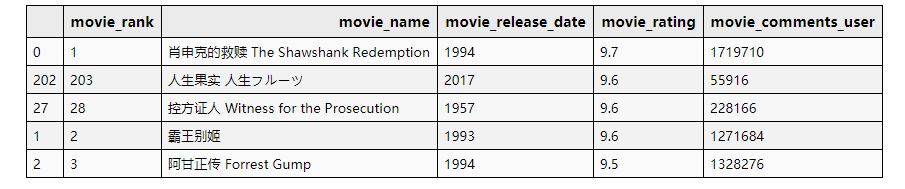
没有悬念,总评分最高还是【肖申克的救赎】。
但是,豆瓣电影Top250排序真的不是按照总评分数排序的(②)
星级评分的前五部电影
我们前面分析出,五星级和一星级分布与总评分吻合,来看一下
# 五星评分人数最多的前五条影片
df_data['five_star_movie_comments_user'] = \df_data['movie_comments_user'] * df_data['movie_five_star_ratio']
df_data.sort_values(by='five_star_movie_comments_user', ascending=False)[['movie_rank', 'movie_name', 'movie_release_date', 'movie_rating','movie_comments_user']].head(5)
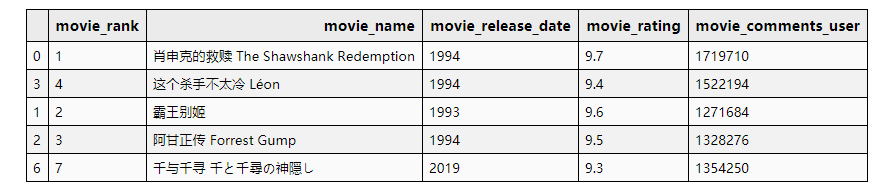
虽然也不对,但是似乎比前面两种的排序靠谱点!(③)
”小一哥,会不会是根据总评分和评论数共同决定排序的?“
”我们来试试“
评分+评论数最高的前五部影片
# 评分+评论数最高的前五部影片
df_data.sort_values(by=['movie_rating', 'movie_comments_user'], ascending=False)[['movie_rank', 'movie_name', 'movie_release_date', 'movie_rating', 'movie_comments_user']].head(5)
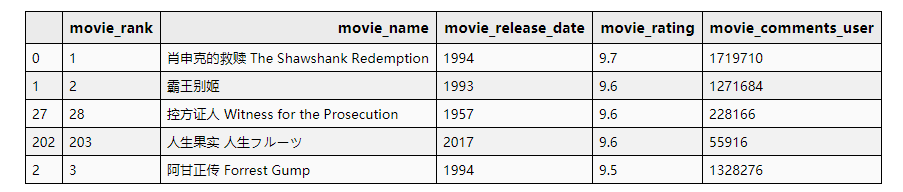
评论数+评分最高的前五部影片
# 评论数+评分最高的前五部影片
df_data.sort_values(by=['movie_comments_user', 'movie_rating'], ascending=False)[['movie_rank', 'movie_name', 'movie_release_date', 'movie_rating', 'movie_comments_user']].head(5)
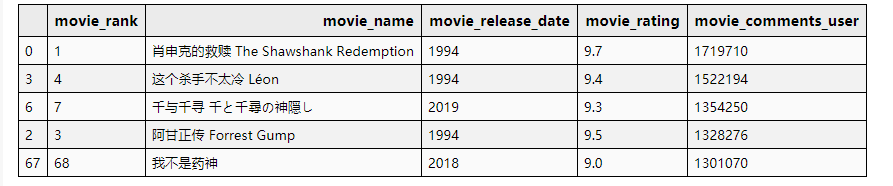
豆瓣电影Top250排序也不是按照评论数+总评分排序的(④)
“还是不对,影片排序不可能是线性这么简单的吧,小一哥?”
“是的,影片排序需要用到一种基于用户投票的排名算法,类似 IMDB 的加权平均,其中一些影评人,电影人的权重都会考虑进去。“”
关于影片排名算法要说清楚的话可能不是一篇文章能搞定的,而且也脱离了我们这一片的重点。
豆瓣影片评分算法并未公开,小一我从网上找到的一篇豆瓣影片评分机制的内容,大家了解了解长个见识就行了:
豆瓣的注册用户看完一部电影,心情好的话会来打个一到五星的分(有时候心情不好也会来)。
比方说一部电影有42万用户打分。我们的程序把这42万个一到五星换算成零到十分,加起来除以42万,就得到了豆瓣评分。
这个评分会自动出现在豆瓣各处,中间没有审核,平时也没有编辑盯着看。每过若干分钟,程序会自动重跑一遍,把最新打分的人的意见包括进来。
——豆瓣创始人阿北
总结一下:
提出假设
针对豆瓣电影数据,我们提出了一些小问题作为我们分析的目的
数据清洗
检查数据整体情况,对缺失数据进行增补,对每个字段的数据检查是否合理,并转换成我们后期需要的数据。
数据可视化
可视化让我们对数据有一个直观的认知,针对不合理数据可以进行二次检查。
数据探索
解决提出的小问题,针对目标进行深层次的分析。
当然,我们这里欠缺最后一步:特征工程和评分模型。(本次分析用不到)
思考
以上就是我们今天分析实战的主要内容,很基础,但是内容也很多,第一个分析项目,旨在让大家了解分析流程。
觉得今天内容量不够的同学,也可以思考一下以下几个问题:
- 还有哪些维度可以互相组合并对总排序造成影响?
- 它们的可视化显示你能画出来吗?
- 评分模型应该怎么设计(可以参考阮一峰的排名算法)?
源码获取
目前为止,和我们豆瓣电影相关的源码如下:
在公众号后台回复 豆瓣电影 获取 爬取豆瓣电影Top250源码
在公众号后台回复 电影数据 获取 豆瓣电影Top250详细数据
在公众号后台回复 电影分析 获取 分析豆瓣电影Top250源码
写在后面的话
第一个实战项目结束了,有部分内容其实并没有说清楚,只是直接拿来了用,不知道你们能不能理解。
不过,这两篇内容都只是我们的一个基础文章,重点是流程,不必去细究其中某个细节。
我已经想好了下一个项目应该玩什么了,你们准备好了吗?
下期见!
碎碎念一下
写技术文难了不止一个档次是因为要把内容输出成文章,还是挺难的。
我代码实现两个晚上就写完了,但是写这篇却用了我
整个周末的时间,点个赞支持一下?
原创不易,欢迎点赞噢
文章首发:公众号【小一的学习笔记】
原文链接:你知道豆瓣电影是怎么评分的吗?













