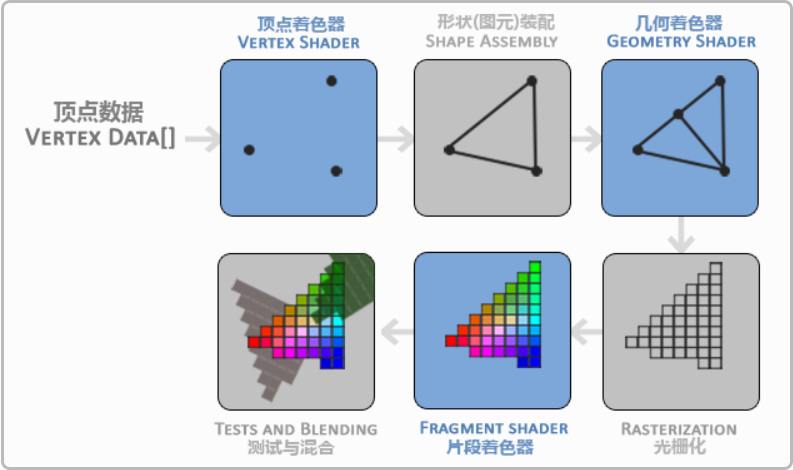
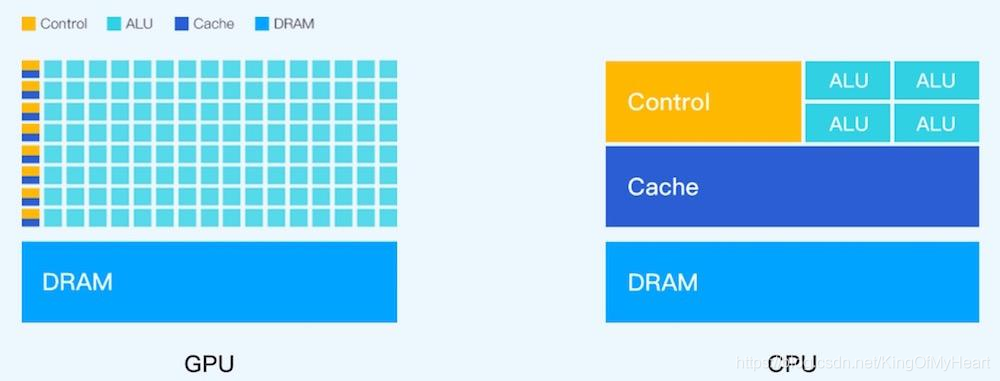
一、参考资料
NVCC学习笔记
NVIDIA GPU 架构演进
Nvidia GPU架构 - Cuda Core,SM,SP等等傻傻分不清?
请问英伟达GPU的tensor core和cuda core是什么区别?
CUDA 专栏
二、相关概念
2.1 dGPU
dGPU(discrete GPU),独立显卡。
2.2 FLOPS(Floating-point operations per second)
每秒浮点运算次数(亦称每秒峰值速度)是每秒所运行的浮点运算次数;
一个MFLOPS(megaFLOPS)等于每秒一百万(10^6)次的浮点运算;
一个GFLOPS(gigaFLOPS)等于每秒十亿(10^9)次的浮点运算;
一个TFLOPS(teraFLOPS)等于每秒一兆/一万亿(10^12)次的浮点运算;
一个PFLOPS(petaFLOPS)等于每秒一千兆/一千万亿(10^15)次的浮点运算;
一个EFLOPS(exaFLOPS)等于每秒一百京/一百亿亿(10^18)次的浮点运算;
2.3 TOPS(Tera Operations Per Second)
1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作。
2.4 SM流处理器
流式传输多元处理器。
2.5 SMP(SM Processing Block)
流处理块。比如GPU Pascal架构里,每个SM由两个SMP组成。
1 SM = 2个SMP = 64 CUDA Core + 1 RT Core + 8 Tensor Core
2.6 CUDA Core

CUDA Core(Shader processors),也称为Streaming Processor(SP),是 全能通吃型的浮点运算单元。CUDA Core名称正式出现的位置是在Fermi架构(2010年),在此之前称为processor core ,也称为streaming processors (SPs) 或者称为 thread processors。CUDA Core在显卡里是并行运行的,CUDA Core越多,算力越强。
CUDA Core包含了一个 integer arithmetic logic unit (ALU)整数运算单元和一个 floating point unit (FPU)浮点运算单元。CUDA Core能进行一种fused multiply-add (FMA)的操作,即一个加乘操作的融合。特点:在不掉精度的情况下,单指令完成乘加操作,并且这个是支持32-bit精度。
更通俗一点,比如公式:
Z = W ∗ X + b Z = W * X + b Z=W∗X+b

输出Z等于W乘以输入X加上bias,深度学习中,有大量这种运算。如果用常规的CPU,会怎么处理呢?先把寄存器里面的数据送入乘法器,然后把结果送回寄存器,然后再把寄存器的数据送入加法器。但是,在CUDA Core中,单指令完成该运算。
但是,对于一些场景,比如混合精度的矩阵操作,CUDA Core计算不是很高效,于是NVIDIA就开始专门针对tensor张量运算的硬件单元Tensor Core。
2.7 RT Core(光线追踪运算核心)
光线跟踪专用的运算单元。
2.8 Tensor Core(硬件核)
张量运算核心Tensor Core;
深度学习运算单元Tensor Core;
Tensor Core比流处理器更强大的专门针对 深度学习矩阵操作 有特别优化的一个运算核;
Tensor Core第一代是在volta架构上推出的,格外擅长加速 矩阵—矩阵乘法,这是训练神经网络和推理功能的核心算法,换句话说,这就是机器学习所必须的硬件基础。
2.9 DLA单元(Deep Learning Accelerator)
深度学习加速器。
Nvidia DLA is designed specifically for the deep learning use case and is used for offload the inference effort from GPU.
These engines improve energy efficiency and free up the GPU to run more complex networks and dynamic tasks implemented by the user.
2.10 LD/ST(load store unit)
用来操作内存的。
2.11 SFU(Special function unit)
用来做cuda的intrinsic function的。
2.12 TensorRT(软件库)
加快推断(inference)的速度。
Nvidia:CUDA GPU,面向嵌入式的Jetson;
Intel:Movidius VPU(NCS2);
Apple:A12处理器(及之后)上的NPU;
高通:骁龙处理器(上的AIE引擎,目前到了第5代);
华为:麒麟处理器(达芬奇架构);
2.13 NVIDIA的显卡架构出道顺序
- Tesla1.0 (2006年, 代表GeForce8800)
- Tesla2.0 (GT200)
- Fermi(算力可以支撑深度学习啦)
- Kepler(core增长)
- Maxwell(core继续增长)
- Pascal(算力提升)
- Volta(第一代tensor core)
- Turning(第二代 tensor core)
- Ampere(第三代tensor core)
2.14 AI程序如何调用显卡计算资源
用户代码 -> AI框架(PyTorch/Tensorflow/Caffe等)-> CUDA lib -> Driver -> 显卡。
三、GPU架构
查看显卡驱动、算力、cuda版本
compute-capabilities
Matching CUDA arch and CUDA gencode for various NVIDIA architectures
计算能力并不是描述GPU设备计算能力强弱的绝对指标,准确的说,这是一个架构的版本号。一般来说,越新的架构版本号更高,计算能力的第一个数值也就最高(例如3080计算能力8.6),而后面的6代表在该架构前提下的一些优化特性。
GPU的“代”
CUDA:NVCC编译过程和兼容性详解
GPU有个重要参数,计算能力,计算能力的值对应GPU的“代”值,如计算能力3.0,对应的“代”为sm_30,也对应kepler架构。
为了实现GPU架构的演变,NVIDIA GPU以不同代次发布。新一代产品在功能和/或芯片架构方面会引入重大改进,而同一代产品中的GPU模型显示出较小的配置差异,对功能和/或性能产生中等的影响。
实践证明,计算能力高的GPU可以运行编译成低代的程序,反之则不行,如计算能力6.1的GPU可以运行编译成compute_30,sm_30的程序;例如-arch=compute_30;-code=sm_30表示计算能力3.0及以上的GPU都可以运行编译的程序,但计算能力2.0的GPU就不能运行了。
GPU的小“代”
CUDA:NVCC编译过程和兼容性详解
除了sm_20,sm_30,sm_50,sm_60这些大的代号,还有sm_21, sm_35, sm_53 ,sm_61这些小代,这些小代不会做大的改变,会有一些小的调整,如调整寄存器和处理器集群的数量,这只影响执行性能,不会改变功能。程序更精确的对应GPU代号可能可以达到最佳性能。
3.1 Fermi(费马架构)
- CUDA 3.2 until CUDA 8
- SM20 or
SM_20, compute_30–
GeForce 400, 500, 600, GT-630.

每个 SM 包含:
- 2 个 Warp Scheduler/Dispatch Unit;
- 32 个 CUDA Core(分在两条 lane 上,每条分别是 16 个)
- 每个 CUDA Core 里面是 1 个单精浮点单元(FPU)和 1 个整数单元(ALU),可以直接做 FMA 的乘累加;
- 每个 cycle 可以跑 16 个双精的 FMA;
- 16 个 LD/ST Unit;
- 4 个 SFU;
3.2 Kepler(开普勒架构)
- CUDA 5 until CUDA 10
- SM30 or
SM_30, compute_30–
Kepler architecture (e.g. generic Kepler, GeForce 700, GT-730).
Adds support for unified memory programming
Completely dropped from CUDA 11 onwards. - SM35 or
SM_35, compute_35–
Tesla K40.
Adds support for dynamic parallelism.
Deprecated from CUDA 11, will be dropped in future versions. - SM37 or
SM_37, compute_37–
Tesla K80.

每个 SM包含:
- 4 个 Warp Scheduler,8 个 Dispatch Unit;
- CUDA Core 增加到 192 个(4 * 3 * 16,每条 lane 上还是 16 个);
- 单独分出来 64 个(4 * 16,每条 lane 上 16 个)双精运算单元。;
- SFU 和 LD/ST Unit 分别也都增加到 32 个;
3.3 Maxwell(麦克斯韦架构)
- CUDA 6 until CUDA 11
- SM50 or
SM_50, compute_50–
Tesla/Quadro M series.
Deprecated from CUDA 11, will be dropped in future versions, strongly suggest replacing with a Quadro RTX 4000 or A6000. - SM52 or
SM_52, compute_52–
Quadro M6000 , GeForce 900, GTX-970, GTX-980, GTX Titan X. - SM53 or
SM_53, compute_53–
Tegra (Jetson) TX1 / Tegra X1, Drive CX, Drive PX, Jetson Nano.

每个SM包含:
- 4个 Warp Scheduler,8个 Dispatch Unit;
- 128个CUDA Core(4 * 32);
- 32个 SFU 和 LD/ST Unit(4 * 8);
每个 Process Block包含:
- 1个Warp Scheduler 和 2个 Dispatch Unit;
- 32个 CUDA Core;
- 8个 SFU 和 LD/ST Unit;
3.4 Pascal (帕斯卡架构)
- CUDA 8 and later
- SM60 or
SM_60, compute_60–
Quadro GP100, Tesla P100, DGX-1 (Generic Pascal) - SM61 or
SM_61, compute_61–
GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030 (GP108), GT 1010 (GP108) Titan Xp, Tesla P40, Tesla P4, Discrete GPU on the NVIDIA Drive PX2 - SM62 or
SM_62, compute_62–
Integrated GPU on the NVIDIA Drive PX2, Tegra (Jetson) TX2
Pascal架构是NVIDIA于 GTC 2016发布的GPU架构,CUDA Core在这一代终于有升级,硬件直接支持FP16的半精度计算,半精度性能是单精度的2倍,一个单精度单元用两个半精度计算。

每个SM包含:
- 2个 Warp Scheduler,4个Dispatch Unit;
- 64个 CUDA Core(2 * 32);
- 32个双精度浮点单元(2 * 16);
- 16个 SFU 和 LD/ST Unit(2 * 8);
每个 Process Block包含:
- 1个Warp Scheduler 和 2个 Dispatch Unit;
- 32个 CUDA Core;
- 多了16个 DP Unit;
- 8个SFU 和 LD/ST Unit;
3.5 Volta架构
深度解析Volta架构,专为深度学习而生的Tensor Core
- CUDA 9 and later
- SM70 or
SM_70, compute_70–
DGX-1 with Volta, Tesla V100, GTX 1180 (GV104), Titan V, Quadro GV100 - SM72 or
SM_72, compute_72–
Jetson AGX Xavier, Drive AGX Pegasus, Xavier NX
服务器级别显卡P100;
专业级的RTX 8000/6000/5000;
消费级的RTX 2080 Ti/2080/2070显卡;
Volta架构是NVIDIA于 GTC 2013发布的GPU架构。Volta架构专为计算和数据科学而打造,通过将 NVIDIA® CUDA® 和 Tensor 核心配合使用,可以在单个 GPU 中提供 AI 超级计算机的性能。

每个SM包含:
- 4 个 Warp Scheduler,4 个 Dispatch Unit;
- 64 个 FP32 Core(4 * 16);
- 64 个 INT32 Core(4 * 16);
- 32 个 FP64 Core(4 * 8);
- 8 个 Tensor Core (4 * 2);
- 32 个 LD/ST Unit(4 * 8);
- 16 个 SFU;
每个 Process Block 包含:
- 1 个 Warp Scheduler,1 个 Dispatch Unit;
- 16 个 FP32 Core;
- 16 个 INT32 Core;
- 8 个 FP64 Core;
- 2 个 Tensor Core;
- 8 个 LD/ST Unit;
- 4 个 SFU;
3.6 Turning(图灵架构)
- CUDA 10 and later
- SM75 or
SM_75, compute_75–
GTX/RTX Turing – GTX 1660 Ti, RTX 2060, RTX 2070, RTX 2080, Titan RTX, Quadro RTX 4000, Quadro RTX 5000, Quadro RTX 6000, Quadro RTX 8000, Quadro T1000/T2000, Tesla T4
Turning架构是NVIDIA于 在 SIGGRAPH 2018发布的GPU架构,Turning图灵架构的光线跟踪特性,实际上是旧有光线跟踪技术与近年兴起的人工智能(AI)、深度学习结合的产物,先是利用光线跟踪专用的运算单元RT core生成图像的关键要素,剩余的非关键要素则是交由深度学习运算单元Tensor Core来补全。
在Turning图灵架构中,每个SM单元包含了64个CUDA核心、1个RT核心和8个张量核心,1 SM = 64 CUDA Core + 1 RT Core + 8 Tensor Core
RTX 2080、RTX 2080ti是图灵架构,具有实时光线跟踪(Ray tracing)功能。RTX 2070 SUPER的SM单元数量比RTX 2070多4个,达到40个。由于在图灵架构中,每个SM单元包含了64个CUDA核心、1个RT核心和8个张量核心,所以RTX 2070 SUPER的CUDA核心数增加到2560个,而RTX 2070的CUDA核心数为2304个,同时前者的RT核心和张量核心分别增加了4个和32个。

每个 SM 包含:
- 4 个 Warp Scheduler,4 个 Dispatch Unit;
- 64 个 FP32 Core(4 * 16);
- 64 个 INT32 Core(4 * 16);
- 8 个 Tensor Core(4 * 2);
- 16 个 LD/ST Unit(4 * 4);
- 16 个 SFU;
每个 Process Block 包含:
- 1 个 Warp Scheduler,1 个 Dispath Unit;
- 16 个 FP32 Core;
- 16 个 INT32 Core;
- 2 个 Tensor Core;
- 4 个 LD/ST Unit;
- 4 个 SFU;
3.7 Ampere(安培架构)
- CUDA 11.1 and later
-
SM80 or
SM_80, compute_80–
NVIDIA A100 (the name “Tesla” has been dropped – GA100), NVIDIA DGX-A100 -
SM86 or
SM_86, compute_86–
Tesla GA10x cards, RTX Ampere – RTX 3080, GA102 – RTX 3090, RTX A2000, A3000, RTX A4000, A5000, A6000, NVIDIA A40, GA106 – RTX 3060, GA104 – RTX 3070, GA107 – RTX 3050, RTX A10, RTX A16, RTX A40, A2 Tensor Core GPU -
SM87 or
SM_87, compute_87– , introduced with PTX ISA 7.4 / Driver r470 and newer) – for Jetson AGX Orin and Drive AGX Orin only
Ampere架构是NVIDIA于 GTC 2020发布的GPU架构,NVIDIA Ampere 由540亿晶体管组成,是7nm芯片。

每个 SM 包含:
- 4 个 Warp Scheduler,4 个 Dispatch Unit;
- 64 个 FP32 Core(4 * 16);
- 64 个 INT32 Core(4 * 16);
- 32 个 FP64 Core(4 * 8);
- 4 个 Tensor Core (4 * 1);
- 32 个 LD/ST Unit(4 * 8);
- 16 个 SFU;
每个 Process Block 包含:
- 1 个 Warp Scheduler,1 个 Dispatch Unit;
- 16 个 FP32 Core;
- 16 个 INT32 Core;
- 8 个 FP64 Core;
- 1 个 Tensor Core;
- 8 个 LD/ST Unit;
- 4 个 SFU;
3.8 Lovelace
- CUDA 11.8 and later
- SM89 or
SM_89, compute_89–
NVIDIA GeForce RTX 4090, RTX 4080, RTX 6000, Tesla L40
3.9 Hopper
- CUDA 12 and later
- SM90 or
SM_90, compute_90–
NVIDIA H100 (GH100)
四、算力
Matching CUDA arch and CUDA gencode for various NVIDIA architectures
CUDA:NVCC编译过程和兼容性详解
4.1 算力表
NVIDIA算力表
【原】CUDA的deviceQuery命令
4.2 GPU处理能力(TFLOPS/TOPS)
GPU处理能力(TFLOPS/TOPS)
GPU运算能力对比(详细)
4.3 不同算力支持的量化等级
hardware-precision-matrix
GPU有个重要参数-算力,算力值对应GPU的“代”值,如算力5.0,对应的“代”为sm_50,也对应Maxwell架构。
为了实现GPU架构的演变,NVIDIA GPU以不同代次发布。新一代产品在功能和/或芯片架构方面会引入重大改进。同一代产品中的GPU模型显示出较小的配置差异,对功能和/或性能产生中等的影响。
除了sm_20,sm_30,sm_50这些大的代号,还有sm_21,sm_35,sm_53这些小代,这些小代不会做大的改变,会有一些小的调整,如调整寄存器和处理器集群的数量。这只影响执行性能,不会改变功能。程序更精准的对应GPU代号可能达到最佳性能。
在实际结论中,compute_30以上的程序,算力高的GPU可以运行编译成低代的程序,反之则不行,如算力5.0的GPU可以运行编译成compute_30,sm_30的程序。虚拟框架由compute_开头,真实框架由sm_开头。
'-gencode', 'arch=compute_50,code=sm_50'
表示算力5.0以上的GPU都可以运行编译的程序,但算力3.0的GPU就不能运行了。
-gencode,-genarate-code的缩写,保证用户GPU可以动态选择最合适的GPU架构(最适合GPU的大代和小代)

五、相关介绍
5.1 GPU类型
- 用于训练的DGX;
- 用于超大规模云的HGX;
- 用于边缘的EGX;
- 用于终端的AGX;
5.2 搭建GPU服务器
【保姆级教程】个人深度学习工作站配置指南
个人深度学习工作站-效果演示
实验室多用户GPU深度学习环境搭建
5.3 GPU虚拟化技术
GPU有哪些虚拟化手段?
启用Docker虚拟机GPU,加速深度学习
5.4 GPU支持的编解码器
Video Encode and Decode GPU Support Matrix
NVIDIA VIDEO CODEC SDK
5.5 GPU购买参数和对比
六、特殊产品
6.1 Xavier SOC
参考资料
NVIDIA声称Xavier是迄今为止发明的最复杂的SOC
NVIDIA Jetson Xavier性能首测:AI性能碾压苹果A12,自研CPU架构看齐骁龙845
- 用于无人机和机器人的Jetson Xavier;
- 用于诸如L3-4级驾驶辅助的Drive Xavier;
- 旗舰Drive Pegasus,具有双Xavier SOC和2瓦GPU,以支持完全自动驾驶的L5级别;

6.2 Jetson平台
CUDA 初学者统一内存
CUDA中的Unified Memory
Jetson是NVIDIA嵌入式产品,不存在独立的显存和内存,即CPU和GPU共用存储器。
硬件参数对比
极智AI | 英伟达 Jetson 系列边缘盒子硬件参数汇总
性能对比
极智AI | 英伟达 Jetson 系列边缘盒子性能测评
6.2.1 Jetson TK1
2018年已经下架
属于探索性产品
6.2.2 Jetson Nano
AI | Nvidia Jetson Nano介绍与使用指南
Jetson-Nano开箱配置及Tensorflow安装使用
Jetson Nano 开发者套件入门
Nano入门教程基础篇
Jetson Nano系列教程
售价899RMB
最新推出,主打便宜

6.2.3 Jetson TX2
教育售价2899RMB
迭代升级
6.2.4 Jetson Xavier NX
教育售价2899RMB
迭代升级
6.2.5 Jetson AGX Xavier
教育售价7099RMB
迭代升级
专为自动驾驶技术和汽车产品使用的超算解决方法,是所谓的车规级SoC芯片。
| Jetson Nano | Jetson TX2 | Jetson Xavier NX | Jetson AGX Xavier | |
|---|---|---|---|---|
| 架构 | Maxwell™ | Pascal™ | Volta™ | Volta™ |
| NVIDIA CUDA 核心 | 128 | 256 | 384 | 512 |
| Tensor 核心 | 48 | 64 |

6.2 RTX3060
RTX3060是安培构架,CUDA Compute Capability of the GeForce 30 series is 8.6。
- CUDA SDK 11.0 support for compute capability 3.5 – 8.0 ;
- CUDA SDK 11.1 – 11.6 support for compute capability 3.5 – 8.6 所以,RTX3060对应的CUDA≥11.1;
RTX3060不支持CUDA 11以下版本,会报错:cuda的算力要支持你的显卡算力。
七、可能出现的问题
RTX 3060驱动版本不兼容
Win10+RTX3060配置CUDA等深度学习环境
错误原因:
当前驱动版本与RTX 3060不匹配。解决办法:
下载RTX 3060对应版本的驱动,重新安装驱动。