GPU结构设计
1. 框架设计
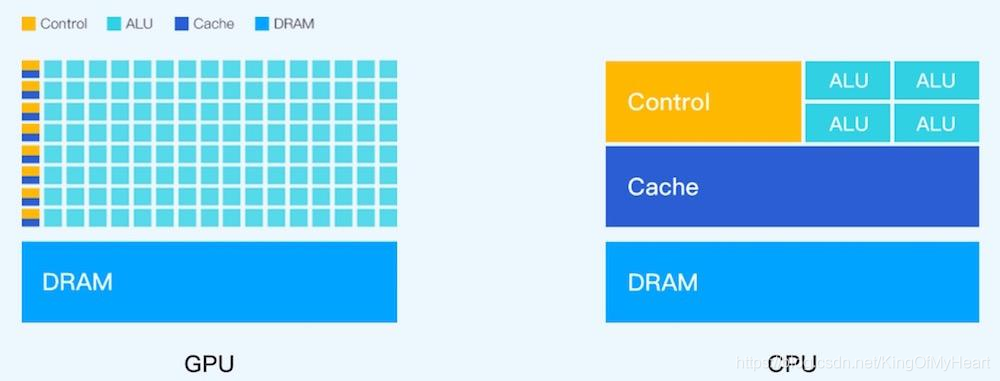
GPU 即 graphics process unit,图形处理单元,其主要功能在于图形渲染和合成,擅长于浮点运算和三角形生成填充处理;
本部分主要回答:GPU如何实现让自己擅长于图形渲染和合成操作?
1.1 GPU 发展演变
技术的发展大多都有其需求依赖,GPU也是一样:
1962年麻省理工学院的博士伊凡•苏泽兰发表的论文以及他的画板程序奠定了计算机图形学的基础。在随后的近20年里,计算机图形学在不断发展,但是当时的计算机却没有配备专门的图形处理芯片,图形处理任务都是CPU来完成的。
这是需求产生的初始;
1999年8月,NVIDIA公司发布了一款代号为NV10的图形芯片Geforce 256。Geforce 256是图形芯片领域开天辟地的产品,因为它是第一款提出GPU概念的产品。Geforce 256所采用的核心技术有“T&L”硬件、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。“T&L”硬件的出现,让显示芯片具备了以前只有高端工作站才有的顶点变换能力,同时期的OpenGL和DirectX 7都提供了硬件顶点变换的编程接口。GPU的概念因此而出现
2000年之前出现了早期的GPU产品,即独立用于图形绘制的硬件模块;
即伴随着图形学的发展,对于计算机算力的要求越来越高,而CPU的性能的发展已经到达一个平缓期,无法满足其需求,所以需要单独拉出来一个模块用于满足其算力需求;
提高运算速度的方式主要有如下几个方面:
- 单条指令执行速度:提高主频
- 到达当前4GHZ 之后再向上增加,伴随着功耗的几何倍增;
- 增加运算单元数量(晶体管)
- 制程发展,目前已经达到nm级别,达到当前技术的极限;
- 改变当前CPU中的晶体管功能,让其善于绘图,即GPU;
- 在宏观层面增加,即近些年来的多核发展,以及异构框架设计;
所以伴随着2-2这样一个朴素的思维逻辑(专精),GPU硬件模块被设计出来了;
上述我们描述了GPU是被设计用于专门绘制图形的硬件模块,那么图形绘制相较于曾经的运算而言,有哪些专门的内容?
图形绘制:经过一定运算,将图片转换为数据显示在屏幕上,即计算每个像素需要显示的颜色数值(YUV)
则至少有如下三方面的要求:
- 高性能的运算,将图片效果(3D效果)转换为像素点的过程;
- 大量的并行计算,对于一定范围的像素,进行相同的运算处理;
- 超高访问内存带宽,即刷图的特性要求其吞吐量要高;
基于上述的目标,我们首先来看CPU的设计结构;
1.2 从CPU开始聊起
CPU (Central process unit) 中央处理器,作为计算机系统的运算和控制核心,是信息处理,程序运行的最终执行单元;
从词条介绍就可以看得出来,CPU是运算和控制核心,是程序运行的最终执行单元,CPU面向通用的场景,更关注复杂场景的时延和指令的执行效率,即面对不同的程序,以尽快的速度运行:
-
多级流水线
指令从取值到真正执行的过程划分成多个小步骤,cpu真正开始执行指令序列时,一步压一步的执行,减少其等待时间(比如正常需要4~5cycle,采用流水线则相当于平均1 cycle)
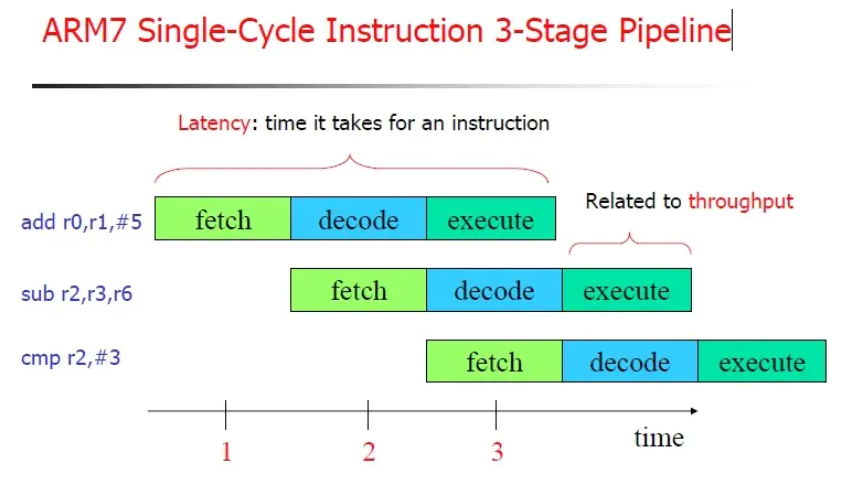
上述图示为arm7 三级流水线标准结构,arm9和mips均采用5级流水线:
IF – ID – EX – MEM – WB
-
指令级别并行:
- 超线程,Intel提出的技术,即一个CPU核划分为两个线程,即将其他资源利用起来,避免等待;
- 超标量,多条流水线并行,空间换时间;
- 超长指令字,编译优化,一次提取多条不互相依赖的指令进行处理(编译阶段)
-
分支预测:
上述流水线的结构,针对于分支结构会出现效率降低,即在执行下一条指令时,当前判断语句还未执行完成,如果判断出错,则相当于将分支语句中内容执行一遍,此种情况下等待判断完成会导致整个硬件模块先暂停再重新启动,效率极低:
- 直接执行,成功率在50%,如果出错则绕回重新执行;
- 分支预测,在进行之前即预测其if or else,现代计算机基本在95%以上,依赖于一定的硬件单元模块;
-
乱序执行:
很显然的一个特性,指令在执行时常常因为一些限制而等待,比如,mem分阶段访问数据不再cache中,则需要从外部存储器获取,至少需要几十个cycle的时间,所以这种情况下可以采用乱序执行的方式,先执行不依赖于外部数据的指令;
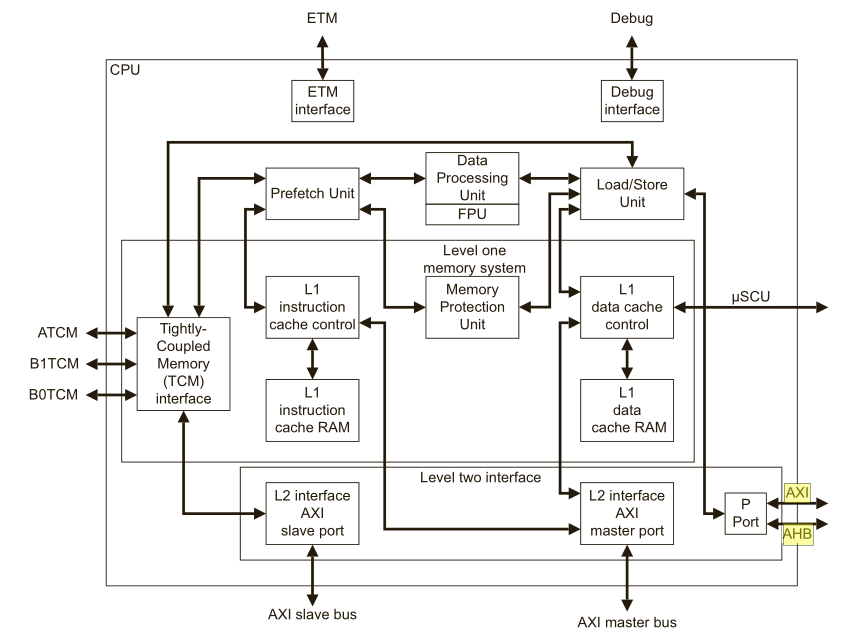
这里是一个比较简单的CPU的结构,其中大面积的单元结构是Cache & Prefetch Unit(复杂控制逻辑电路,包括并不限于PFU)而对于GPU来说,执行数据比较单纯,多半是对于像素进行的运算处理,而且是大面积的并行计算,所以砍去其复杂的逻辑电路,转换为计算单元:
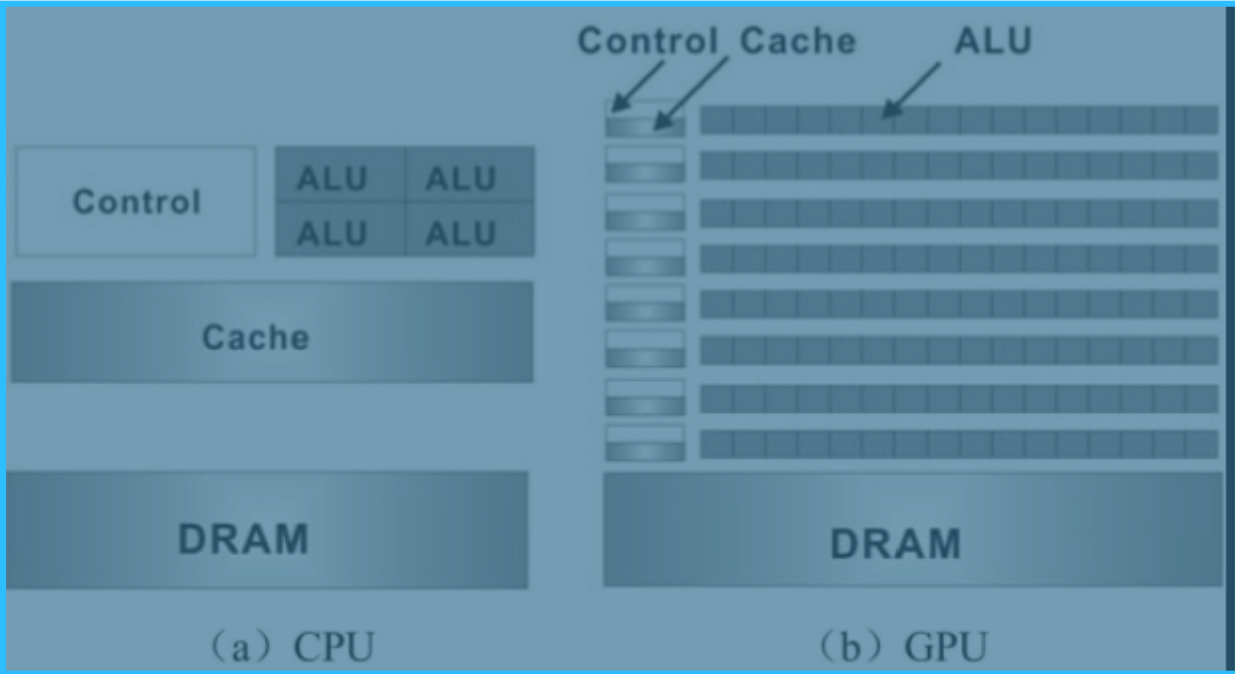
从设计思路来说,已经决定了GPU不善于做分支运算,效率极低;
2. 结构设计
了解了上述的设计需求以及设计思想,则具体来看当前GPU的设计:
2.1 MALI系列GPU结构框架描述
这里主要聊ARM MALI系列,首先来看Mali家族的GPU框架(以下资料均来自ARM官网):
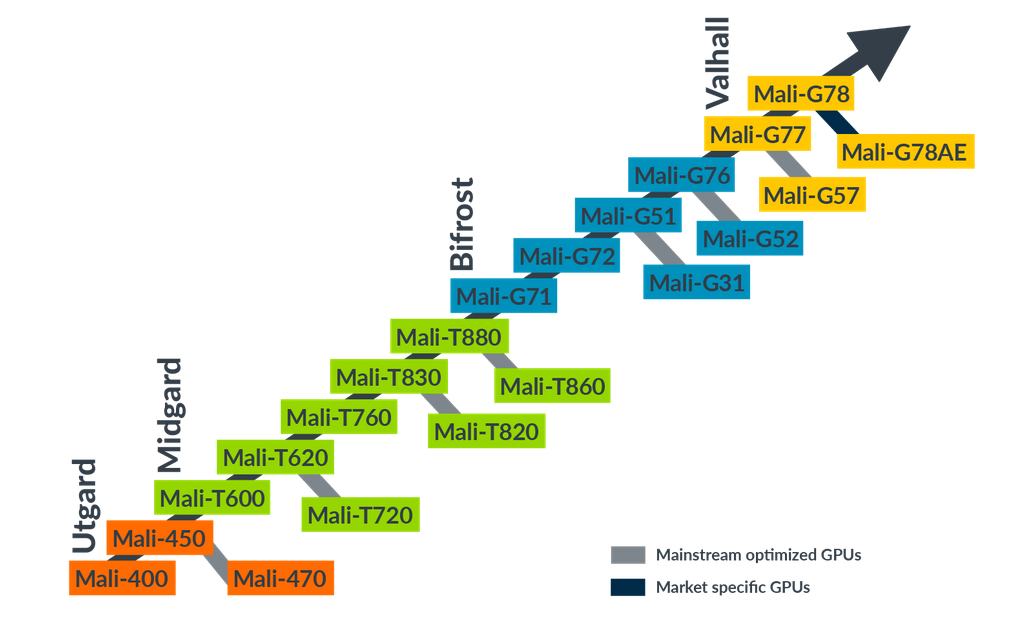
上述主要包括Mali家族的四个框架结构:
Utgard:早期结构,vertex 和 fragment 为独立的硬件单元结构;
Midgard:这里学习的主体,通用可编程shader core;
Bifrost、Valhall 这里没有详细了解,可以支持gles 3.2 & vulkan;
2.1.1 Midgard 结构
Top-Level如下图所示:
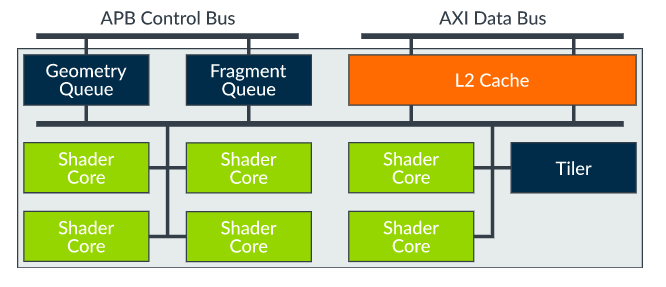
- 操作指令进来两个Queue,用于分别管理Geometry 和 Fragment;
- 数据进来到L2 Cache中,这里应该有MMU的控制单元;
- Shader core是可变的,根据各个厂商定制,一般来说2~8个,也是实际运算单元存在的位置;
- Tiler是Mali的一个特殊技术,将Texture划分为小块进行缓存计算,主要是为了减小带宽压力;
详细来看Shader Core:
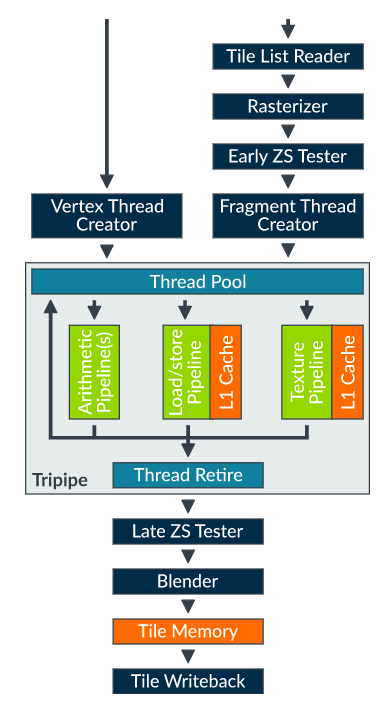
- 三级执行单元,在一个cycle内,可以并行 Arithmetric / LSU / Texture
- ZS Tester 用于做深度计算,剔除不需要显示的部分;
- Arithmetric 单元模块用来做几何运算部分,即顶点计算、几何连线运算等;
- L1 Cache 16Kb,可根据厂商要求定制;
对于Arithmetric 单元,该部分与NVIDIA设计不同,仍采用SIMD结构(VLIW):
The Arithmetic pipeline (A-pipe), is a Single Instruction Multiple Data (SIMD) vector processing engine, with arithmetic units that operate on 128-bit quad-word registers. The registers can be accessed as several different data types, for example, as 4xFP32/I32, 8xFP16/I16, or 16xI8. Therefore, a single arithmetic vector operation can process eight
mediumpvalues in a single cycle.
Mali结构简单来说就是这个样子了;
2.2 NVIDIA 简易介绍
2.2.1 结构
顶层结构:
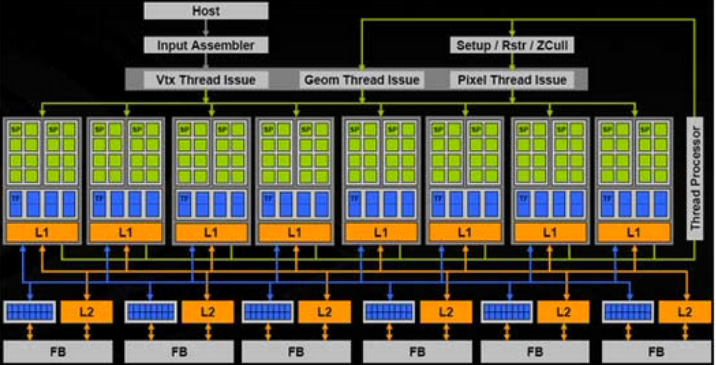
放大:
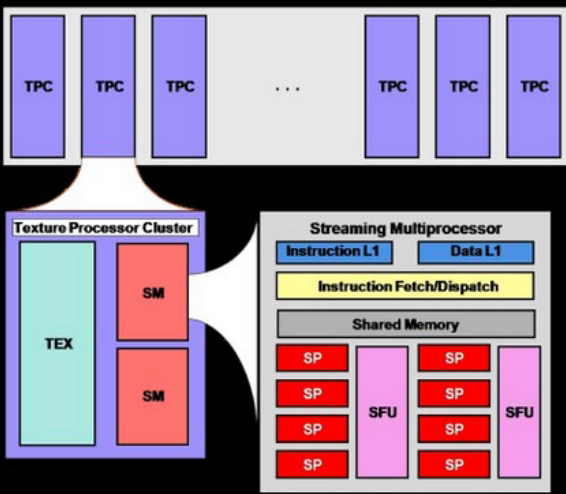
NVIDIA GPU架构发展时间记录:
-
2008 - Tesla
Tesla最初是给计算处理单元使用的,应用于早期的CUDA系列显卡芯片中,并不是真正意义上的普通图形处理芯片。
-
2010 - Fermi
Fermi是第一个完整的GPU计算架构。首款可支持与共享存储结合纯cache层次的GPU架构,支持ECC的GPU架构。
-
2012 - Kepler
Kepler相较于Fermi更快,效率更高,性能更好。
-
2014 - Maxwell
其全新的立体像素全局光照 (VXGI) 技术首次让游戏 GPU 能够提供实时的动态全局光照效果。基于 Maxwell 架构的 GTX 980 和 970 GPU 采用了包括多帧采样抗锯齿 (MFAA)、动态超级分辨率 (DSR)、VR Direct 以及超节能设计在内的一系列新技术。
-
2016 - Pascal
Pascal 架构将处理器和数据集成在同一个程序包内,以实现更高的计算效率。1080系列、1060系列基于Pascal架构
-
2017 - Volta
Volta 配备640 个Tensor 核心,每秒可提供超过100 兆次浮点运算(TFLOPS) 的深度学习效能,比前一代的Pascal 架构快5 倍以上。
-
2018 - Turing
Turing 架构配备了名为 RT Core 的专用光线追踪处理器,能够以高达每秒 10 Giga Rays 的速度对光线和声音在 3D 环境中的传播进行加速计算。Turing 架构将实时光线追踪运算加速至上一代 NVIDIA Pascal™ 架构的 25 倍,并能以高出 CPU 30 多倍的速度进行电影效果的最终帧渲染。2060系列、2080系列显卡也是跳过了Volta直接选择了Turing架构。
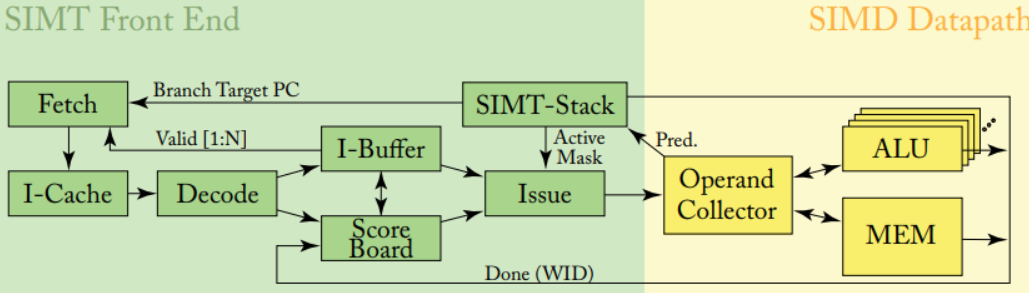
2.2.2 SIMT
SIMT:单指令多线程,相较于SIMD不需要开发者考虑矢量长度组合,相当于使用一定数量的core用于并行执行,有自己的register;
Wrap 线程束,一般包含32个线程,执行相同指令(不同数据)
- wrap有自己的register:
- 遇到LSU等待可以直接切换其他wrap
- Wrap数量越多则平均等待时间越短,并行执行后忽略等待;
- 由于硬件决定Register总数一定,shader程序中使用register多则分配warp的数量就会少,则等待时长会多,导致效率降低,所以shader编程需要做好协调;
- pixel处理的天然并行
- 分支执行错误则32线程均需要重新来过,所以这里也要求我们尽量少加分支结构;
硬件结构图示如下所示:
3. GPU Pipeline
大家来聊GPU编程时,一般都会提到GPU Pipeline:传统的一条渲染管线是由包括Pixel Shader Unit(像素着色单元)+ ROP(光栅化引擎)+ TMU(纹理贴图单元) 三部分组成的,如下来具体介绍:
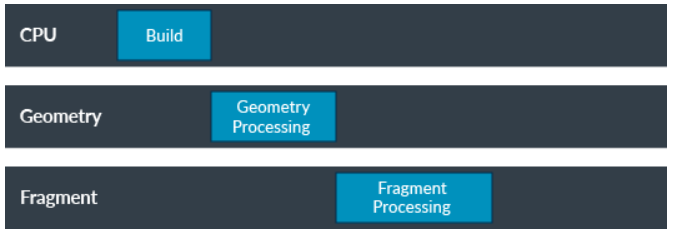
整体划分为三个大的阶段:
-
CPU阶段:
- CPU build后通过图形API 发出drawcall指令,指令会被驱动添加到GPU可以访问的buffer中,即opengl编程常说的context;
- 经过一段时间或者显式调用flush操作后,会将上述指令发送给到GPU,GPU会在相关queue中处理上述指令;
-
GPU 阶段:
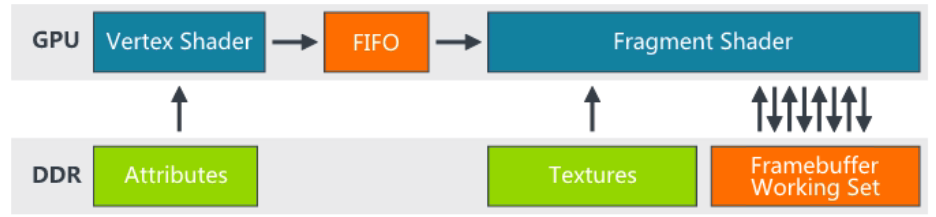
细化处理:
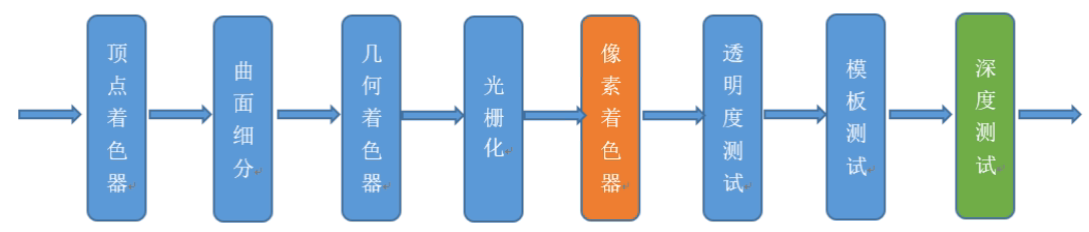
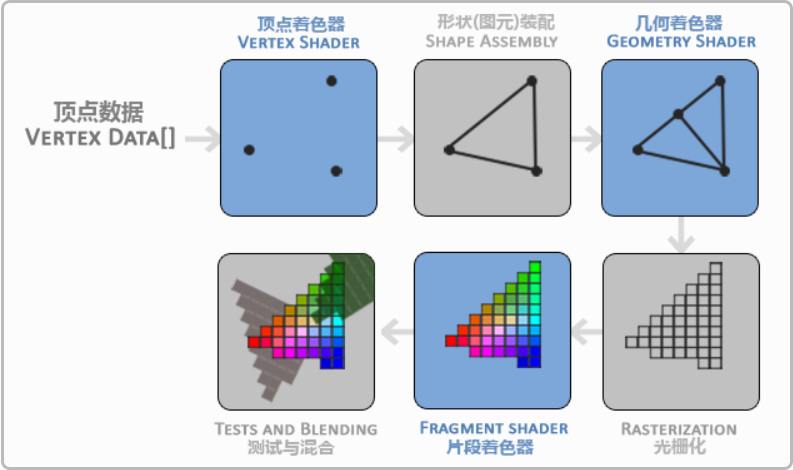
- vertex shader (可编程):顶点操作,取绘制坐标做视角判断后需要绘制的顶点(3D-2D)
- 图元处理:可以简单理解为连线;
- Geometry shader(可编程,非必要):将上述画出来的三角形进行划分;
- 光栅化:按照屏幕分辨率划分为pixel处理;(锯齿产生于此步骤)
- fragment shader(可编程):对每个像素进行颜色计算处理
- 深度、混合、alpha等测试后输出给到framebuffer;
具象化的话如图:
4. 编程性能注意事项
基于上述结构限制,GPU编程应注意如下点:、
-
尽量减少CPU与GPU之间的memory 拷贝动作
- 减少顶点 三角形数量
- 减少渲染状态设置和查询
- 例如:
glGetUniformLocation会从GPU内存查询状态,耗费很多时间周期。 - 避免每帧设置、查询渲染状态,可在初始化时缓存状态。
- 例如:
-
减少Overrender操作
- 尽量使用深度测试剔除无效像素
- 避免Alpha test,alpha blend
- 开启深度测试
- 使用裁剪
- 小物体数量控制
- 尽量使用深度测试剔除无效像素
-
shader优化
- 避免if switch等分支操作
- 避免for循环操作(实测可以提升30%性能)
- 减少纹理采样次数
附录
参考网址:
arm 官网介绍:https://developer.arm.com/solutions/graphics-and-gaming/developer-guides/learn-the-basics
网络总结:https://www.cnblogs.com/timlly/p/11471507.html
CUDA高效编程:https://weread.qq.com/web/reader/e32329e071649d2fe32e06bka87322c014a87ff679a21ea