目录
1.独立性检验
2.卡方拟合性检验
3.自定义卡方检验
4.P值是什么
5.原假设/备择假设
1.独立性检验
“独立性检验”验证从两个变量抽出的配对观察值组是否互相独立(例如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)。
独立性检验主要用于两个或两个以上因素多项分类的计数资料分析,也就是研究两类变量之间的关联性和依存性问题。如果两变量无关联即相互独立,说明对于其中一个变量而言,另一变量多项分类次数上的变化是在无差范围之内;如果两变量有关联即不独立,说明二者之间有交互作用存在。
独立性检验一般采用列联表的形式记录观察数据, 列联表是由两个以上的变量进行交叉分类的频数分布表,是用于提供基本调查结果的最常用形式,可以清楚地表示定类变量之间是否相互关联。又可具体分为:
- 四格表的独立性检验:又称为2*2列联表的卡方检验。四格表资料的独立性检验用于进行两个率或两个构成比的比较,是列联表的一种最简单的形式。
- 行x列表资料的独立性检验:又称为RxC列联表的卡方检验。行x列表资料的独立性检验用于多个率或多个构成比的比较


理论频数表

'''
(1)假设检验重要知识
H0:A与B相互独立 H1:A与B不相互独立
若卡方值大于临界值,拒绝原假设,表示A与B不相互独立,A与B相关
函数中re返回为1表示拒绝原假设,0表示接受原假设
'''
def chi2_independence(alpha, data):chis, p_value, dof, expctd = chi2_contingency(data)if dof == 0:print('自由度应该大于等于1')elif dof == 1:cv = chi2.isf(alpha * 0.5, dof)else:cv = chi2.isf(alpha * 0.5, dof-1)if chis > cv:re = 1 # 表示拒绝原假设else:re = 0 # 表示接受原假设return chis, p_value, dof, re, expctdalpha = 0.05 # 置信度,常用0.01,0.05,用于确定拒绝域的临界值
data = np.array([[178,272],[38,502]])
chis, p_value, dof, re, expctd = chi2_independence(alpha, data)
print('卡方值:',chis)
print('P值:',p_value)
print('自由度:',dof)
print('判读变量:',re)
print('原数据数组同维度的对应理论值:',expctd)卡方值: 150.2623232486362
P值: 1.5192261812214016e-34
自由度: 1
判读变量: 1
原数据数组同维度的对应理论值: [[ 98.18181818 351.81818182][117.81818182 422.18181818]]2.卡方拟合性检验
2.1 定义
卡方检验能检验单个多项分类名义型变量各分类间的实际观测次数与理论次数之间是否一致的问题,这里的观测次数是根据样本数据得多的实计数,理论次数则是根据理论或经验得到的期望次数。这一类检验称为拟合性检验。其自由度通常为分类数减去1,理论次数通常根据某种经验或理论。
总而言之,卡方拟合度检验用于判断不同类型结果的比例分布相对于一个期望分布的拟合程度。
2.2 应用条件
卡方拟合性检验适用于变量为类别型变量的情况。 例如:变量为有罪或无罪。
当每个类别中观察到的或预期的频率太小时,此检验无效。要求样本含量应大于40且每个格子中的理论频数不应小于5
2.3应用实例
随机抽取60名高一学生,问他们文理要不要分科,回答赞成的39人,反对的21人,问对分科的意见是否有显著的差异。

'''
(1)假设检验重要知识
H0:类别A与B的比例没有差异 H1:类别A与B的比例有差异
若卡方值大于临界值,拒绝原假设,表示A与B不相互独立,A与B相关
函数中re返回为1表示拒绝原假设,0表示接受原假设
'''
import numpy as np
from scipy.stats import chisquare
from scipy.stats import chi2
def chi2_fitting(data, alpha, sp=None):chis, p_value = chisquare(data, axis=sp)i, j = data.shape # j为自由度 if j == 0:print('自由度应该大于等于1')elif j == 1:cv = chi2.isf(alpha * 0.5, j)else:cv = chi2.isf(alpha * 0.5, j - 1)if chis > cv:re = 1 # 表示拒绝原假设else:re = 0 # 表示接受原假设return chis, p_value, cv, j-1, re
data = np.array([[39, 21], ])
alpha = 0.05
chis, p_value, cv, dof, re = chi2_fitting(data, alpha)
print('卡方值:',chis)
print('P值:',p_value)
print('拒绝域临界值:',cv)
print('自由度:',dof)
print('判读变量:',re)卡方值: 5.4
P值: 0.02013675155034633
拒绝域临界值: 5.02388618731489
自由度: 1
判读变量: 1显然chis(卡方值)是大于cv(临界值)的,因此拒绝原假设,认为对于文理分科,学生们的态度是有显著的差异的。
从表面上看,拟合性检验和独立性检验不论在列联表的形式上,还是在计算卡方的公式上都是相同的,所以经常被笼统地称为卡方检验。但是两者还是存在差异的。
首先,两种检验抽取样本的方法不同。如果抽样是在各类别中分别进行,依照各类别分别计算其比例,属于拟合优度检验。如果抽样时并未事先分类,抽样后根据研究内容,把入选单位按两类变量进行分类,形成列联表,则是独立性检验。
其次,两种检验假设的内容有所差异。拟合优度检验的原假设通常是假设各类别总体比例等于某个期望概率,而独立性检验中原假设则假设两个变量之间独立。
最后,期望频数的计算不同。拟合优度检验是利用原假设中的期望概率,用观察频数乘以期望概率,直接得到期望频数。独立性检验中两个水平的联合概率是两个单独概率的乘积。

stats.chi2.rvs()
stats.chi2.pdf()
stats.chi2.cdf()
stats.chi2.isf()
1.stats.chi2.rvs()卡方分布直方图
from scipy import stats
import seaborn as sns
import matplotlib.pyplot as plt
samples = stats.chi2.rvs(size=10000, df=1)#产生服从指定分布的随机数,chi2指定了卡方分布
sns.distplot(samples)
plt.title('$\chi^2$,df=1')#自由度为1
plt.show() 
2.stats.chi2.pdf()概率分布密度函数

from scipy import stats
stats.chi2.pdf(2, df=1)#概率密度函数
#上图2对应的位置是0.1037from scipy import stats
stats.chi2.pdf(1, df=1)#概率密度函数
#上图1对应的位置是0.243.stats.chi2.cdf()随机变量的累积分布函数,它是概率密度函数的积分(也就是x时p(X<x)的概率)。产生对应x的这种分布的累积分布函数的值。

from scipy import stats
stats.chi2.cdf(1, df=1)
from scipy import stats
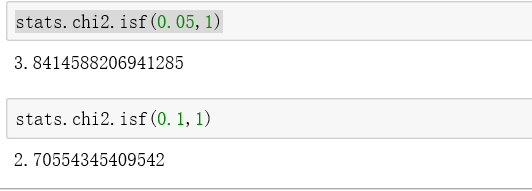
stats.chi2.cdf(6, df=1)4.stats.chi2.isf(),对应上表图的值,置信度,自由度

3.自定义卡方检验
原假设:“青少年行为”与“家庭状况”独立。
备择假设:“青少年行为”与“家庭状况”不独立。
from scipy import stats
import numpy as np
from scipy.stats import chi2_contingency
def custom_chi2_contingency(observed):# 每一行求和row = observed.sum(axis=1)# 每一列求和col = observed.sum(axis=0)# 总数求和all_sum = observed.sum()# meshgrid 生成网格x1, x2 = np.meshgrid(col, row)# 期望频数expected_count = x1 * x2 / all_sum# 统计量,即卡方值chi2 = ((observed - expected_count)**2 / expected_count).sum()# 自由度df = (len(row) - 1) * (len(col) - 1)# 计算 p 值,这里用到了卡方分布的概率积累函数,# 因为这个 cdf 是计算从左边到这点的累计积分,因此用 1 减它p = 1 - stats.chi2.cdf(chi2, df=df)return chi2, p, df, expected_count
obs = np.array([[178, 272], [38, 502]])
result1 = custom_chi2_contingency(obs)
result2 = chi2_contingency(obs)
print('自定义卡方检验的函数返回:')
print(result1,'\n')
print('scipy 提供的卡方检验返回:')
print(result2)自定义卡方检验的函数返回: (152.16271892047084, 0.0, 1,
array([[ 98.18181818, 351.81818182], [117.81818182, 422.18181818]]))
scipy 提供的卡方检验返回: (150.2623232486362, 1.5192261812214016e-34, 1,
array([[ 98.18181818, 351.81818182], [117.81818182, 422.18181818]]))
4.P值是什么
得到“检验统计量”有个缺点,就是它是一个很“死”的数字,我们看到 152,我们只能直观感觉它很大,因为如果观察频数与理论频数大约相等,这个值应该很小,但不能量化这个值有多大。这只是统计量服从某个自由度的卡方分布的情况。
那么问题来了,如果统计量服从其它分布呢?统计量这个干巴巴的数字,你怎么知道这个这个分布取到这个统计量的概率有多大?因此还差一步,我们还必须查表。所以得到P值的过程就是帮你查表了,P值是一个概率值,它介于0 和1之间,P值是当前分布取到这个统计量的概率到当前分布极端值(指的是概率很小的极端值)这个区间的累计概率之和,即取到这个值,到比这个值更“差”的概率之和,如果P 值很大,说明统计量取当前值的概率在一个正常的范围(一般是认为设定成95%),如果P 值很小,说明这个统计量取当前值的概率也非常小。
特别说明:对于连续型随机变量来说,取到某个值的概率其实是0,因此上面才用到了对于区间取概率之和。


1.统计量=2时,累计概率之和较小0.103,也就是p值小,0.103这个概率也小,此时不合理,应拒绝原假设,接受备择假设
2.统计量=1时,这一点到极端值累计之和0.317比较大,也就是p值大,0.24这个概率取值也大,合理
p值作用:小于显著性水平,拒绝原假设,否则不能拒接原假设,小拒大接
上面所说的累积概率之和如果很小,小于一个临界值,这个临界值我们称之为“显著性水平”,用 表示,一般取α=0.05 。多说一句,这个显著性水平其实是我们在原假设成立的情况下,拒绝原假设的概率,即犯第一类错误的概率.
1-α 为置信度或置信水平,其表明了区间估计的可靠性
我们认为,在
分布,如果一个点到右边无穷的累计积分小于“显著性水平”,我们就认为这个点以及右边所有的点的取值,都是小概率事件。
1、P值统一了假设检验的比较标准,把计算统计量的概率大小统一变成计算P值,如果这个P值小于一个预先设定好的很小的数,则拒绝原假设,如果P值大于这个预先设置好的很小的数,则说明没有充分证据拒绝原假设;
2、使用P值进行假设检验的时候,会更便利。因此,使用P值进行假设检验的评判标准就只要一个,就是记住这句话“小拒大接”,即比0.05小,就拒绝“原假设”,比 0.05大,结论是“没有理由拒绝原假设”。P>0.05 碰巧出现的可能性大于5% ,不能否定无效假设,两组差别无显著意义
P<0.05 碰巧出现的可能性小于5% ,可以否定无效假设,两组差别有显著意义
P<0.01 碰巧出现的可能性小于1% ,可以否定无效假设,两者差别有非常显著意义
5.原假设/备择假设
5.1独立性检验-青少年行为家庭状况关系-两类变量之间的关联性和依存性问题
原假设:“青少年行为”与“家庭状况”独立。
备择假设:“青少年行为”与“家庭状况”不独立
备择假设通常是研究者想收集证据予以支持的假设;原假设是研究者想收集证据予以推翻的假设。
我们把倾向于要证明的结论设置为“备择假设”,而推理是基于“原假设”成立进行的,推理得出矛盾,说明“原假设”错误,从错误的起点推出了错误的结论,因此“原假设”不成立,这就是假设检验里面说的“拒绝原假设”。
卡方检验的“原假设”一定是假设独立,“备择假设”一定是假设相关
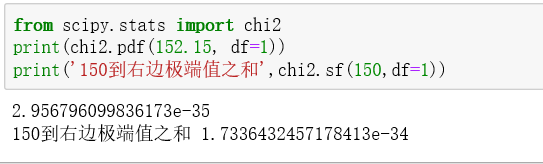
卡方=152.15,在直方图几乎看不到,说明概率很低
概率 = 2.956796099836173e-35,几乎为0,说明在我们的假设【“青少年行为”与“家庭状况”独立】下,得到这组观测数据的概率很低很低,但它却发生了,就证明了我们的“原假设”是不正确的,即有充分证据决绝“原假设”。接受备择假设认为:“青少年行为”与“家庭状况”不独立。
5.2拟合优性检验-硬币-实际观测次数与理论次数之间是否一致

原假设:硬币均衡
备择假设:硬币不均衡
如果你想通过种种论证,证明一件事情,就要把这件事情写成“备择假设”。备择假设通常用于表达研究者自己倾向于支持的看法(这很主观),然后就是想办法收集证据拒绝原假设,以支持备择假设。一般不说接受原假设而说没有理由拒绝原假设
想要证明硬币是不均衡的,推理是基于原假设正反次数都是25次进行的,推理得到0.72<3.8,拒绝原假设,接受备择假设,硬币不均衡
参考资料
https://www.cnblogs.com/Yuanjing-Liu/articles/9252844.html
https://www.jianshu.com/p/154673042ba5