最近在学习牛腩新闻发布系统,正如牛老师所说,作为一个优秀的.NET开发人员,对SQL语句不熟怎么能行呢,接下来就总结下牛老师写的存储过程中SQL语句,挺经典,举一反三
首先先展示出来适用于系统的三张表
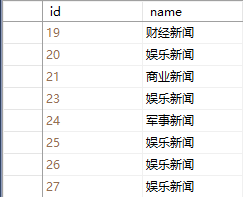
- 新闻类别表(category)
- 新闻表(news)

- 新闻评论表(comment)
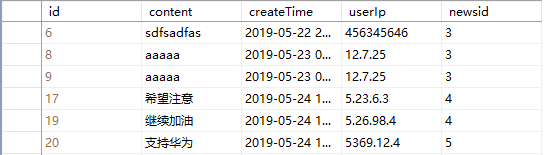
其中caId是类别表的外键,newsid是news的外键
接下来正式进入基于这张表的查询总结
as关键字
按照取出评论回复最多的10条评论为例,看SQL语句
//取出评论最多的10条新闻select top 10 n.id,n.title,n.createTime,c.name,count(com.id) as comCount--count(com.id)起一个别名用asfrom news n inner join category c on n.caId=c.id --内连接 取出新闻表中类别id与类别表id相等的内容inner join comment com on com.newsid = n.id --内连接 取出评论表中新闻表id与新闻表id相等的内容group by n.id,n.title,n.createTime,c.name --按照id,标题,时间,类别名字order by comCount desc --按照评论多少进行降序执行结果如下图、
先不管连接的代码,由这句代码
count(com.id) as comCount可以看出来as的作用是为字段起一个别名
当然如果觉得表头是英文看起来不太方便,也可以转换成中文,这也是as在起作用,如下代码
select top 10 n.id as '新闻ID',n.title as '新闻标题',n.createTime as '创建时间',c.name as '新闻类别',count(com.id) as comCountfrom news n inner join category c on n.caId=c.id --内连接 取出新闻表中类别id与类别表id相等的内容inner join comment com on com.newsid = n.id --内连接 取出评论表中新闻表id与新闻表id相等的内容group by n.id,n.title,n.createTime,c.name --按照id,标题,时间,类别名字order by comCount desc --按照评论多少进行降序执行结果如下

推荐博客1
推荐博客2
内联
还是以面的代码为例
select top 10 n.id,n.title,n.createTime,c.name,count(com.id) as comCount--count(com.id)起一个别名用asfrom news n inner join category c on n.caId=c.id --内连接 取出新闻表中类别id与类别表id相等的内容用通俗的语言描述下
从news表 内连接 category表 条件是 news表的caId和category表id相等 的内容中得到top 10
推荐左右内连接博客,相当清楚
Like+通配符%
where子句中like+通配符%可实现模糊查询
换个例子
现在取出标题含有“王”的记录,代码如下
select top 10 n.id,n.title,n.createTime from news nwhere n.title like '%王%' --通配符,搜索包含用户传入参数的标题order by n.createTime desc现在取出标题中以“王”为开头记录,代码如下
select top 10 n.id,n.title,n.createTime from news nwhere n.title like '王%' --通配符,搜索包含用户传入参数的标题order by n.createTime desc现在取出标题中以“王”为结尾的记录,代码如下
select top 10 n.id,n.title,n.createTime from news nwhere n.title like '%王' --通配符,搜索包含用户传入参数的标题order by n.createTime desc%为缺省字符,简单来说就是可以代替剩下一切字符
in关键字
下面在类别表中取出id为19,20,21的记录,代码如下
select * from category where id in(19,20,21)查询结果

使用in关键字可以查询出一个字段对应多个值的记录