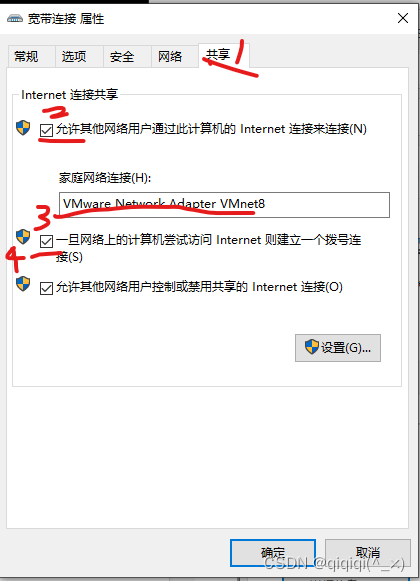
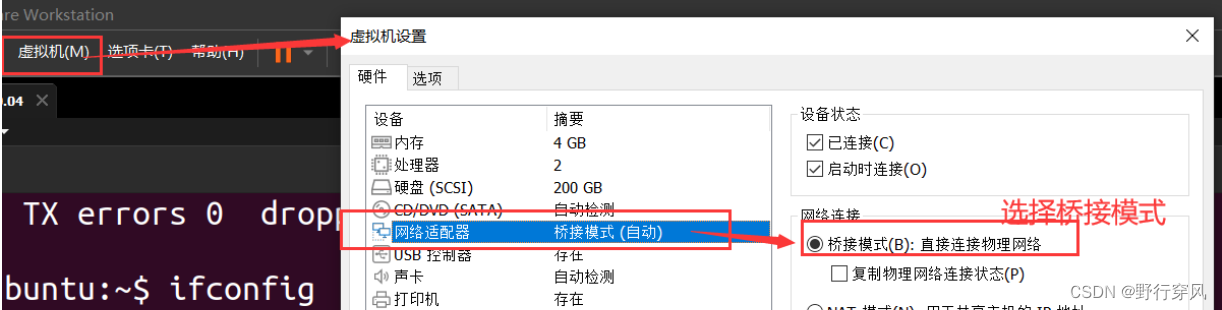
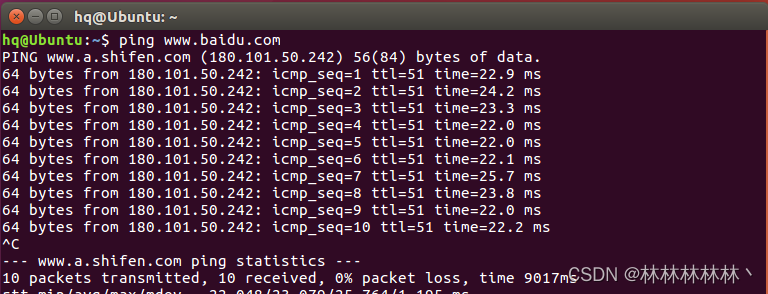
众所周知,深度学习现阶段还是以数据为驱动,然后我们需要simsiam等的自监督算法来自动标注数据集以及特征,但是初始阶段还是回到我们的音频数据本身。
我们提取音频特征有数种方式,首先是可以直接进行音频波形的提取:
import librosa
# wav就是所说的音频波形,sr是音频文件的采样率
wav,sr=librosa.load('xxx.wav')# 还有另外一个包就是torchaudioimport torchaudio
# 这里提取出来的wav数据本身就是tensor格式
wav,sr=torchaudio.load('xxx.wav')# ps:torchaudio如果安装不了的话,自己在conda弄个新的环境,
# 用离线的形式安装torch和torchvision还有torchaudio
然后是梅尔频谱之类的东西的提取,不多说,学习资料大把,也是这两个库。
废话不多说,下面上代码。
import os
import numpy as np
import torch
import torchaudio
import librosa
import librosa.display
from matplotlib import pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchaudio.transforms import MelSpectrogram, AmplitudeToDBdef vision(mel_spectrogram):plt.figure(figsize=(10, 4)) # 创建一个画布librosa.display.specshow(librosa.power_to_db(mel_spectrogram[0], ref=np.max), y_axis="mel",x_axis="time") # 绘制mel图谱plt.colorbar(format="%+2.0f dB") # 添加颜色条plt.title("Mel Spectrogram") # 添加标题plt.tight_layout() # 调整布局plt.show() # 显示图片def pad_3d(x, seglen, mode='wrap'):# 这个函数将一个三维数组x [80, 80, L] 补零到指定长度seglen# 如果x的第三个维度小于seglen,则在该维度上补零# 如果x的第三个维度等于seglen,则不变# 如果x的第三个维度大于seglen,则切掉多余的部分pad_len = seglen - x.shape[2]if pad_len > 0:y = np.pad(x, ((0, 0), (0, 0), (0, pad_len)), mode=mode)elif pad_len == 0:y = xelse:r = np.random.randint(-pad_len) # r : [0- (-pad_len)]y = x[:, :, r:r + seglen]if torch.is_tensor(y):y = yelse:y = torch.tensor(y)return yclass WavDataset(Dataset):def __init__(self, root_dir):self.root_dir = root_dir# self.transform = Noneself.wav_files = []self.labels = []for folder in os.listdir(root_dir):folder_path = os.path.join(root_dir, folder)if os.path.isdir(folder_path):for file in os.listdir(folder_path):if file.endswith(".wav"):file_path = os.path.join(folder_path, file)self.wav_files.append(file_path)self.labels.append(folder)def __len__(self):return len(self.wav_files)def __getitem__(self, idx):wav_file = self.wav_files[idx]label = self.labels[idx]waveform, sample_rate = torchaudio.load(wav_file)# waveform = torch.index_select(waveform, dim=0, index=torch.tensor([0]))mel_spectrogram = MelSpectrogram(sample_rate, n_fft=2048, n_mels=200,hop_length=512)(waveform)# vision(mel_spectrogram) # 可视化操作mel_spectrogram = AmplitudeToDB()(mel_spectrogram)# 长度保持一致mel_spectrogram = pad_3d(mel_spectrogram, seglen=176)# print(mel_spectrogram.shape)# 进行双声道的转换if mel_spectrogram.shape[0] != 2:# print(mel_spectrogram.shape[0])mel_spectrogram = torch.cat((mel_spectrogram, mel_spectrogram), dim=0)# print(mel_spectrogram.shape) # 进行数据类型的查看# print(type(mel_spectrogram))# print(torch.is_tensor(mel_spectrogram))# if self.transform is not None:# mel_spectrogram = self.transform(mel_spectrogram)# print(mel_spectrogram.shape)label = int(label)label = torch.tensor(label)return mel_spectrogram, labelif __name__ == '__main__':dataset = WavDataset('2s_wav_mini')print(dataset[0])# n = 0# for l, data in enumerate(dataset):# if data[0].shape[0] != 2:# n += 1# print('第几个:', l, 'size:', data[0].shape[0], 'total:', n)dataset = DataLoader(dataset)
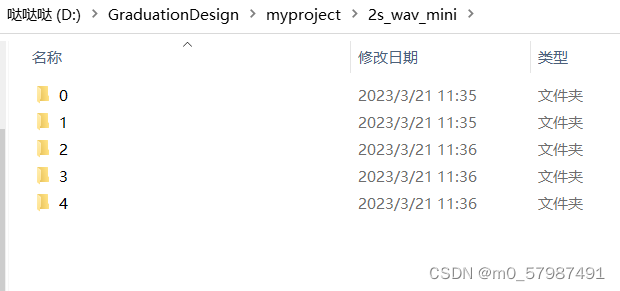
注:文件的存储方式如图所示,里面每个0-4文件夹下都是wav格式的文件,更复杂的数据存储结构请另请高明,如果你的数据后缀是ogg之类的请更改代码
if file.endswith(".wav")改为if file.endswith(".ogg"):、
最后强调一下,如果你的数据集本身也就是几分类,效果还是非常差(类似四五分类,但是准确率也就70以下),请先质疑自己数据的问题,而不是质疑模型的问题。比如说,我们进行语音数据是可以通过conv1d或者conv2d直接进入卷积网络的,但是你的数据格式要对。并且,提取mfcc或者其他频谱图也并非是真正将图片保存出来,自己想看看是什么样的就做个可视化。因为语音信号是一种时间序列,而图片是一种“空间序列”。
并且,我的数据集文件音频格式也就是2s一个的,如果自定义数据长度请更改pad_3d的seglen参数,至于为什么pad_3d这个东西这么抽象,用numpy的方式处理tensor数据之后再改回来?那只能说我也是用别人的。还有,请将你的数据集的名称改成0-n的格式
鸟声数据:20种鸟类,14311条自然音频,智源研究院联合百鸟数据发布大型鸟鸣数据集Birdsdata
**链接:https://pan.baidu.com/s/1M-3AQhle_TigrbjjT-z0pw (提取码:61g6)