Email:ht0909@mail.ustc.edu.cn
原创内容,转载请标明
-
数据集
1.清华大学THCHS30中文语音数据集
data_thchs30.tgz http://cn-mirror.openslr.org/resources/18/data_thchs30.tgz
test-noise.tgz http://cn-mirror.openslr.org/resources/18/test-noise.tgz
resource.tgz http://cn-mirror.openslr.org/resources/18/resource.tgz
2.Free ST Chinese Mandarin Corpus
ST-CMDS-20170001_1-OS.tar.gz http://cn-mirror.openslr.org/resources/38/ST-CMDS-20170001_1-OS.tar.gz
-
数据格式
语音数据文件
数据集wav格式 diff文件头 采样频率16 kHz, 采样位数16 bits, 256 samples, 2 bytes 长度
1.data_thchs30数据集:
训练集10000条语音,验证集893,测试集2495
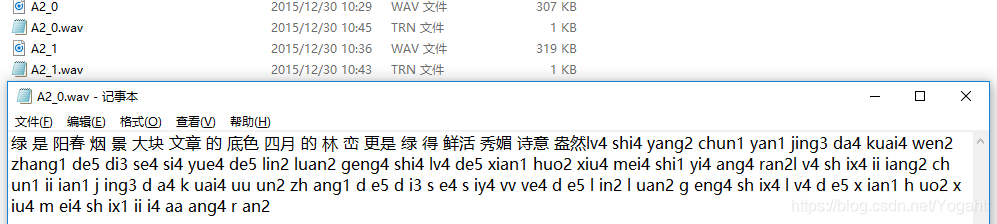
2. st-cmds数据集:
训练集100000条语音,验证集600条,测试集2000条。
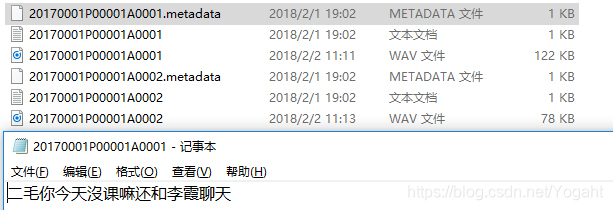
标签数据文件
参照datalist/目录下文件
1.st-cmds标签数据文件:
train.wav 语音数据路径

train.syllable 语音标签数据

2.thch30类似
-
数据预处理
1.get_wav_list #得到输入语音的路径,读入语音数据路径txt
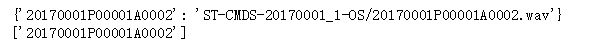
def get_wav_list(filename):'''读取一个wav文件列表,返回一个存储该列表的字典类型值ps:在数据中专门有几个文件用于存放用于训练、验证和测试的wav文件列表'''txt_obj=open(filename,'r') # 打开文件并读入txt_text=txt_obj.read()txt_lines=txt_text.split('\n') # 文本分割dic_filelist={} # 初始化字典list_wavmark=[] # 初始化wav列表for i in txt_lines:if(i!=''):txt_l=i.split(' ') dic_filelist[txt_l[0]] = txt_l[1]list_wavmark.append(txt_l[0])txt_obj.close()return dic_filelist,list_wavmark2.get_wav_symbol

def get_wav_symbol(filename):'''读取指定数据集中,所有wav文件对应的语音符号返回一个存储符号集的字典类型值'''txt_obj=open(filename,'r') # 打开文件并读入txt_text=txt_obj.read()txt_lines=txt_text.split('\n') # 文本分割dic_symbol_list={} # 初始化字典list_symbolmark=[] # 初始化symbol列表for i in txt_lines:if(i!=''):txt_l=i.split(' ')dic_symbol_list[txt_l[0]]=txt_l[1:]list_symbolmark.append(txt_l[0])txt_obj.close()return dic_symbol_list,list_symbolmark3.read_wav_ data #读取一个wav文件,返回声音信号的时域谱矩阵和播放时间
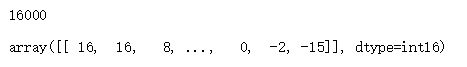
def read_wav_data(filename):'''读取一个wav文件,返回声音信号的时域谱矩阵和播放时间'''wav = wave.open(filename,"rb") # 打开一个wav格式的声音文件流num_frame = wav.getnframes() # 获取帧数num_channel=wav.getnchannels() # 获取声道数framerate=wav.getframerate() # 获取帧速率num_sample_width=wav.getsampwidth() # 获取实例的比特宽度,即每一帧的字节数str_data = wav.readframes(num_frame) # 读取全部的帧wav.close() # 关闭流wave_data = np.fromstring(str_data, dtype = np.short) # 将声音文件数据转换为数组矩阵形式wave_data.shape = -1, num_channel # 按照声道数将数组整形,单声道时候是一列数组,双声道时候是两列的矩阵wave_data = wave_data.T # 将矩阵转置#wave_data = wave_data return wave_data, framerate 4. GetFrequencyFeature #wav波形 加时间窗以及时移10ms 返回输入数据
def GetFrequencyFeature3(wavsignal, fs):# wav波形 加时间窗以及时移10mstime_window = 25 # 单位mswindow_length = fs / 1000 * time_window # 计算窗长度的公式,目前全部为400固定值wav_arr = np.array(wavsignal)#wav_length = len(wavsignal[0])wav_length = wav_arr.shape[1]range0_end = int(len(wavsignal[0])/fs*1000 - time_window) // 10 # 计算循环终止的位置,也就是最终生成的窗数data_input = np.zeros((range0_end, 200), dtype = np.float) # 用于存放最终的频率特征数据data_line = np.zeros((1, 400), dtype = np.float)for i in range(0, range0_end):p_start = i * 160p_end = p_start + 400data_line = wav_arr[0, p_start:p_end]x=np.linspace(0, 400 - 1, 400, dtype = np.int64)w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) # 汉明窗data_line = data_line * w # 加窗data_line = np.abs(fft(data_line)) / wav_lengthdata_input[i]=data_line[0:200] # 设置为400除以2的值(即200)是取一半数据,因为是对称的#print(data_input.shape)data_input = np.log(data_input + 1)return data_input
对语音输入信号加汉明窗后做傅里叶变化处理,得到模型输入。
5.GetData #读取数据,返回神经网络输入值和输出值矩阵(可直接用于神经网络训练的那种)
def GetData(self,n_start,n_amount=1):'''读取数据,返回神经网络输入值和输出值矩阵(可直接用于神经网络训练的那种)参数:n_start:从编号为n_start数据开始选取数据n_amount:选取的数据数量,默认为1,即一次一个wav文件返回:三个包含wav特征矩阵的神经网络输入值,和一个标定的类别矩阵神经网络输出值'''#当为test or valid 时随机选择thchs30或者st-cmd数据集中的语音数据bili = 2#当为train时,由于st-cmd数据是thchs30数据的10倍,因此设置bili=11使得两个数据集的数据分布相同。if(self.type=='train'): bili = 11# 读取一个文件if(n_start % bili == 0):filename = self.dic_wavlist_thchs30[self.list_wavnum_thchs30[n_start // bili]]list_symbol=self.dic_symbollist_thchs30[self.list_symbolnum_thchs30[n_start // bili]]else:n = n_start // bili * (bili - 1)yushu = n_start % bililength=len(self.list_wavnum_stcmds)filename = self.dic_wavlist_stcmds[self.list_wavnum_stcmds[(n + yushu - 1)%length]]list_symbol=self.dic_symbollist_stcmds[self.list_symbolnum_stcmds[(n + yushu - 1)%length]]if('Windows' == plat.system()):filename = filename.replace('/','\\') # windows系统下需要执行这一行,对文件路径做特别处理wavsignal,fs=read_wav_data(self.datapath + filename)# 获取输出特征feat_out=[]print("数据编号",n_start,filename)for i in list_symbol:if(''!=i):n=self.SymbolToNum(i)#v=self.NumToVector(n)#feat_out.append(v)feat_out.append(n)print('feat_out:',feat_out)# 获取输入特征data_input = GetFrequencyFeature3(wavsignal,fs)#data_input = np.array(data_input)data_input = data_input.reshape(data_input.shape[0],data_input.shape[1],1)#arr_zero = np.zeros((1, 39), dtype=np.int16) #一个全是0的行向量#while(len(data_input)<1600): #长度不够时补全到1600# data_input = np.row_stack((data_input,arr_zero))#data_input = data_input.Tdata_label = np.array(feat_out)return data_input, data_label
返回该条语音的语音特征和标签特征向量,如图为语音特征维度和标签特征向量。