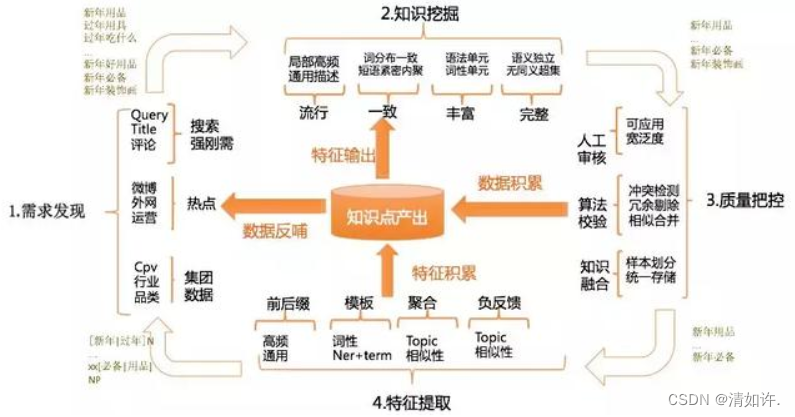
学习内容
搜集各种博客,理解实体识别、关系分类、关系抽取、实体链指、知识推理等,并且总结各种分类中最常用的方法、思路。
由于自己刚刚接触知识图谱,对该领域的概念和方法的描述还不是很清楚,所以只是简单的列出框架和添加链接,之后会进行补充。
1. 实体识别
原文地址:链接
介绍相关概念的: 链接
1.1 方法概述
早期的命名实体识别方法大都是基于规则的,系统的实现代价较高;
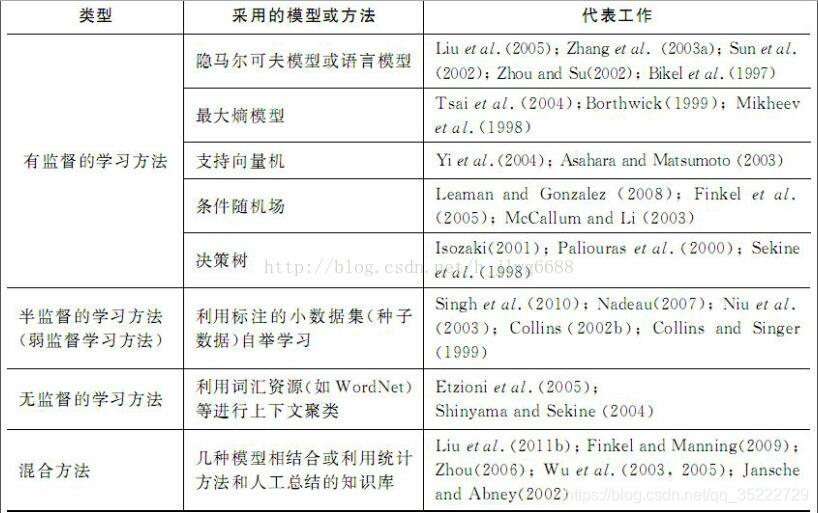
但是进入21世纪后,基于大规模语料库的统计方法逐渐成为自然语言处理的主流,一大批机器学习方法被成功地应用于自然语言处理的各个方面。根据使用的机器学习方法的不同,我们可以粗略地将基于机器学习的命名实体识别方法划分为如下四种:有监督的学习方法、半监督的学习方法、无监督的学习方法、混合方法。
1.2 命名实体识别方法
1.2.1 基于CRF的命名实体识别方法
CRF:条件随机场; 也是最成功的命名实体识别方法,受到工业界的广泛使用。
基于CRF的命名实体识别与前面介绍的基于字的汉语分词原理一样,就是把命名实体识别过程看作一个序列标注问题。 基本思路是:将给定的文本首先进行分词处理,然后对人名、简单地名和简单的组织机构名进行识别,最后识别复合地名和复合组织机构名。
1.2.2 基于多特征的命名实体识别方法
在命名实体识别中,无论采用哪一种方法,都是试图充分发现和利用实体所在的上下文特征和实体的内部特征,只不过特征的颗粒度有大(词性和角色级特征)有小(词形特征)的问题。考虑到大颗粒度特征和小颗粒度特征有互相补充的作用,应该兼顾使用的问题,提出了基于多特征相融合的汉语命名实体识别方法,该方法是在分词和词性标注的基础上进一步进行命名实体的识别,由词形上下文模型、词性上下文模型、词形实体模型和词性实体模型4个子模型组成的。其中,词形上下文模型估计在给定词形上下文语境中产生实体的概率;词性上下文模型估计在给定词性上下文语境中产生实体的概率;词形实体模型估计在给定实体类型的情况下词形串作为实体的概率;词性实体模型估计在给定实体类型的情况下词性串作为实体的概率。
2.关系分类
原文地址: 链接
2.1 简介
给定一段自然语言文本以及该文本中出现的若干实体( e 1 . . . e n e_{1}...e_{n} e1...en),关系分类(relation classification)任务的目的是识别这些实体( e 1 . . . e n e_{1}...e_{n} e1...en)之间满足的语义关系(关系分类也叫做关系抽取、关系识别等)。由于全部可能的关系集合通常是预先指定好的(例如知识图谱中的全部谓词(边上的标注/关系)),因此该任务可以采用分类方法完成。最基本的关系分类任务是判断文本中同时出现的两个实体( e 1 , e n e_{1},e_{n} e1,en)之间的关系。
2012年,Google对外发布了基于知识图谱(free base)的语义搜索和智能问答服务,并开放了该知识图谱供工业界和学术界使用。大规模知识图谱的出现极大地推动了智能问答研究的发展。基于此类知识图谱,斯坦福、Facebook 和微软等研究机构分别构建并开放了基于知识图谱的智能问答评测数据集,包括WebQuestions、SimpleQuestions、NLPCC-KBQA等,这些数据集涉及的问答任务需要问答系统能够针对输人问题进行准确的关系分类。由于知识图谱中包含的关系(即谓词)数目远超上述关系分类任务涉及的关系数目,因此近年来出现了很多新型的关系分类方法。主要包括模板匹配方法、监督学习方法和半监督学习方法。
2.2 方法
2.2.1 模板匹配方法
模板匹配方法是关系分类任务中最常见的方法。该类方法使用一个模板库对输入文本中两个给定实体进行上下文匹配,如果该上下文片段与模板库中某个模板匹配成功,那么可以将该匹配模板对应的关系作为这两个实体之间满足的关系。
两种常用的模板匹配方法: 第一种方法是基于人工模板完成关系分类任务,第二种方法是基于统计模板完成关系分类任务
基于人工模板的关系分类主要用于判断实体间是否存在上下位关系(Hyponymy).
基于人工模板的关系分类在给定关系列表的基础上,从大规模数据中自动抽取和总结模板,并将抽取出来的高质量模板用于关系分类任务。该过程无需过多人工干预
2.2.2 监督学习方法
监督学习(supervised learning)方法使用带有关系标注的数据训练分析分类模型。本节把该类方法分为三类进行介绍:基于特征的方法、基于核函数的方法和基于深度学习的方法。
2.2.3 半监督学习方法
基于自举的方法和基于远监督的方法。
3.实体链指
原文地址:链接
3.1简介
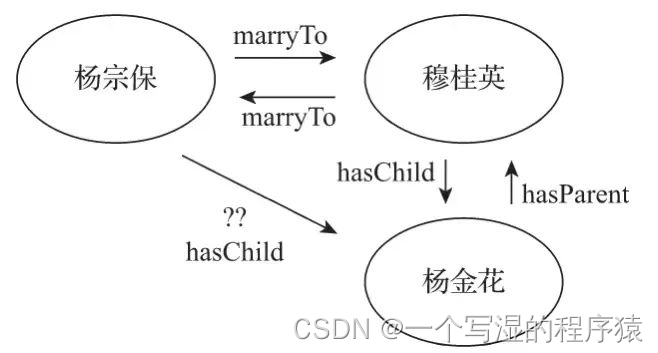
实体链接,就是把文本中的mention链接到KG里的entity的任务。如下图所示[1]:
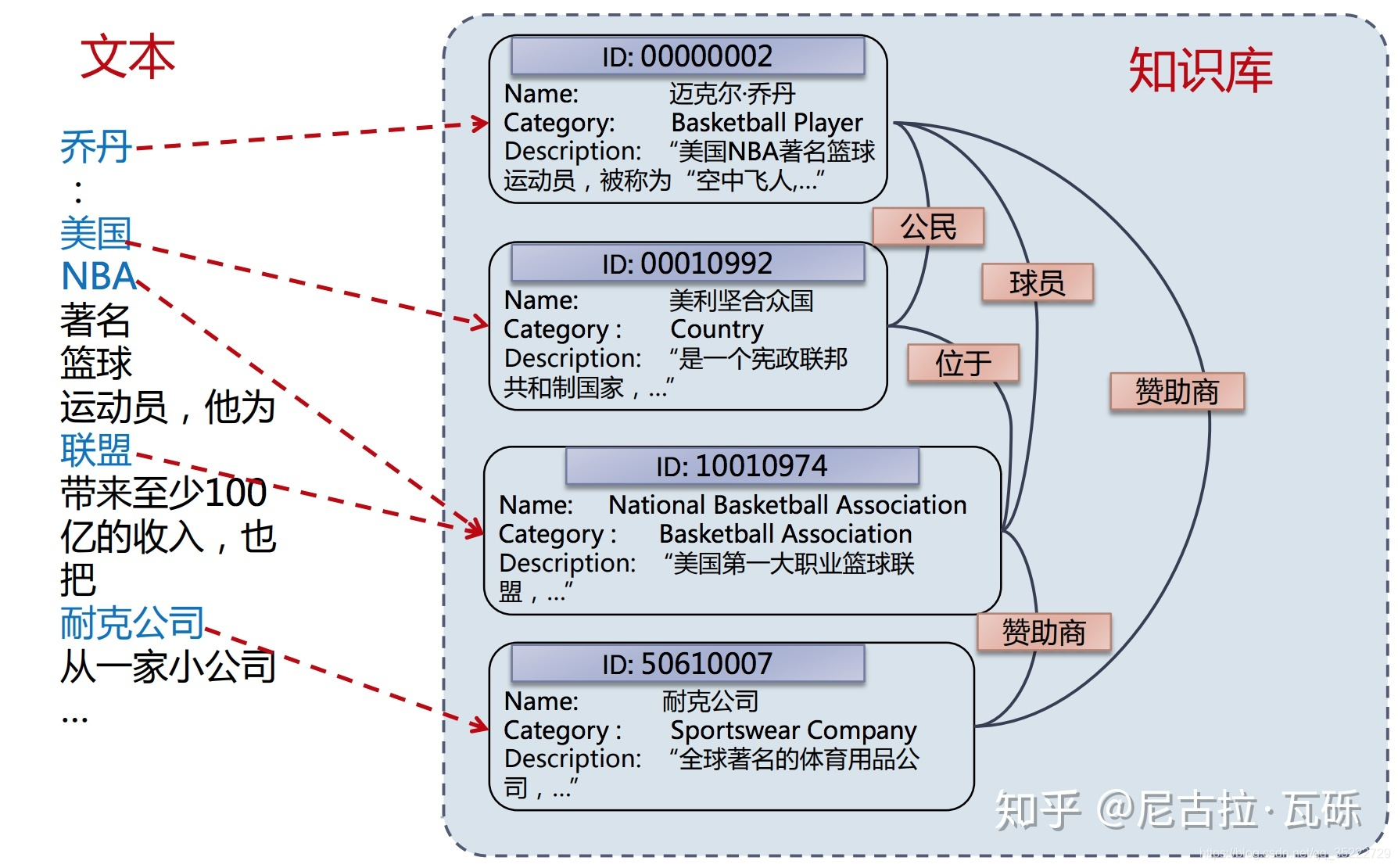
- Knowledge Graph (知识图谱):一种语义网络,旨在描述客观世界的概念实体及其之间的关系,有时也称为Knowledge Base (知识库)。
- 图谱由三元组构成:<实体1,关系,实体2> 或者 <实体,属性,属性值>;
例如:<姚明,plays-in,NBA>、<姚明,身高,2.29m>;
常见的KB有:Wikidata、DBpedia、YAGO。 - Entity (实体):实体是知识图谱的基本单元,也是文本中承载信息的重要语言单位。
- Mention (提及):自然文本中表达实体的语言片段。
回过头再看,上面的这个图中,“乔丹”、“美国”、“NBA”这些蓝色的片段都是mention,其箭头所指的“块块”就是它们在图谱里对应的entity。
3.2 方法
- End-to-End:先从文本中提取到实体mention (即NER),对应到候选实体,然后将提取到的entities消除歧义,映射到给定的KB中。
- Linking-Only:与第一种方法对比,跳过了第一步。该方法直接将text和mention作为输入,找到候选实体并消除歧义,映射到给定的KB中。
由于端到端的工作比较少,且NER也没太多可讲的。Linking-Only的相关技术方向和工作现在比较火。
3.3 难点以及对应的解决方法
EL的工作非常有挑战性,主要有两个原因:
- Mention Variations:同一实体有不同的mention。(<科比>:小飞侠、黑曼巴、科铁、蜗壳、老科。)
- Entity Ambiguity:同一mention对应不同的实体。(“苹果”:中关村苹果不错;山西苹果不错。)
针对上述两个问题,一般会用Candidate Entity Generation (CEG) 和Entity Disambiguation (ED) 两个模块[2]来分别解决:
- Candidate Entity Generation:从mention出发,找到KB中所有可能的实体,组成候选实体集 (candidate entities);
- Entity Disambiguation:从candidate entities中,选择最可能的实体作为预测实体。
其中,CEG的方法都比较朴素,没什么可讲的,笔者会把重点放在ED上。
详细请看原文
4. 关系抽取
原文地址:链接
4.1 简介
信息抽取旨在从大规模非结构或半结构的自然语言文本中抽取结构化信息。关系抽取是其中的重要子任务之一,主要目的是从文本中识别实体并抽取实体之间的语义关系。比如:
International Business Machines Corporation (IBM or the company) was
incorporated in the State of New York on June 16, 1911.
我们可以从上面这段文本中抽取出如下三元组(triples)关系:
- Founding-year (IBM, 1911)
- Founding-location (IBM, New York)
为什么要进行关系抽取?
创建新的结构化知识库(knowledge base)并且增强现有知识库
构建垂直领域知识图谱:医疗,化工,农业,教育等
支持上层应用:问答,搜索,推理等。比如,对于这样一个提问:
The granddaughter of which actor starred in the movie “E.T.”?
可以用如下的关系推理表示:
(acted-in ?x "E.T.") && (is-a ?y actor) && (granddaughter-of ?x ?y)
4.2 方法
基于规则的模式匹配(Using Hand-built Patterns)
基于监督学习的方法(Supervised Method)
我们可以把关系抽取当成一个多分类问题,每一种关系都是一个类别,通过对标签数据的学习训练出一个分类器(classifier)即可。主要难点有两个:特征的构建和标签数据的获取
半监督和无监督学习方法(Semi-supervised && unsupervised)
基于种子的启发式算法(Seed-based or bootstrapping approach)
远程监督学习(Distant Supervision)
5. 知识推理
原文地址:链接
5.1 简介
OWL本体语言是知识图谱中最规范(W3C制定)、最严谨(采用描述逻辑)。表达能力最强的语言(是一阶谓词逻辑的子集),它基于RDF语法,使表示出来的文档具有语义理解的结构基础。促进了统一词汇表的使用,定义了丰富的语义词汇。同时允许逻辑推理
所谓推理就是通过各种方法获取新的知识或者结论,这些知识和结论满足语义。其具体任务可分为可满足性(satisfiability)、分类(classification)、实例化(materialization)。
可满足性可体现在本体上或概念上,在本体上即本体可满足性是检查一个本体是否可满足,即检查该本体是否有模型。如果本体不满足,说明存在不一致。概念可满足性即检查某一概念的可满足性,即检查是否具有模型,使得针对该概念的解释不是空集。
分类,针对Tbox的推理,计算新的概念包含关系
实例化即计算属于某个概念或关系的所有实例的集合
5.2 方法
基于Tableaux运算
基于一阶查询重写的方法
基于产生式规则的方法