前言
首先在这里要解释一下,为什么将顺序表这一种数据结构分为多篇文章去编写。首先我的笔记是根据王道老师的计算机考研——数据结构的视频课程去学习的。其次,我觉得将一种数据结构的知识放在一篇文章中,文章会显得过于冗长,容易打击学习的积极性和自信心。考虑到以上这些点,特此将文章分开上传。方便大家可以根据王道老师的视频课进行配套观看。并且我会将有联系的几篇文章分别在开头和结尾附上链接(传送门)方便大家去跳转和阅读,也是我觉得既保持了知识的连贯性,又尽量的保证了不打击大家的学习积极性!
以上的废话有点多我们赶紧进入主题,在经过上一篇文章(顺序表的插入和删除)的学习后,我们紧接着学习顺序表的基本操作——查找。
顺序表的按位查找
含义
就是通过提供的位置查找到指定位置上元素的值。比如:我想要找到第i位数据元素,那么可以直接找到第i位的数据元素的值。
静态分配实现
如果是通过静态分配的方式实现的顺序表,其实对于按位查找的实现就很简单:
#define MaxSize 10 // 定义最大长度typedef struct{ElemType data[MaxSize]; // 用静态的“数组”存放数据元素int length; // 顺序表的当前长度
}SqList; // 顺序表的类型定义(静态分配方式)ElemType GetELem(SqList L,int i){return L.data[i-1];
}
GetElem()中的i参数表示需要查找的下标的位序。如果你是使用静态分配的方式实现顺序表,那么数据元素就是都存放在data数组中,那么想要找到第几位元素就可以直接使用数组的下标直接找出,但是要注意数组下标是从0开始,因此我们要查找第i位的数据元素,就需要i-1,当然这里你如果想要增强代码的健壮性,那么就可以在GetElem()的开头加上判断i的合法性的语句。
动态分配实现
#define MaxSize 10 // 定义最大长度typedef struct{ElemType *data; // 用静态的“数组”存放数据元素int length; // 顺序表的当前长度
}SqList; // 顺序表的类型定义(动态分配方式)ElemType GetELem(SqList L,int i){return L.data[i-1];
}
如果你是使用动态分配的方式实现顺序表,那么使用malloc()开辟的一整片区域的开头指针就会返回给*data,虽然说*data是指针,但是也是可以使用访问数组下标的方式去访问。下面我们举例说明就能更明白这里所说的含义。
首先我们使用malloc()申请的一整块连续的空间会将指针返回给*data,这时候*data就会指向一整块连续空间的开头,如下图:

假设上图中的一小块矩形为1B,我们存放的数据元素的单位大小为6B(一个数据元素为6B),那么当我们使用数组下标的方式访问时*data[0],其实就是访问从起始位置开始到第6个矩形的位置(6B)
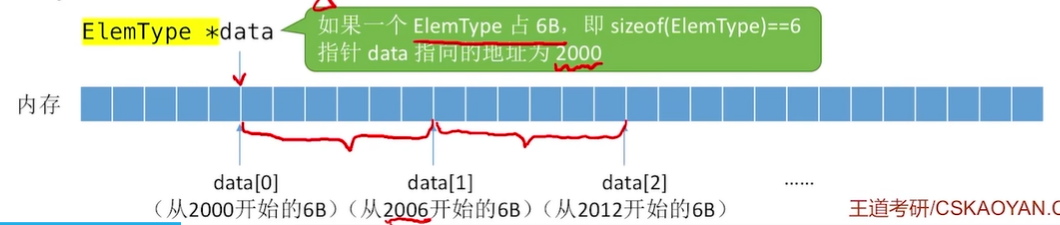
如果我们存入顺序表的数据元素的类型为int型(int型在内存中占4B),那么如果我们访问*data[0],就是从起始位置开始往后数4个格子,以此类推。
这也就是为什么,我们在之前讲解malloc()函数时,我们要将其返回的指针强制转换成你存放数据元素的指针同类型的指针。
(int *)malloc(InitSize*sizeof(int)):这里的(int *)就是将malloc()函数返回的指针强制转换成int型的指针- 如果你存放的数据元素是
int型(4B),但是你返回的指针是别的6B大小的类型的指针,那么我们在使用访问数组下标的方式,去访问顺序表中的元素时,就会乱套了
时间复杂度
ElemType GetELem(SqList L,int i){return L.data[i-1];
}
按位查找的代码就是上述的代码,所以可以看出按位查找的时间复杂度为:O(1)
也就是我们之前提到过的顺序表的随机存储特性。
- 因为顺序表中的所有元素都是连续存放的
- 并且每个元素的大小都相同
这就意味着我们只需要知道起始地址和每个元素的大小,就能快速准确的找到任意一个元素。
顺序表的按值查找
含义
根据所提供的值,在顺序表中找到符合该值的元素并返回。比如:我在表L中找到值为5的元素。
代码实现
#define InitSize 10 // 定义最大长度typedef struct{ElemType *data; // 用静态的“数组”存放数据元素int MaxSize; // 顺序表的最大容量int length; // 顺序表的当前长度
}SqList; // 顺序表的类型定义(动态分配方式)int LocateElem(SqList L,ElemType e){for(int i=0;i<L.length;i++)if(L.data[i]==e)return i+1; // 数组下标为i的元素值等于e,返回其位序:i+1return 0; // 退出循环说明查找失败
}
上述就是按值查找的代码实现,我们着重讲解LocateElem():
- 循环会遍历整个顺序表
- 比较遍历过程中的值是否和需要查找的值
e相等- 若相等,则返回该元素的位序:
i+1(下标+1) - 若不相等,则继续循环
- 若相等,则返回该元素的位序:
- 如果都没有,则退出函数并且返回0,表示没有查找到一样的值
注意:如果数据类型为基本数据类型(int、char、double、float等)是可以直接使用运算符
==去比较的,但是如果是两个结构类型的数据元素就不能直接使用==运算符去比较。所以,如果你需要比较两个结构类型的数据元素是否相等,你需要分别对应结构类型里面的分量是否相等。比如:a.name == b.name等
时间复杂度
最好情况:目标元素在表头
- 循环1次,最好时间复杂度 = O(1)
最坏情况:目标元素在表尾
- 循环n次:最坏时间复杂度 = O(n)
平均情况:假设目标元素出现在任何一个位置的概率相同,都是 1 n \frac{1}{n} n1
- 目标元素在第1位,循环1次;第2位,循环2次;… 第n位,循环n次
- 平均循环次数 = 1 1 n + 2 1 n + 3 1 n + . . . + n 1 n = n ( n + 1 ) 2 1 n = n + 1 2 1\frac{1}{n}+2\frac{1}{n}+3\frac{1}{n}+...+n\frac{1}{n}=\frac{n(n+1)}{2}\frac{1}{n}=\frac{n+1}{2} 1n1+2n1+3n1+...+nn1=2n(n+1)n1=2n+1
- 平均时间复杂度 = O(n)
结束语
已同步更新至个人博客:https://www.hibugs.net/index.php/sqlistsearch/
本人菜鸟一枚,仅分享学习笔记和经验。若有错误欢迎指出!共同学习、共同进步 😃
如果您觉得我的文章对您有所帮助,希望可以点个赞和关注,支持一下!十分感谢~(若您不想也没关系,只要文章能够对您有所帮助就是我最大的动力!)