目录
- 一、简介
- 二、字符流入流
- 1.1FileReader构造方法
- 1.2FileReader读取字符数据
- 三、字符流出流
- 3.1 FileWriter 构造方法
- 3.2FileWriter写入数据
- 3.3关闭close和刷新flush
- 3.4FileWriter的续写和换行
- 3.5文本文件复制
- 四、IO异常处理
- 五、小结
一、简介
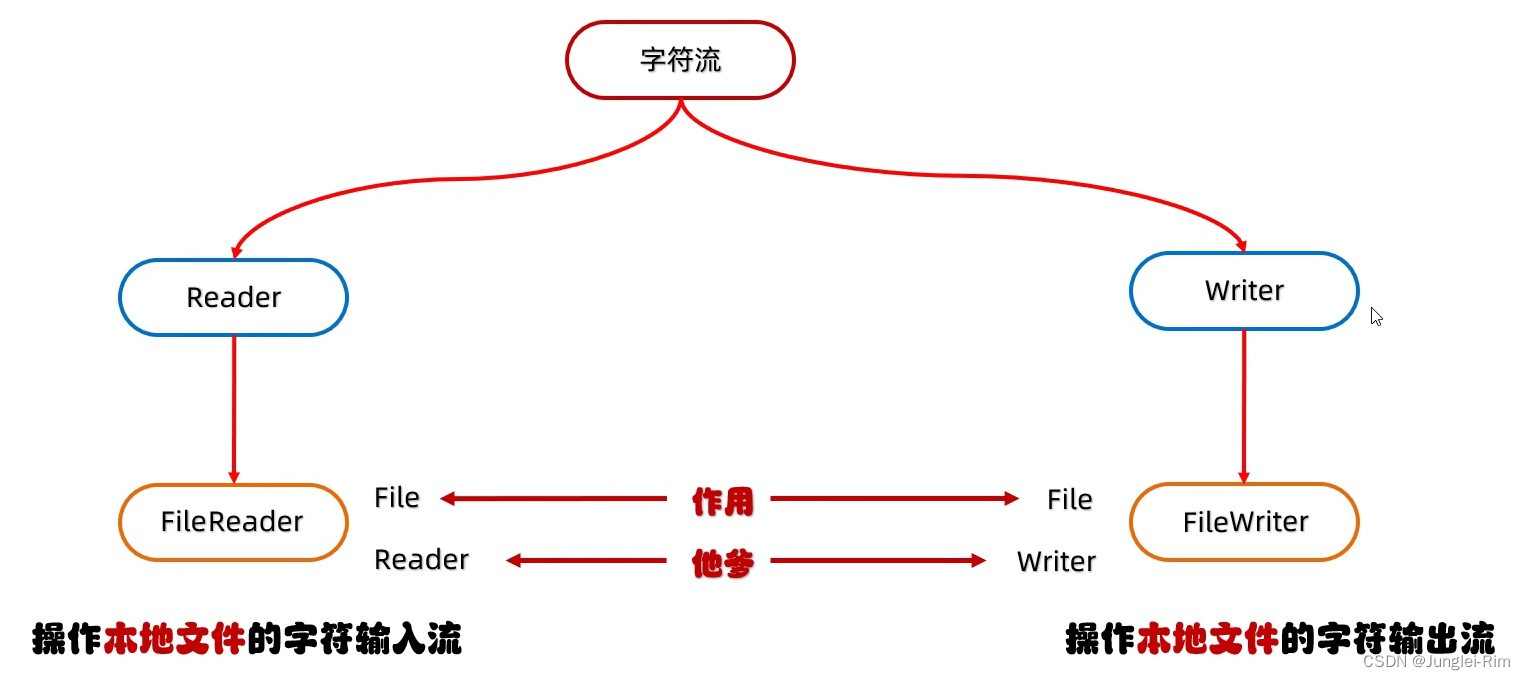
字符流 Reader 和 Writer 的故事要从它们的类关系图开始,来看图。
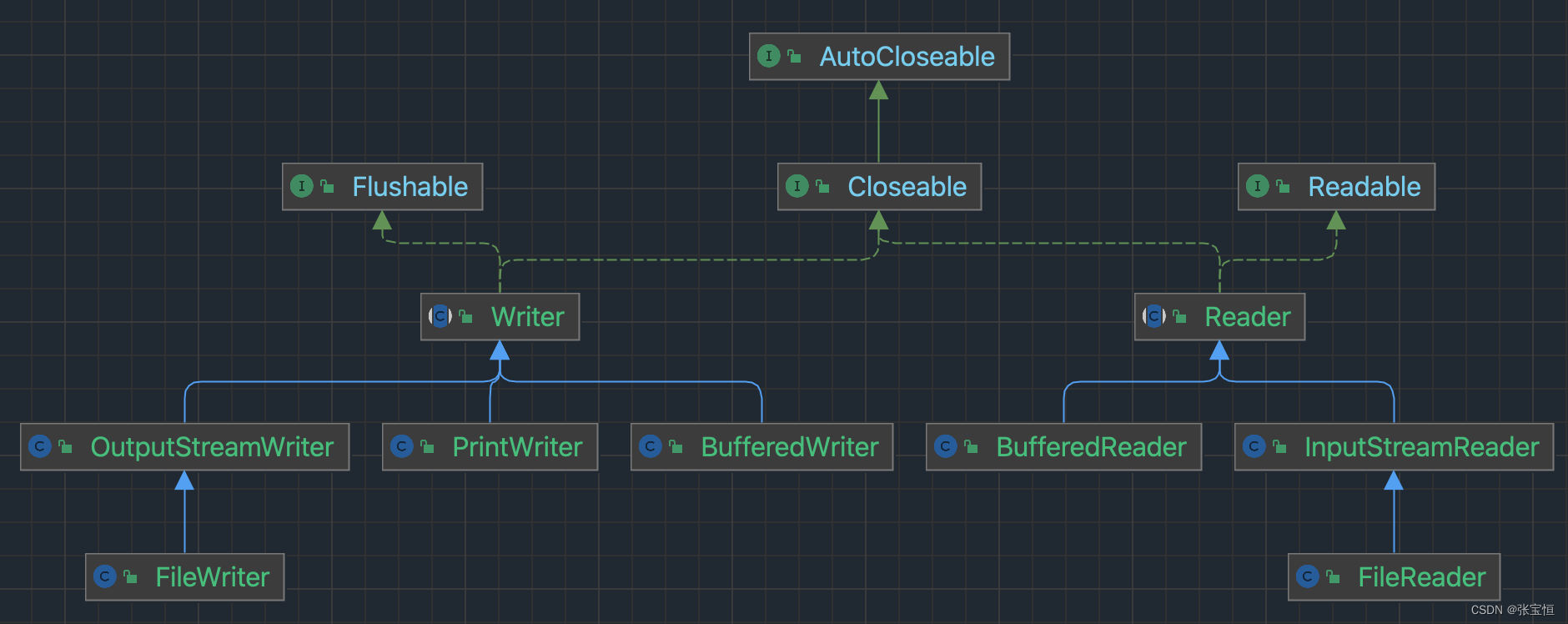 字符流是一种用于读取和写入字符数据的输入输出流。与字节流不同,字符流以字符为单位读取和写入数据,而不是以字节为单位。常用来处理文本信息。
字符流是一种用于读取和写入字符数据的输入输出流。与字节流不同,字符流以字符为单位读取和写入数据,而不是以字节为单位。常用来处理文本信息。
如果用字节流直接读取中文,可能会遇到乱码问题,见下例:
//FileInputStream为操作文件的字符输入流
FileInputStream inputStream = new FileInputStream("a.txt");//内容为“追风少年宝哥是傻 X”int len;
while ((len=inputStream.read())!=-1){System.out.print((char)len);
}
来看运行结果:
运行结果: 沉默王二是傻 X
之所以出现乱码是因为在字节流中,一个字符通常由多个字节组成,而不同的字符编码使用的字节数不同。如果我们使用了错误的字符编码,或者在读取和写入数据时没有正确处理字符编码的转换,就会导致读取出来的中文字符出现乱码。
例如,当我们使用默认的字符编码(见上例)读取一个包含中文字符的文本文件时,就会出现乱码。因为默认的字符编码通常是 ASCII 编码,它只能表示英文字符,而不能正确地解析中文字符。
那使用字节流该如何正确地读出中文呢?见下例。
try (FileInputStream inputStream = new FileInputStream("a.txt")) {byte[] bytes = new byte[1024];int len;while ((len = inputStream.read(bytes)) != -1) {System.out.print(new String(bytes, 0, len));}
}
为什么这种方式就可以呢?
因为我们拿 String 类进行了解码,查看new String(byte bytes[], int offset, int length)的源码就可以发现,该构造方法有解码功能:
public String(byte bytes[], int offset, int length) {checkBounds(bytes, offset, length);this.value = StringCoding.decode(bytes, offset, length);
}
继续追看 StringCoding.decode() 方法调用的 defaultCharset() 方法,会发现默认编码是UTF-8,代码如下
public static Charset defaultCharset() {if (defaultCharset == null) {synchronized (Charset.class) {if (cs != null)defaultCharset = cs;elsedefaultCharset = forName("UTF-8");}}return defaultCharset;
}
static char[] decode(byte[] ba, int off, int len) {String csn = Charset.defaultCharset().name();try {// use charset name decode() variant which provides caching.return decode(csn, ba, off, len);} catch (UnsupportedEncodingException x) {warnUnsupportedCharset(csn);}
}在 Java 中,常用的字符编码有 ASCII、ISO-8859-1、UTF-8、UTF-16 等。其中,ASCII 和 ISO-8859-1 只能表示部分字符,而 UTF-8 和 UTF-16 可以表示所有的 Unicode 字符,包括中文字符。
当我们使用 new String(byte bytes[], int offset, int length) 将字节流转换为字符串时,Java 会根据 UTF-8 的规则将每 3 个字节解码为一个中文字符,从而正确地解码出中文。
尽管字节流也有办法解决乱码问题,但不够直接,于是就有了字符流,专门用于处理文本文件(音频、图片、视频等为非文本文件)。
从另一角度来说:字符流 = 字节流 + 编码表
二、字符流入流
java.io.Reader是字符输入流的超类(父类),它定义了字符输入流的一些共性方法:
- close():关闭此流并释放与此流相关的系统资源。
- read():从输入流读取一个字符。
- read(char[] cbuf):从输入流中读取一些字符,并将它们存储到字符数组 cbuf中
FileReader 是 Reader 的子类,用于从文件中读取字符数据。它的主要特点如下:
可以通过构造方法指定要读取的文件路径。
每次可以读取一个或多个字符。
可以读取 Unicode 字符集中的字符,通过指定字符编码来实现字符集的转换。
1.1FileReader构造方法
- FileReader(File file):创建一个新的 FileReader,参数为File对象。
- FileReader(String fileName):创建一个新的 FileReader,参数为文件名。
代码示例如下:
// 使用File对象创建流对象
File file = new File("a.txt");
FileReader fr = new FileReader(file);// 使用文件名称创建流对象
FileReader fr = new FileReader("b.txt");1.2FileReader读取字符数据
①、读取字符:read方法,每次可以读取一个字符,返回读取的字符(转为 int 类型),当读取到文件末尾时,返回-1。代码示例如下:
// 使用文件名称创建流对象
FileReader fr = new FileReader("abc.txt");
// 定义变量,保存数据
int b;
// 循环读取
while ((b = fr.read())!=-1) {System.out.println((char)b);
}
// 关闭资源
fr.close();②、读取指定长度的字符:read(char[] cbuf, int off, int len),并将其存储到字符数组中。其中,cbuf 表示存储读取结果的字符数组,off 表示存储结果的起始位置,len 表示要读取的字符数。代码示例如下:
File textFile = new File("docs/约定.md");
// 给一个 FileReader 的示例
// try-with-resources FileReader
try(FileReader reader = new FileReader(textFile);) {// read(char[] cbuf)char[] buffer = new char[1024];int len;while ((len = reader.read(buffer, 0, buffer.length)) != -1) {System.out.print(new String(buffer, 0, len));}
}在这个例子中,使用 FileReader 从文件中读取字符数据,并将其存储到一个大小为 1024 的字符数组中。每次读取 len 个字符,然后使用 String 构造方法将其转换为字符串并输出。
FileReader 实现了 AutoCloseable 接口,因此可以使用 try-with-resources 语句自动关闭资源,避免了手动关闭资源的繁琐操作。
三、字符流出流
java.io.Writer 是字符输出流类的超类(父类),可以将指定的字符信息写入到目的地,来看它定义的一些共性方法:
- write(int c) 写入单个字符。
- write(char[] cbuf) 写入字符数组。
- write(char[] cbuf, int off, int len) 写入字符数组的一部分,off为开始索引,len为字符个数。
- write(String str) 写入字符串。
- write(String str, int off, int len) 写入字符串的某一部分,off 指定要写入的子串在 str 中的起始位置,len 指定要写入的子串的长度。
- flush() 刷新该流的缓冲。
- close() 关闭此流,但要先刷新它。
java.io.FileWriter 类是 Writer 的子类,用来将字符写入到文件。
3.1 FileWriter 构造方法
- FileWriter(File file): 创建一个新的 FileWriter,参数为要读取的File对象。
- FileWriter(String fileName): 创建一个新的 FileWriter,参数为要读取的文件的名称。
代码示例如下:
// 第一种:使用File对象创建流对象
File file = new File("a.txt");
FileWriter fw = new FileWriter(file);// 第二种:使用文件名称创建流对象
FileWriter fw = new FileWriter("b.txt");3.2FileWriter写入数据
①、写入字符:write(int b) 方法,每次可以写出一个字符,代码示例如下:
FileWriter fw = null;
try {fw = new FileWriter("output.txt");fw.write(72); // 写入字符'H'的ASCII码fw.write(101); // 写入字符'e'的ASCII码fw.write(108); // 写入字符'l'的ASCII码fw.write(108); // 写入字符'l'的ASCII码fw.write(111); // 写入字符'o'的ASCII码
} catch (IOException e) {e.printStackTrace();
} finally {try {if (fw != null) {fw.close();}} catch (IOException e) {e.printStackTrace();}
}
在这个示例代码中,首先创建一个 FileWriter 对象 fw,并指定要写入的文件路径 “output.txt”。然后使用 fw.write() 方法将字节写入文件中,这里分别写入字符’H’、‘e’、‘l’、‘l’、'o’的 ASCII 码。最后在 finally 块中关闭 FileWriter 对象,释放资源。
需要注意的是,使用 write(int b) 方法写入的是一个字节,而不是一个字符。如果需要写入字符,可以使用 write(char cbuf[]) 或 write(String str) 方法。
②、写入字符数组:write(char[] cbuf) 方法,将指定字符数组写入输出流。代码示例如下:
FileWriter fw = null;
try {fw = new FileWriter("output.txt");char[] chars = {'H', 'e', 'l', 'l', 'o'};fw.write(chars); // 将字符数组写入文件
} catch (IOException e) {e.printStackTrace();
} finally {try {if (fw != null) {fw.close();}} catch (IOException e) {e.printStackTrace();}
}
③、写入指定字符数组:write(char[] cbuf, int off, int len) 方法,将指定字符数组的一部分写入输出流。代码示例如下(重复的部分就不写了哈,参照上面的部分):
fw = new FileWriter("output.txt");char[] chars = {'H', 'e', 'l', 'l', 'o', ',', ' ', 'W', 'o', 'r', 'l', 'd', '!'};
fw.write(chars, 0, 5); // 将字符数组的前 5 个字符写入文件使用 fw.write() 方法将字符数组的前 5 个字符写入文件中。
④、写入字符串:write(String str) 方法,将指定字符串写入输出流。代码示例如下:
fw = new FileWriter("output.txt");
String str = "追风少年";
fw.write(str); // 将字符串写入文件
⑤、写入指定字符串:write(String str, int off, int len) 方法,将指定字符串的一部分写入输出流。代码示例如下(try-with-resources形式):
String str = "追风少年之宝哥!";
try (FileWriter fw = new FileWriter("output.txt")) {fw.write(str, 0, 5); // 将字符串的前 5 个字符写入文件
} catch (IOException e) {e.printStackTrace();
}
【注意】如果不关闭资源,数据只是保存到缓冲区,并未保存到文件中。
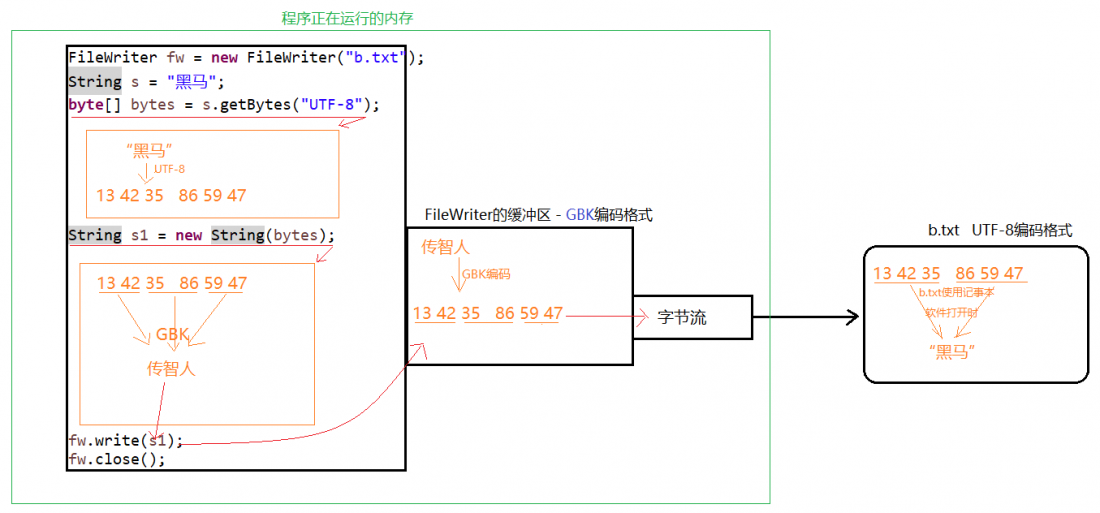
3.3关闭close和刷新flush
因为 FileWriter 内置了缓冲区 ByteBuffer,所以如果不关闭输出流,就无法把字符写入到文件中。
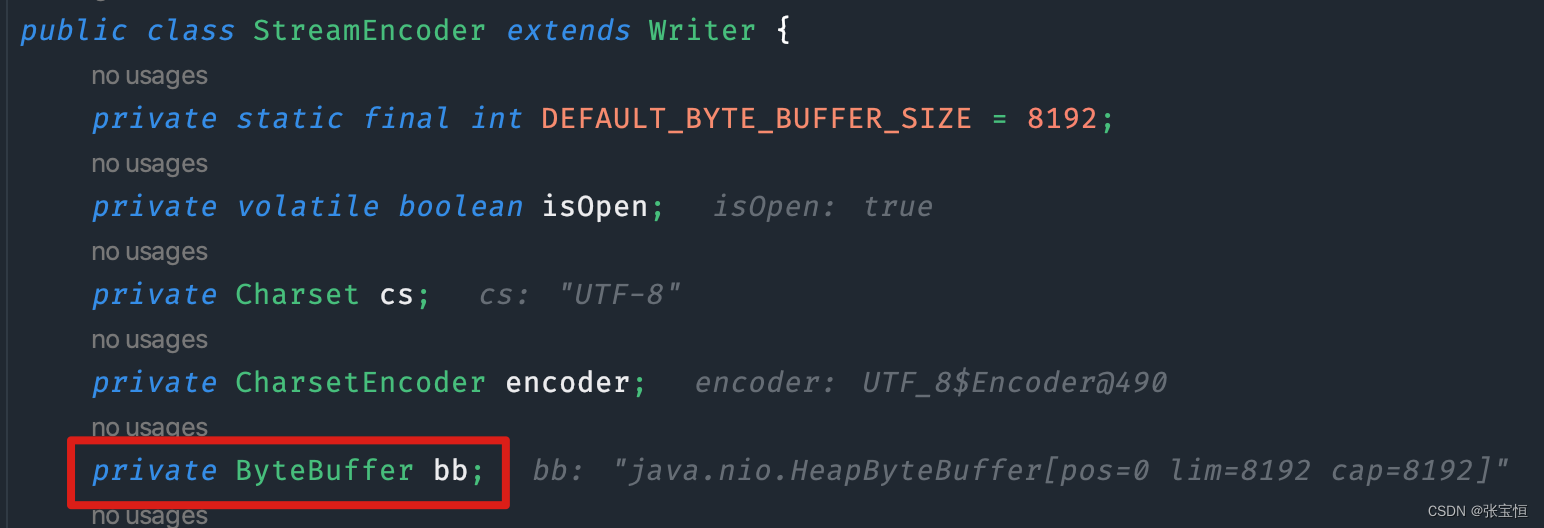
flush :刷新缓冲区,流对象可以继续使用。
close :先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
flush还是比较有趣的,来段代码体会体会:
//源 也就是输入流【读取流】 读取a.txt文件
FileReader fr=new FileReader("abc.txt"); //必须要存在a.txt文件,否则报FileNotFoundException异常
//目的地 也就是输出流
FileWriter fw=new FileWriter("b.txt"); //系统会自动创建b.txt,因为它是输出流!
int len;
while((len=fr.read())!=-1){fw.write(len);
}
//注意这里是没有使用close关闭流,开发中不能这样做,但是为了更好的体会flush的作用
运行效果是怎么样的呢?答案是b.txt文件中依旧是空的,并没有任何东西。
原因我们前面已经说过了。编程就是这样,不去敲,永远学不会!!!所以一定要去敲,多敲啊!!!
在以上的代码中再添加下面三句代码,b.txt文件就能复制到源文件的数据了!
fr.close();
fw.flush();
fw.close();
你可以使用下面的代码示例再体验一下:
// 使用文件名称创建流对象
FileWriter fw = new FileWriter("fw.txt");
// 写出数据,通过flush
fw.write('刷'); // 写出第1个字符
fw.flush();
fw.write('新'); // 继续写出第2个字符,写出成功
fw.flush();// 写出数据,然后close
fw.write('关'); // 写出第1个字符
fw.close();
fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed
fw.close();注意,即便是flush方法写出了数据,操作的最后还是要调用close方法,释放系统资源。当然你也可以用 try-with-resources 的方式。
3.4FileWriter的续写和换行
续写和换行:操作类似于FileOutputStream操作,直接上代码:
// 使用文件名称创建流对象,可以续写数据
FileWriter fw = new FileWriter("fw.txt",true);
// 写出字符串
fw.write("追风少年之宝哥");
// 写出换行
fw.write("\r\n");
// 写出字符串
fw.write("是傻 X");
// 关闭资源
fw.close();输出结果如下所示:
输出结果:
追风少年之宝哥
是傻 X
3.5文本文件复制
直接上代码:
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;public class CopyFile {public static void main(String[] args) throws IOException {//创建输入流对象FileReader fr=new FileReader("aa.txt");//文件不存在会抛出java.io.FileNotFoundException//创建输出流对象FileWriter fw=new FileWriter("copyaa.txt");/*创建输出流做的工作:* 1、调用系统资源创建了一个文件* 2、创建输出流对象* 3、把输出流对象指向文件 * *///文本文件复制,一次读一个字符copyMethod1(fr, fw);//文本文件复制,一次读一个字符数组copyMethod2(fr, fw);fr.close();fw.close();}public static void copyMethod1(FileReader fr, FileWriter fw) throws IOException {int ch;while((ch=fr.read())!=-1) {//读数据fw.write(ch);//写数据}fw.flush();}public static void copyMethod2(FileReader fr, FileWriter fw) throws IOException {char chs[]=new char[1024];int len=0;while((len=fr.read(chs))!=-1) {//读数据fw.write(chs,0,len);//写数据}fw.flush();}
}四、IO异常处理
我们在学习的过程中可能习惯把异常抛出,而实际开发中建议使用try…catch…finally 代码块,处理异常部分,格式代码如下:
// 声明变量
FileWriter fw = null;
try {//创建流对象fw = new FileWriter("fw.txt");// 写出数据fw.write("二哥真的帅"); //哥敢摸si
} catch (IOException e) {e.printStackTrace();
} finally {try {if (fw != null) {fw.close();}} catch (IOException e) {e.printStackTrace();}
}或者直接使用 try-with-resources 的方式。
try (FileWriter fw = new FileWriter("fw.txt")) {// 写出数据fw.write("二哥真的帅"); //哥敢摸si
} catch (IOException e) {e.printStackTrace();
}
在这个代码中,try-with-resources 会在 try 块执行完毕后自动关闭 FileWriter 对象 fw,不需要手动关闭流。如果在 try 块中发生了异常,也会自动关闭流并抛出异常。因此,使用 try-with-resources 可以让代码更加简洁、安全和易读。
五、小结
Writer 和 Reader 是 Java I/O 中用于字符输入输出的抽象类,它们提供了一系列方法用于读取和写入字符数据。它们的区别在于 Writer 用于将字符数据写入到输出流中,而 Reader 用于从输入流中读取字符数据。
Writer 和 Reader 的常用子类有 FileWriter、FileReader,可以将字符流写入和读取到文件中。
在使用 Writer 和 Reader 进行字符输入输出时,需要注意字符编码的问题.
相关文章链接:
javaIO之各种流的分类与实际应用
javaIO流之文件流
javaIO流之字节流
javaIO流之字符流
javaIO流之缓冲流
javaIO流之转换流
javaIO流之序列流
我如杀戮之中绽放,亦如黎明前的花朵。如果觉得有用,点个赞吧~~~~