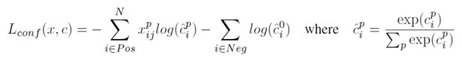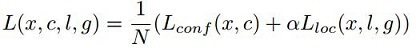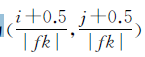目录
- 前言
- SSD网络
前言
前面几篇文章我们讲解了YOLO系类的论文,今天我们来看下SSD算法。对YOLO有兴趣的小伙伴们可以一步到我前面的几篇博文:
- YOLOv1目标检测算法——通俗易懂的解析
- YOLOv2目标检测算法——通俗易懂的解析
- YOLOv3目标检测算法——通俗易懂的解析
- YOLOv4目标检测算法——通俗易懂的解析
- YOLOv5目标检测算法——通俗易懂的解析
SSD网络
SSD论文地址:https://arxiv.org/abs/1512.02325v5
SSD网络是在2016年ECCV上发表的论文,超越了当时地表最强的目标检测算法Faster RCNN性能,现在看来时间有点久远了,但是SSD还是很经典的算法,SSD是一个单阶段的目标检测算法,里面的有些思路还是值得我们学习的,很多公司在面试的时候也会问到SSD算法,所以还是有必要的学习一下的。
当时流行的Faster RCNN是一个双阶段的目标检测网络,存在着不少问题:
- 小目标检测效果很差(因为
Faster RCNN只在一个特征层上进行检测,不适合检测小目标。所以能不能直接在低层次特征上进行预测?看SSD) - 模型很大,检测速度慢(主要是因为分两步走)
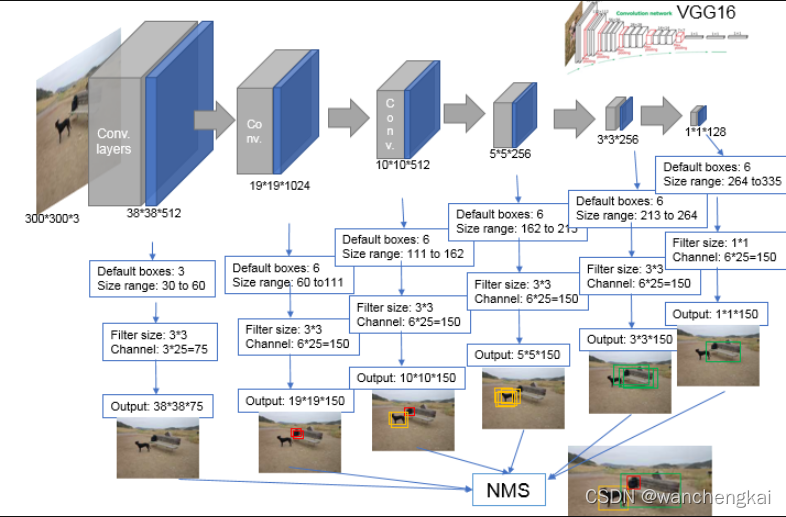
先来看下SSD的整体框图,输入图像必须是 300 × 300 300\times300 300×300,然后输入到VGG16网络(后半部分网络重新设计了)through表示贯穿到VGG16的Conv5_3,前半部分网络只用到了Con5_3_layer,什么意思呢,我们看下面的VGG网络,就是对应到第五层网络的第三个卷积层 ,Conv4_3是SSD输出的第一个卷积层,论文中还将Maxpooling5(Conv5_3后面的池化核)的池化核大小从原本的 2 × 2 2\times2 2×2,步距为2调整为 3 × 3 3\times3 3×3大小,步距为1,所以经过此操作之后,Conv5_3的输出特征层的大小时不会发生变化的。在此之后会添加其他的卷积层,得到其他的预测特征层,图中的FC6就是对应VGG16中的第一个全连接,FC7对应VGG16中的第二个全连接层,接下来通过一些列的卷积层得到输出特征3,4,5,6,总共有6层特征输出,前面的低层特征输出用于检测尺寸比较小的目标,后面的高层输出特征负责检测尺寸较大的目标。在前面讲YOLOv3的时候我们对此已经解释过了,思想都是一样的。
注意:图中总共有6个输出特征层(Extra Feature Layers)



SSD中使用default box来匹配目标。那么什么是default box呢,实际上就是Faster R-CNN中的anchor box,原理一样,这里的default box将他们放在不同的特征层上面。default box的比例和尺度怎么设定呢?以下是原论文给的公式:
s k = s m i n + s m a x − s m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] s_k = s_{min} + \frac{s_{max}-s_{min}}{m-1}(k-1),k\in[1,m] sk=smin+m−1smax−smin(k−1),k∈[1,m]
很多大神实现的SSD算法用的公式并不是上面的公式,简单了解下即可。我们直接给出每个scale所对应的aspect的比例。
s c a l e = [ ( 21 , 45 ) , ( 45 , 99 ) , ( 99 , 153 ) , ( 153 , 207 ) , ( 207 , 261 ) , ( 261 , 315 ) ] a s p e c t = [ ( 1 , 2 , 0.5 ) , ( 1 , 2 , 0.5 , 3 , 1. / 3 ) , ( 1 , 2 , 0.5 , 3 , 1. / 3 ) , ( 1 , 2 , 0.5 , 3 , 1. / 3 ) , ( 1 , 2 , 0.5 ) , ( 1 , 2 , 0.5 ) ] scale=[(21,45),(45,99),(99,153),(153,207),(207,261),(261,315)]\\ aspect=[(1,2,0.5),(1,2,0.5,3,1./3),(1,2,0.5,3,1./3),(1,2,0.5,3,1./3),(1,2,0.5),(1,2,0.5)] scale=[(21,45),(45,99),(99,153),(153,207),(207,261),(261,315)]aspect=[(1,2,0.5),(1,2,0.5,3,1./3),(1,2,0.5,3,1./3),(1,2,0.5,3,1./3),(1,2,0.5),(1,2,0.5)]
scale表示目标尺度,aspect表示每个尺度所对应的一系列比例,初看这些参数可能一脸懵逼,为什么每个scale会有两个值?我们先来看下原文怎么解释的:对于比例为1的情况,在每个特征层上会额外的添加一个default box,default box的scale是 ( s k s k + 1 ) \sqrt(s_{k}s_{k+1}) (sksk+1),其中, s k s_{k} sk对应的就是scale中的第一个元素, s k + 1 s_{k+1} sk+1就是scale中的第二个元素,也是下一个预测特征层的 s k s_{k} sk。如下图所示每层预测特征层的默认框比例和尺寸。
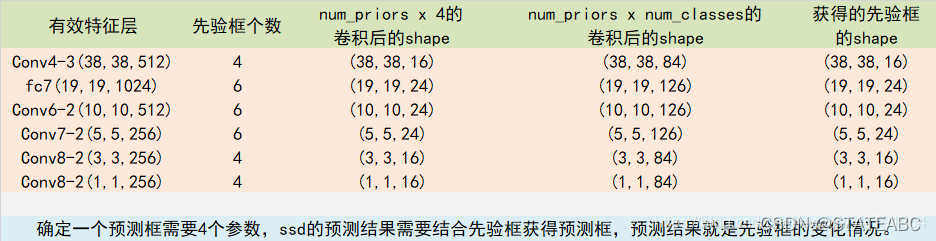
特征图层 特征图层的宽和高 默认框尺寸 默认框数量 特征图层(1) 38 × 38 21 { 1 / 2 , 1 , 2 } ; 21 × 45 { 1 } 38 × 38 × 4 特征图层(2) 19 × 19 45 { 1 / 3 , 1 / 2 , 1 , 2 , 3 } ; 45 × 99 { 1 } 19 × 19 × 6 特征图层(3) 10 × 10 99 { 1 / 3 , 1 / 2 , 1 , 2 , 3 } ; 99 × 153 { 1 } 10 × 10 × 6 特征图层(4) 5 × 5 153 { 1 / 3 , 1 / 2 , 1 , 2 , 3 } ; 153 × 207 { 1 } 5 × 5 × 6 特征图层(5) 3 × 3 207 { 1 / 2 , 1 , 2 } ; 207 × 261 { 1 } 3 × 3 × 4 特征图层(6) 1 × 1 261 { 1 / 2 , 1 , 2 } ; 261 × 315 { 1 } 1 × 1 × 4 \begin{array}{cccc} \hline \text { 特征图层 } & \text { 特征图层的宽和高 } & \text { 默认框尺寸 } & \text { 默认框数量 } \\ \hline \text { 特征图层(1) } & 38 \times 38 & 21\{1 / 2,1,2\} ; \sqrt{21 \times 45}\{1\} & 38 \times 38 \times 4 \\ \text { 特征图层(2) } & 19 \times 19 & 45\{1 / 3,1 / 2,1,2,3\} ; \sqrt{45 \times 99}\{1\} & 19 \times 19 \times 6 \\ \text { 特征图层(3) } & 10 \times 10 & 99\{1 / 3,1 / 2,1,2,3\} ; \sqrt{99 \times 153}\{1\} & 10 \times 10 \times 6 \\ \text { 特征图层(4) } & 5 \times 5 & 153\{1 / 3,1 / 2,1,2,3\} ; \sqrt{153 \times 207}\{1\} & 5 \times 5 \times 6 \\ \text { 特征图层(5) } & 3 \times 3 & 207\{1 / 2,1,2\} ; \sqrt{207 \times 261}\{1\} & 3 \times 3 \times 4 \\ \text { 特征图层(6) } & 1 \times 1 & 261\{1 / 2,1,2\} ; \sqrt{261 \times 315}\{1\} & 1 \times 1 \times 4 \\ \hline \end{array} 特征图层 特征图层(1) 特征图层(2) 特征图层(3) 特征图层(4) 特征图层(5) 特征图层(6) 特征图层的宽和高 38×3819×1910×105×53×31×1 默认框尺寸 21{1/2,1,2};21×45{1}45{1/3,1/2,1,2,3};45×99{1}99{1/3,1/2,1,2,3};99×153{1}153{1/3,1/2,1,2,3};153×207{1}207{1/2,1,2};207×261{1}261{1/2,1,2};261×315{1} 默认框数量 38×38×419×19×610×10×65×5×63×3×41×1×4

关于比例信息,我们看下面的一段文字,对于conv4_3,conv10_2,conv11_2我们都会使用四个default box,对于其他的预测特征层会使用六个default box。观察上面的网络模型图,可以发现,也就是第一个,和倒数第一个,倒数第二个预测特征层是使用4个default box,其他的都是6个。
根据刚才对原文的解释,我们来看下这几组数据到底怎么看。先来看下第一个预测特征层scale=(21,45)的情况,scale为21的时候,会有aspect=(1:1,2:1,1:2)三个比例,对于 ( 21 × 45 ) \sqrt(21\times45) (21×45)的scale只有一个aspect=(1:1)的比例,其他的以此类推。根据上面的default的生成方式我们可以计算总共有default box的数量:
38 × 38 × 4 + 19 × 19 × 6 + 10 × 10 × 6 + 5 × 5 × 6 + 3 × 3 × 4 + 1 × 1 × 4 = 8732 38\times38\times4 +19\times19\times6 +10\times10\times6 +5\times5\times6 +3\times3\times4 +1\times1\times4=8732 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732

看了上面的default box的设计,是不是感觉跟anchor的设计有异曲同工之处,其实他俩就是一个东西,只不过SSD的尺寸大小是人为设计的,而YOLO的anchor是通过k-means聚类学习得到的。接下来我们再来看下预测器的设计与实现,怎么在6个输出特征层上进行预测?依旧先看下原文的解释:
对于 m × n × p m\times n\times p m×n×p的预测特征层,直接使用卷积核大小为 3 × 3 3\times3 3×3,channel为p的卷积核实现,通过这个卷积层来生成概率分数和相对default box的坐标偏移量,即边界框回归参数。

我们刚才讲在每个特征层上使用 3 × 3 3\times3 3×3的卷积核进行预测,那么我们到底需要使用多少个卷积核呢?看下面论文中的解释,我们知道在每个预测特层上的每个位置会有k个default box,对每个default box会计算c个类别分数和4个坐标偏移量,那么我们就需要 ( c + 4 ) × k (c+4)\times k (c+4)×k个卷积核进行处理,所以对于一个 m × n m\times n m×n的输出特征层而言,总共有 ( c + 4 ) × k × m × n (c+4)\times k \times m \times n (c+4)×k×m×n个输出值。注意这个地方区分下跟Faster RCNN的区别,在Faster RCNN生成边界框回归参数的时候,对于每个anchor会生成 4 × c × n u m a n c h o r s 4\times c \times num_{anchors} 4×c×numanchors个边界框回归参数,即对每个anchor针对预测的类别来生成4个回归参数,在Faster RCNN中,这里是 4 × c 4\times c 4×c,而在SSD中,针对每个default box 只生成4个边界框回归参数,不关注每个default box 是归于哪个类别的。一个是针对类别生成边界回归参数,一个是针对anchor的个数生成的。

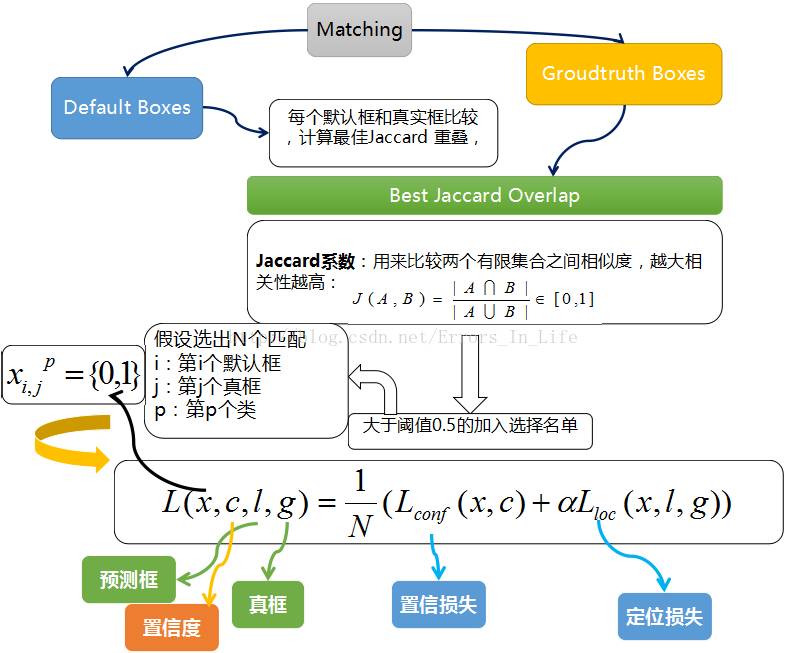
下面我们再来介绍下训练阶段正负样本的选取,看到这个是不是发现SSD算法和YOLO系列的有点相似。我么依旧先看下原论文怎么解释的,论文中给了两个匹配准则:
- 对于每个
ground truth去匹配跟他 I o U IoU IoU最大的的default box。 - 对于任意一个
default box,它只要与任意一个ground truth的 I o U IoU IoU的大于0.5,也认为他是正样本。
匹配准则都大同小异,跟YOLO和Faster RCNN 都很类似,理解一个,其他的基本上都能理解。

下面我们再来看下负样本的选取,正样本选取完之后,剩下的样本都可以归为负样本,但是剩下的负样本并不是都用来计算,上面我们计算过总共生成了8732个default box,但是训练的时候default box匹配到的ground truth有很少,即正样本很少,导致正负样本极不平衡。对于负样本的选取SSD是这样做的,首先对于刚刚计算剩下的所有的负样本计算他的最大confidence loss,confidence loss越大表示网络将负样本预测为目标的概率越大,所以就根据计算的confidence loss来选取排在前面的负样本,根据正样本的个数选取正负样本的比例为1:3。

上面讲了正负样本的计算,下面我们来看下怎么计算模型的损失,先来看下损失函数:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( c , l , g ) ) L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(c,l,g)) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(c,l,g))
上式右边的的第一项表示类别损失,第二项表示定位损失,N表示正样本的个数, α \alpha α是平衡系数,直接取1即可。类别损失有分为两部分:
L conf ( x , c ) = − ∑ i ∈ P o s N x i j p log ( c ^ i p ) − ∑ i ∈ N e g log ( c ^ i 0 ) where c ^ i p = exp ( c i p ) ∑ p exp ( c i p ) L_{\text {conf }}(x, c)=-\sum_{i \in P o s}^N x_{i j}^p \log \left(\hat{c}_i^p\right)-\sum_{i \in N e g} \log \left(\hat{c}_i^0\right) \quad \text { where } \quad \hat{c}_i^p=\frac{\exp \left(c_i^p\right)}{\sum_p \exp \left(c_i^p\right)} Lconf (x,c)=−i∈Pos∑Nxijplog(c^ip)−i∈Neg∑log(c^i0) where c^ip=∑pexp(cip)exp(cip)
上式右边第一项表示正样本损失,第二项表示负样本损失。这个损失函数就是一个softmax loss。下面解释下公式中的符号含义:
- c ^ i p \hat{c}_i^p c^ip表示预测的第 i i i个
default box(类别是P)对应的GT box的类别概率 - x i j p = 0 , 1 x_{i j}^p={0,1} xijp=0,1为第 i i i个
default box匹配到的第 j j j个GT box(类别是P),可以直接看成1即可。
接下来我们再来看下定位损失怎么计算(跟Faster RCNN的计算方式基本一模一样),先看公式,第二项为定位损失,我们重写一下:
L ( x , c , l , g ) = 1 N ( L conf ( x , c ) + α L l o c ( x , l , g ) ) L(x, c, l, g)=\frac{1}{N}\left(L_{\operatorname{conf}}(x, c)+\alpha L_{l o c}(x, l, g)\right) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
L l o c ( x , l , g ) = ∑ i ∈ P o s N ∑ m ∈ { c x , c y , w , h } x i j k smooth L 1 ( l i m − g ^ j m ) g ^ j c x = ( g j c x − d i c x ) / d i w g ^ j c y = ( g j c y − d i c y ) / d i h g ^ j w = log ( g j w d i w ) g ^ j h = log ( g j h d i h ) \begin{gathered} L_{l o c}(x, l, g)=\sum_{i \in P o s}^N \sum_{m \in\{c x, c y, w, h\}} x_{i j}^k \operatorname{smooth}_{\mathrm{L} 1}\left(l_i^m-\hat{g}_j^m\right) \\ \hat{g}_j^{c x}=\left(g_j^{c x}-d_i^{c x}\right) / d_i^w \quad \hat{g}_j^{c y}=\left(g_j^{c y}-d_i^{c y}\right) / d_i^h \\ \hat{g}_j^w=\log \left(\frac{g_j^w}{d_i^w}\right) \quad \hat{g}_j^h=\log \left(\frac{g_j^h}{d_i^h}\right) \end{gathered} Lloc(x,l,g)=i∈Pos∑Nm∈{cx,cy,w,h}∑xijksmoothL1(lim−g^jm)g^jcx=(gjcx−dicx)/diwg^jcy=(gjcy−dicy)/dihg^jw=log(diwgjw)g^jh=log(dihgjh)
smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise \operatorname{smooth}_{L_1}(x)= \begin{cases}0.5 x^2 & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise }\end{cases} smoothL1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise - l i m l_{i}^{m} lim为预测对应第 i i i个正样本的回归参数
- g ^ j m \hat{g}_j^m g^jm为正样本 i i i匹配的第 j j j个
GT box的回归参数
至此,SSD算法的理论部分基本上已经介绍完了,如有错误,敬请指正!