一、计算在数据源和分析中的位置
基本计算和LOD表达式是数据源查询的计算,返回的是一个结果集。统称为custom calculation,生成的结果是custom filed 自定义字段,字段在哪里?字段在数据源层面。
① 基本计算和LOD计算是在数据源层面的计算,部分字段具有全局意义。
比如创建一个“成本”字段,[cost]=[sales]-[profit],这个行级别字段在商品明细行级别具有意义的,在聚合后也具有意义;
② 但大部分不像维度或度量字段具有全局的意义,这些自定义字段受限于视图。
比如视图计算字段,比如sum([cost])=sum([sales])-sum([profit]),通过把聚合计算加入视图,可以让tableau自己决定在哪个层面执行聚合;
再比如创建LOD计算字段,{fixed [customer ID]: avg([sales])},虽然也会在数据源层面创建,但行级别的这个字段是没有意义的,只有在详细级别或相关视图级别上才具有意义。
表计算table calculation是对视图详细级别聚合结果的二次计算,既然是视图详细级别,它要求的数据必须是聚合计算。它生成的是什么?是结果集,而且立刻在视图上显示,并没有在数据源层面创建字段或者有影响。
二、表计算的独特用法
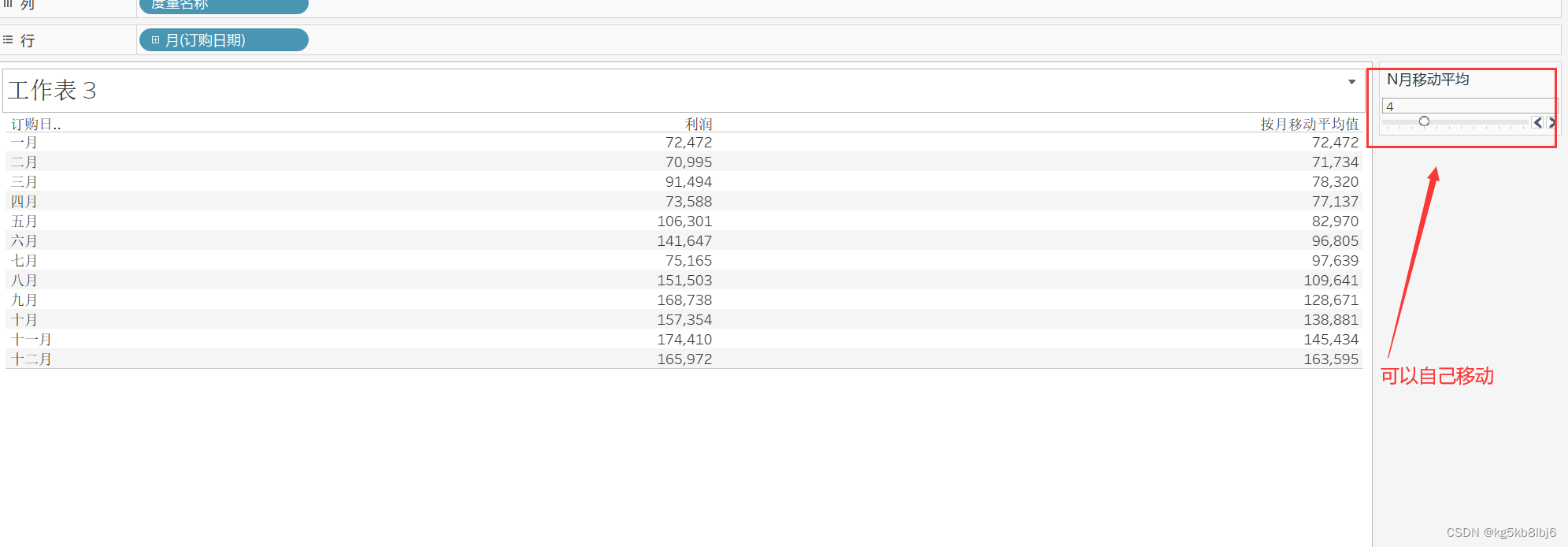
基本计算和LOD表达式:只能为每个数据分区或分组输出单一值。表计算和其他计算最大的区别在于它能够以一个表达式,在每个数据分区(单元格、区、表)返回多个值。清晰的理解这一点,才能明白为什么只有表计算才能满足下列特别需求:
- 排序
- 递归(比如:累计总计)
- 移动计算(比如:移动平均)
- 行内计算(比如:期间对照计算)
这几个计算,都是返回多个值,最简单的比如“排序”,一个rank()可以为视图中的一百行数据返回100个数值,比如total计算,根据分区寻址,返回多个值。这是基本计算和LOD计算做不到的
三、如何选择计算?
1. 特殊用法、数据齐全,则优先表计算,因为表计算更快,与数据源无关
2. 多个数据详细级别,使用LOD表达式
3. 使用基本字段增加新字段,比如比率、达成度等

第一次判断:是否是特殊计算?
第二次判断:视图中有所需要的数据吗?
第三次判断:如果视图层面没有需要的数据,怎么办?
【一】应该首先将相关的数据字段拖入到视图,如果颗粒度完整,重新尝试表计算。常见的表计算已经在快速表计算预设了。
【二】在判断是否视图具有所有数据时,一定要区分聚合数据和非聚合数据。
比如:我们有一个各个子分类销售额的散点图,需求是计算各子分类的总额百分比,貌似我们拥有相关的数据,其实不在一个详细级别。总额百分比需要计算聚合的占比,散点图的数据不是聚合,需要先执行聚合(颗粒度降低)
四、总结
| 计算名称 | 基本计算 | LOD表达式计算 | 表计算 |
| 说明 | 数据源层面的计算 | 特别语法:处理在一个视图中,涉及到多个详细级别数据的问题 | 对数据返回的聚合结果的二次聚合 |
| 计算结果 | 行级别基本计算:非聚合,每行返回一个值。比如split函数、if逻辑计算等。 视图级别基本计算:聚合,更具视图详细级别返回聚合值,比如count计数计算,sum求和计算。 | 返回的结果是一个数组,构成一个维度fixed或度量 | 根据分区和寻址,返回多个值 |
| 与数据源的关系 | 在数据源层面计算,生成一个新字段 | 在数据源层面计算,生成一个新字段,但在视图层面才有意义 | 与数据源无关,是对视图聚合的二次聚合 |
| 与视图详细级别的关系 | 颗粒度高于视图详细级别 | 颗粒度可以高于视图详细级别include,也可以低于exclude,或者指定详细级别fixed | 优先级在视图之后,聚合度高于视图级别 |
| 优势 | 多种方式可选,逻辑计算,字符串计算,日期函数,类型转换,聚合函数 | 更好的操控数据的颗粒度 | 无需编程,使用常见的表计算 |
五、案例——示例超市数据
问题1:顾客复购率矩阵分析:各个季度的新客户,在接下来的第1、第2、第3、第N季度的复购率分别是多少?
问题2:客户生命周期区间的分析: 对于某个月份的100名获客样本而言,复购率60%就意味着有40%的群体短暂流失或者沉睡了,当然,这个流失/沉睡是相对于单月而言,也可能间隔两个月再次消费。这就是 为什么老客户在前期复购率低,而在后期复购率反而提高——有效的会员政策和营销策略的目的,即在于激活会员的有效复购,让沉睡的会员苏醒重新加入活跃群体。来自客户的几个问题,如下:
1、在过去的一年中有多少客户购买间隔少于3个月、3~ 6个月、6~ 9个月、9~12个月和超过12M个月的?(典型的分布分析,分布区间为客户生命周期经度区间)
2、前30%绩效客户和后30%绩效客户;
3、按地区、部门或省份进行客户绩效分析
1、问题分析
按照此前问题解析的方法,这个问题是典型的高级分析——同时包含了两个层次。何为高级分析?在问题的筛选器、问题层次和聚合度量中,只有有一个位置包含了另一个层次的聚合。 高级的高级分析甚至会同时在多个位置引用其他层次的聚合。日期以连续的季度为层次聚合,统称之为“获客季度”。
1.1 单一层次:每个季度的客户数量
主视图:运用的是视图计算

1.2 在主视图的基础上,增加客户所在矩阵
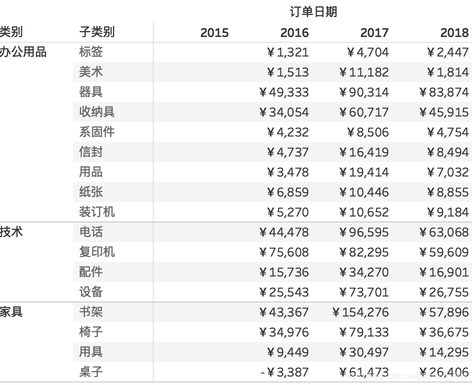
通俗来讲,就是将总客户量划分为2018年新客户/2019年下单新客户/2020年下单新客户/2021年下单新客户。
视图的维度是“季度”(层次是客户,聚合是sum客户名称),我们要引用“每个客户的首次订单所在的季度”(层次是客户,聚合是min订单日期),很明显二者是独立的层次,因此使用fixed lod计算返回每位客户的首次订单日期以识别客户为哪年的新客户。之后将这个字段加入到视图中,作为颜色。这样就是“客户不同获客季度矩阵,在接下来各个订单日期季度消费的客户数量”。

蓝色的线:首次下单日期在2018年的客户群,在未来几年的下单数量
这样,我们可以说包含了问题分析需要的两个维度(订单日期季度和客户首次订单日期),以及需要的聚合度量(客户数量)。接下来的关键是调整视图并完成计算。
2、构建基本的矩阵

但数据太多,折线反而显得混乱,我们可以尝试使用数字构建的矩阵代替。构建矩阵需要把日期改成离散,可以使用智能推荐调整。

这样,我们就有了数据的雏形了,不过复购率还为时尚早,这里有三个问题:
a、矩阵中仅有每个订单日期季度的消费客户数量,却没有每个“获客季度”的客户数量总和。
b、矩阵中的数据,仅仅在每一行上有意义,不同获客季度的客户数量不同,因此相互之间的比较没有意义,因此需要借助每个获客季度的客户数量总和,计算每个消费日期季度的比率(相当于获客季度的确定性样本)。
c、每个获客季度的时间不同,接下来的消费日期季度显然也不同。如何比较2019Q3的获客客户和2020Q2的获客客户,分别在接下来的四个季度的复购率,才是关键。
3、增加更高层次的聚合——每个“获客季度”的客户数量
问题a就是要找到每个获客季度的客户数量,这个数据是可以由不同消费日期的客户数量,通过不重复的计算countd获得。获客季度的客户数量,层次高于当前视图。
total( countd([客户名称]))
不过,直接在视图中添加这个计算后,由于度量默认聚合,聚合生成坐标轴,因此矩阵中增加了坐标轴。此时需要字段上右键改为“离散”,此时依然不对,因为计算的分区错误。还需要配合设置计算依据为:订单日期季度

这样,视图中就有了统一的比较依据。 这里增加一个简单的步骤,计算复购率,就是每个矩阵中的客户计数,除以对应获客季度的客户计数,即:
计算复购率=每个矩阵中客户计数/对应获客季度的总客户计数
countd([客户名称]) / total( countd([客户名称]))

至此,复购率的计算就完成了,由于这里使用的是每个客户名称的首次订单日期,因此第一个季度自然是100%。在业务环境中,销售人员的成交通常晚于入职时间,因此首月的转化可以视为客户消费能力和培训效果的指标。
这里最后面临一个问题,虽然可以直观的查看每个获客季度在此后各个季度的复购率,但无法直观的纵向比较。这就涉及到如何把绝对的日期轴,通过处理更改为相对的日期轴。
4、通过表计算更改坐标轴——公共基准的日期
如何将绝对日期改为相对日期?即相对于每个获客季度的第1、 第2、第3……呢?只是日期的次序转化,首先考虑使用Tableau表计算的index函数。
直接在订单日期后输入index(),数值默认生成连续的坐标轴, 这里还需要改为离散,如下图。

这里的index是基于所有日期的基准,我们希望仅保留基准 index,而不再显示订单日期本身。注意,只是不显示,不能移除,因为订单日期字段是index字段的依据。可以把它拖到左侧标记的“详细信息”中。

此时进入了最重要的一步——如何设置表计算的依据。默认的 index只有1,因为它默认采用的相对分区方法(表、区、单元格)无法识别标记中的字段。这里,每个获客日期为独立的分 区,index的依据是订单日期——第一个月就是绝对日期的相对坐标而已。因此设置index表计算的计算依据为:订单日期。如下:

公共基准的获客季度客户复购。这样,就几近完美了。
接下来,可以调整一下颜色,比如识别复购率大于20%的矩阵;也可以隐藏第一个季度(受限于这里的方法,第一个季度都是100%,影响了其他复购率的显示)。

这样,我们就可以清楚地看到每个获客季度在此后各个季度的复购率情况(在这个季度有消费即为复购)。通过2018年第一 季度的指标可以看出,起初几个季度的复购并不高,但是到了后面几个季度,复购反而提高了,这说明老客户的购买能力比较好。这也和客户的首次矩阵相对应。
问题2:客户生命周期区间的分析: 对于某个月份的100名获客样本而言,复购率60%就意味着有40%的群体短暂流失或者沉睡了,当然,这个流失/沉睡是相对于单月而言,也可能间隔两个月再次消费。这就是 为什么老客户在前期复购率低,而在后期复购率反而提高——有效的会员政策和营销策略的目的,即在于激活会员的有效复购,让沉睡的会员苏醒重新加入活跃群体。来自客户的几个问题,如下:
1、在过去的一年中有多少客户购买间隔少于3个月、3~ 6个月、6~ 9个月、9~12个月和超过12M个月的?(典型的分布分析,分布区间为客户生命周期经度区间)
2、前30%绩效客户和后30%绩效客户
3、按地区、部门或省份进行客户绩效分析

客户矩阵分布。对于客户生命周期区间的分析: 对于某个月份的100名获客样本而言,复购率60%就意味着有40%的群体短暂流失或者沉睡了,当然,这个流失/沉睡是相对于单月而言,也可能间隔两个月再次消费。这就是为什么老客户在前期复购率低,而在后期复购率反而提高——有效的会员政策和营销策略的目的,即在于激活会员的有效复购,让沉睡的会员苏醒重新加入活跃群体。
1、先看第一个问题,不同客户生命周期区间的分布。
视图中是对客户的计数,而生命周期来自客户层次的计算,因此这里使用fixed lod在客户层次计算每个客户的生命周期,生命周期又依赖于每个客户的首次订单日期和最后一次订单日期。
L生命周期 = datediff('month', {FIXED [客户名称]:MIN([订单日期])},
{FIXED [客户名称]:MAX([订单日期])})L生命周期_区间=IF [L生命周期 ]<=3 THEN '<=3'
ELSEIF [L生命周期 ] <=6 THEN '3~=6'
ELSEIF [L生命周期 ] <=9 THEN '6~=9'
ELSEIF [L生命周期 ] <=12 THEN '9~=12'
ELSE '>12'
END
a、如果是看2021年的客户情况,首先可以针对每个月的样本做不同的客户数量或者转化率。为什么,因为10月份的新客户都在“小于3个月”的阶段,不是这些客户不努力,而是时间未到,越近的时间范围,就越缺少准确性和样本意义。 如果把每个月份的客户分开计算,就避免了相互干扰。

这里的生命周期区间,类似于此前的“第1个月、第2个月、第 N个月的复购”的公共基准。
我们发现,老客户在一年以上的复购率非常高。 不过,有什么问题吗? 复购率明显与分析的样本有关,如果一次看三年的数据,超过 12个月的客户就会很多,因此可以尝试增加分析样本。比如只看2020年的新客户——注意,这里应该以首次订单日期为筛选条件,而非订单日期。

2020年的新客户的购买,可能发生在接下来的两年中,这样即便是2020年12 月的新客户,也有可能成为“大于12个月”的生命周期区间。因此分析就比较客观。可见,小于3个月就流失的客户比例比较低,老客户的稳定性比较高。3 到6,6到9的客户区间有时候竟然为0,也就是客户成长阶段在初期就决定了, 中途下车的情况比较少。










![[BigData]16家大数据分析平台](http://www.dratio.com/files/image2/201402/251053065183.jpg)

