当下韵律建模存在的问题:
1 提取的基音pitch信息存在误差,导致韵律合成出现问题
2 对韵律生成的相关要素 如基频 时长 能量等相互依存(dependent on each other)
共同产生了韵律相关的特征
3 韵律信息较高的可变性和高质量数据数目较少 导致不能完全学习韵律相关特征(can not fully shaped)
为了解决这些问题,本文提出了ProsoSeech,使用在大规模未配对和低质量文本和语音数据上预训练的量化潜在向量来增强韵律。
具体来说,我们首先介绍了一种词级(word level)韵律编码器,对语音的低频段(quantizes the low-frequency band)进行量化,并在潜在韵律向量(LPV)中压缩韵律属性。
然后引入了一个LPV预测器,用于预测给定单词序列的LPV。
大规模文本和低质量语音数据上预训练LPV预测器,在高质量TTS数据集上对其进行微调。
最后,我们的模型可以根据预测的LPV为条件生成表达性语音。
实验结果表明,与基线方法相比,ProsoSpeech可以产生更丰富的韵律。
Introduction
近年来,基于神经网络的文本到语音(text-to-speech, TTS)技术受到了广泛的关注[Taco1/2 deepVoice3]。由于非自回归模型[Fastspeech1/2]和强大的生成模型[6,7,8,9]的发展,现代TTS的音频质量和推理速度都有了很大的提高。然而,合成类人的表达语言仍然是一个具有挑战性的任务。
为了生成表达性语音,基于参考编码器的方法[10,11,12,13]使用类自动编码器结构学习潜在解纠缠表示,并成功分解说话人身份和韵律;基于韵律预测的方法[5,14]首先提取包括音高、音长和能量等韵律属性,并根据输入的语言特征(linguistic features)使用一些模块进行预测。
然而,以往的韵律建模方法存在以下几个问题:
1)有些工作使用外部工具提取音高轮廓。然而,提取的基音有不可避免的误差,如v/uv判定误差和不准确的F0值。这些误差不仅降低了音高预测的性能,而且影响了以提取的音高为条件的TTS模型的优化,从而给韵律建模带来了一定的损失。
2)有些工作从语音中提取韵律属性(如音高、持续时间和能量)并分别建模。然而,这些韵律属性相互依存,共同产生了自然的韵律。分别建模可能会破坏它们之间的关系,导致不自然的韵律。
3)韵律具有很高的可变性,每个人和每个词都有差异。使用有限的高质量TTS数据很难塑造韵律的完整分布。
为了解决这些问题,本文提出了ProsoSpeech,利用量化潜向量在大规模未配对和低质量的文本和语音数据上预先训练来增强韵律。
基于FastSpeech,我们的ProsoSpeech包括以下设计:
1)为了避免音高提取过程中出现的错误,并考虑到韵律属性的依赖性,我们引入了一种词级韵律编码器,将韵律从语音中分离出来,该编码器根据词边界将语音的低频带量化为词级量化潜韵律向量(LPV)。为了稳定矢量量化的训练过程,避免索引崩溃,我们进一步设计了一种基于k均值聚类的码本初始化的热身策略。
2)由于我们可以在给定的语音样本中提取韵律表示,我们提出了一种自回归的LPV预测器来预测词级文本序列条件下的LPV,从而对韵律进行建模。
3)为了更好地塑造韵律分布,我们在大规模文本数据和低质量语音数据集上对LPV预测器进行预训练,并在高质量的TTS数据集上对其进行微调,最后,以预测的LPV为条件,生成表达性语音。
我们在一个高质量的中文TTS数据集上进行实验,并在大规模文本语料库和低质量语音数据集上进行LPV预测器的预训练。结果表明,与现有的TTS方法相比,ProsoSpeech能够生成更自然的语音,韵律更丰富,音频质量更好。我们还进行了充分的消融研究,以证明每种设计的有效性。
2 Our Method
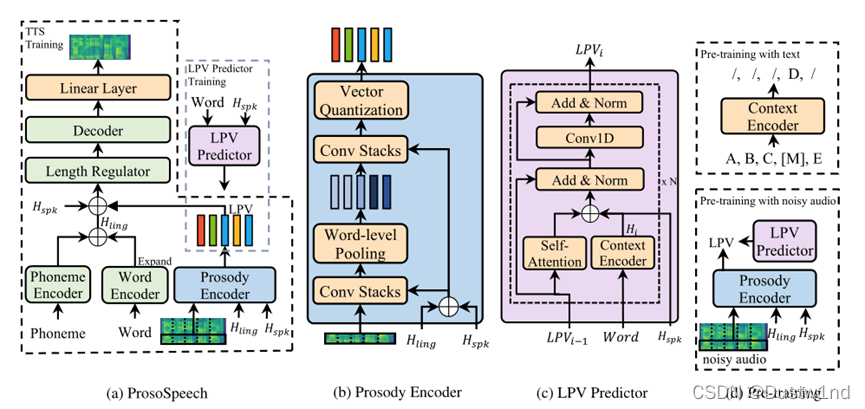
在本节中,我们将介绍我们提出的ProsoSpeech模型。如图1a所示,ProsoSpeech基于FastSpeech,并引入了一些模块来进一步建模语音的表达性,包括词编码器、韵律编码器和自回归潜在韵律向量(LPV)预测器。在训练过程中,将输入的文本序列转换为音素序列和单词序列,音素和单词编码器将音素序列和单词序列编码成语言特征。然后利用基于语言特征的韵律编码器,将ground-truth韵律谱图的低频部分编码为量化的潜韵律向量(LPV)。
最后,我们将语言特征和LPV一起输入到解码器中以生成预测的mell -谱图,并使用均方误差(MSE)和相似度指标度量(SSIM)[15]损失优化模型。到目前为止,我们将从语音中解纠缠,得到了韵律解纠缠表示(韵律解纠缠表征)。为了预测LPV序列,我们训练了一个以词序列为条件的自回归LPV预测器。
((SSIM-结构相似性,是一种衡量两幅图像相似度的指标,也是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性))
此外,我们采用大规模的文本和音频语料库对LPV预测器进行预训练,以更好地理解文本上下文和塑造韵律分布。在推理中,由于我们没有地面真实的mel谱图作为参考,我们使用LPV预测器来预测LPV并产生表达性语音。在下面的小节中,我们将详细介绍每个模块
2.1. Prosody Encoder
韵律编码器的目的是利用词级矢量量化瓶颈将韵律从语音中分离出来。如图1b所示,韵律编码器由两层组成,每一层都是由ReLU激活和层归一化的卷积层叠加而成。第一层根据词边界将谱图压缩为词级隐藏状态,第二层对词级隐藏状态进行后处理。最后将这些隐藏状态输入到基于EMA^2的矢量量化层[16],得到词级LPV序列。由于语音中的音色(说话人身份)和内容分别由说话人嵌入和语言编码器(音素/词编码器)提供,由于矢量量化瓶颈(vector quantization bottleneck.),LPV只包含与说话人和内容无关的韵律信息。
此外,我们只选取mel-谱图的低频波段(每帧mel-谱图的前20个bins)作为输入,以减轻解纠缠的困难,因为它包含了几乎完整的韵律,音色/内容信息比全波段少得多
然而,韵律编码器需要经过数千步的训练才能真正从词级韵律谱图片段中提取韵律信息。因此,在训练初始阶段,矢量量化前的隐藏状态可能是非常嘈杂和无意义的。在这种情况下,我们发现我们的韵律编码器倾向于索引崩溃[17],这意味着一些嵌入向量接近大量的编码器输出,模型只使用来自e的有限数量的向量。索引崩溃严重限制了我们的韵律编码器的表达能力。
针对这一问题,我们提出了一种热身策略和基于k-means聚类的质心初始化:
- 在前20k步中去除矢量量化层,使韵律编码器自由提取韵律信息,不存在瓶颈;
- 在前20k步后,用k-means聚类中心初始化矢量量化层的码本(codebook);
- 初始化后,加入矢量量化层作为后期训练的韵律瓶颈。
2.2. Latent Prosody Vector Predictor
现在,我们已经能够使用韵律编码器提取韵律表示,我们可以通过建模LPV序列来建模韵律。如图1c所示,LPV predictor使用文本输入来预测词级LPV序列,该序列采用基于自我注意的[18]自回归结构。由于LPV序列与词序列具有相同的长度,我们使用单词级上下文特征作为条件,该条件由LPV预测器中的上下文编码器进行编码。LPV预测器在训练阶段采用教师强迫模式进行训练,并在推理中对LPV进行自回归预测
2.3. Pre-training and Fine-tuning
虽然韵律表征可以用LPV预测器建模,但可能不够精确,原因如下: - TTS数据集中的文本训练数据不够大(约10k个句子),导致上下文编码器对上下文的理解能力较差,难以捕捉韵律与文本之间的联系。
2)语音/韵律训练数据不够大,使得样本在韵律空间中有些稀疏,导致韵律分布估计不准确。
因此,我们提出了一种使用附加纯文本数据和低质量语音数据的预训练方法,如图1d所示。对于文本的预训练,LPV预测器中的上下文编码器采用类BERT[19]掩码预测方式进行训练,其掩码概率为0.15。对于低质量音频的预训练,利用带噪声音频编码的LPV序列对LPV预测器进行预训练。在这些预训练过程之后,我们对高质量的TTS数据集上的LPV预测器进行了微调.
因此,我们最终的训练流程依次包括
TTS训练(包括韵律编码器和FastSpeech主体)、
未配对文本的预训练上下文编码器、
低质量语音的预训练LPV预测器
高质量TTS数据的LPV预测器Fine turn。
3. EXPERIMENTS
3.1. Experimental Setup
我们在一个内部的普通话数据集上评估ProsoSpeech,该数据集包含62,586个普通话音频剪辑(约30小时)和相应的文本文本。我们将我们的TTS数据集分成三个子集:61,000个样本用于训练,586个样本用于验证,1,000个样本用于测试。
我们在测试集中随机选取50个样本进行主观评价。我们使用开源的python-pinyin工具将文本序列转换为音素序列[20,1,2,21,4]。我们将采样率为22050的原始波形转换为帧大小为1024,跳大小为256的mel-波谱图[2,4]。对于未配对的文本数据,我们从互联网上抓取了5100万个中文句子。对于低质量的音频数据,我们使用一个内部的中国ASR数据集,其中包含大约300小时的音频剪辑。使用resemblyzer提取说话人嵌入。
1)音素编码器、词编码器和解码器均采用FastSpeech[4]中提出的Transformer,其层数4、隐藏大小192、内核大小5和过滤器大小384。使用全连接层将预训练的说话人嵌入被投影到192。
2)韵律编码器卷积堆栈5层,包含了1D卷积、ReLU和层归一化。
3)矢量量化层的码本codebook的默认大小设置为128。
4)自回归LPV预测器包含3个Transformer层,上下文编码器包含6个Transformer层,其中隐藏大小为384,内核大小为5,滤波器大小为384。上下文编码器在所有LPV预测器层之间共享。
利用预先训练好的HiFi-GAN将模型输出的mel-谱图转换为音频样本。我们对测试集进行MOS (mean opinion score)评估,以衡量音频质量。我们在不同的模型之间保持文本内容的一致性,排除其他干扰因素,只检查音频质量或韵律。每个音频至少由20名测试者收听,他们都是英语母语人士。他们被告知在安静的室内环境中用耳机听所有的样本,音量应至少75%,以使他们能够分辨所有音频样本的细节。
衡量韵律的客观评测指标
Average pitch dynamic time warping distance D_Pit
Duration KL-divergence 〖KL〗_duration


3.2. Performance
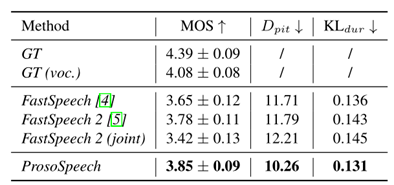
我们将ProsoSpeech生成的音频样本与其他系统的音频质量和韵律进行比较,包括
1)GT, ground truth音频;
2) GT (voc.),首先将ground truth-> mel-spectrogram->HiFi-GAN->音频
3) FastSpeech;
4) FastSpeech 2
5)FastSpeech 2 (joint):使用联合TTS和ASR数据集训练FastSpeech 2
我们有以下观察:
1)在音频质量方面,ProsoSpeech在MOS方面优于以往的TTS模型,这表明了我们提出的方法的优越性。
2)在音高精度方面,与以往方法相比,ProsoSpeech生成的音频Dpit小于其他方法,表明ProsoSpeech具有强大而高效的韵律建模能力。
3)在持续时间精度方面,与以往方法相比,ProsoSpeech预测的持续时间在KL_dur的分布水平上更接近ground-truth持续时间,说明ProsoSpeech能够更好地对持续时间分布进行建模。
4)与FastSpeech 2 (joint)相比,ProsoSpeech也取得了更好的性能,这说明我们的韵律编码器进行韵律提取对于后期低质量数据的前训练是必要的。
我们还发现FastSpeech 2 (joint)的性能比FastSpeech 2差,这表明如果我们直接用附加的低质量语音对TTS模型进行预训练,会干扰模型的训练,甚至导致质量更差。
3.3. Ablation Study and Analyses
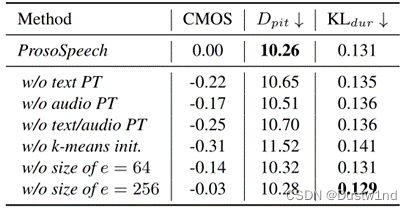
我们对ProsoSpeech的k-means初始化、文本预训练和音频预训练进行了研究,并探讨了韵律编码器中合适的码本大小。我们对这些消融研究进行CMOS评估。结果如表2所示。从表中我们可以看出:
1)从第2行到第4行,文本和语音的预训练都可以提高音高和时长的准确性,它们可以相互配合,进一步提高韵律;
2)从第5行开始,韵律编码器中的k-means初始化可以提高韵律,稳定训练;
3)在第6行和第7行中,代码本的默认大小(128)对于我们的设置中的韵律建模来说已经足够了,如果我们使用更小的代码本,性能可能会降低
4. CONCLUSION
在本文中,我们提出了ProsoSpeech,利用量化的潜向量来增强韵律,这些潜向量是在大规模文本和带噪语音数据上预先训练的。
为了将所有的韵律属性整合到一起,我们首先引入了一个词级韵律编码器,该编码器将语音的词级韵律量化,并将所有的韵律属性压缩到量化的潜在韵律向量( LPV)中。
然后,我们提出了一种LPV预测器来预测给定字级文本序列的LPV。
为了更好地塑造复杂的韵律空间分布,我们在大规模文本数据和低质量语音数据集上对LPV预测器进行预训练,并在高质量的TTS数据集上对其进行微调。
实验结果证明了该方法及各设计方案的有效性。
未来,我们将引入更强大的生成模型来提高语音的音频质量。我们也可以利用较长的上下文信息,如段落级上下文或对话级上下文,以进一步提高语音韵律