一、参考文章
https://www.cnblogs.com/datiangou/p/10245874.html
https://www.cnblogs.com/jason1990/archive/2019/10/24/11732261.html
二、常用垃圾回收器

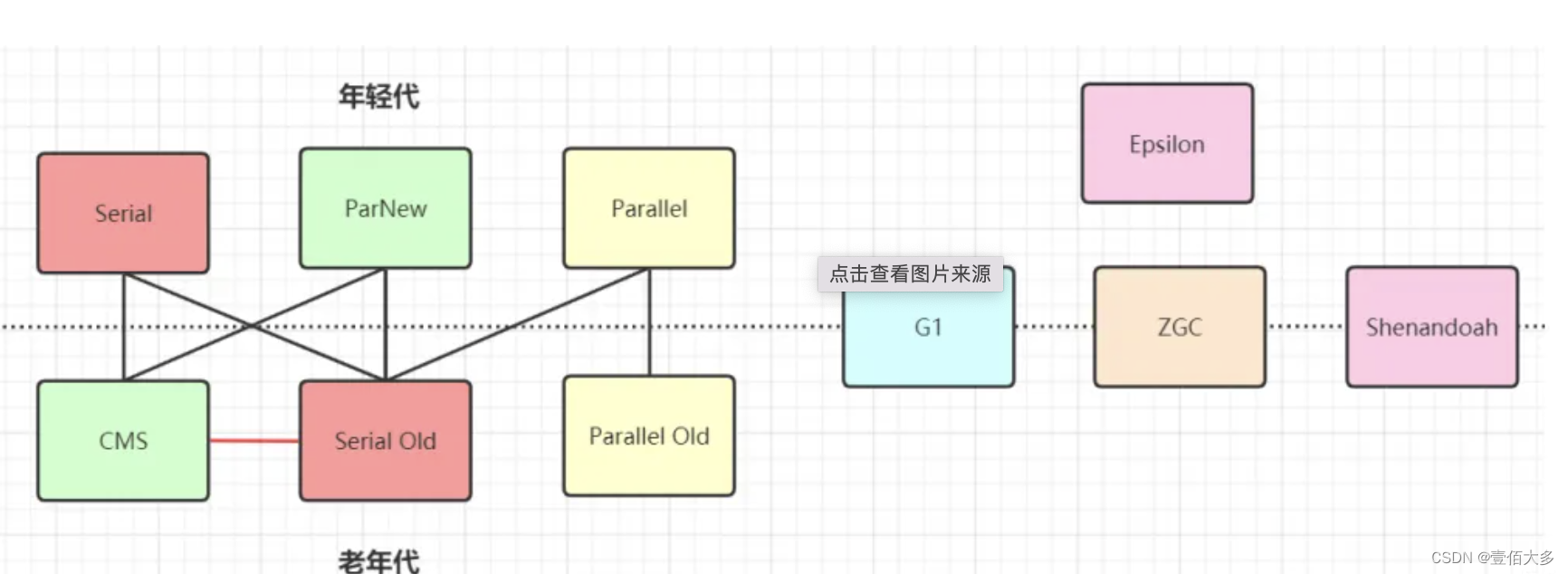
1. JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS
并发垃圾回收是因为无法忍受STW
2. Serial 年轻代 串行回收
Serial收集器(Serial + Serial Old)的主要特点是单线程回收资源。当需要执行垃圾回收时,程序会暂停一切工作(又称为Stop The World,STW),使用复制算法完成垃圾清理工作。
优点:
- 简单高效,是Client模式下默认的垃圾收集器;
- 对于资源受限的环境,比如单核(例如Docker中设置单核),单线程效率较高;
- 内存小于一两百兆的桌面程序中,交互有限,则有限的STW是可以接受的。
缺点:
- 垃圾回收速度较慢且回收能力有限,频繁的STW会导致较差的使用体验。
3. PS(Parallel Scavenge收集器) 年轻代 并行回收
新生代的收集器,同样用的是复制算法,也是并行多线程收集。与ParNew最大的不同,它关注的是垃圾回收的吞吐量。
这里的吞吐量指的是 总时间与垃圾回收时间的比例。这个比例越高,证明垃圾回收占整个程序运行的比例越小。
Parallel Scavenge收集器提供两个参数控制垃圾回收的执行:
- -XX:MaxGCPauseMillis,最大垃圾回收停顿时间。这个参数的原理是空间换时间,收集器会控制新生代的区域大小,从而尽可能保证回收少于这个最大停顿时间。简单的说就是回收的区域越小,那么耗费的时间也越小。
所以这个参数并不是设置得越小越好。设太小的话,新生代空间会太小,从而更频繁的触发GC。 - -XX:GCTimeRatio,垃圾回收时间与总时间占比。这个是吞吐量的倒数,原理和MaxGCPauseMillis相同。
因为Parallel Scavenge收集器关注的是吞吐量,所以当设置好以上参数的时候,同时不想设置各个区域大小(新生代,老年代等)。可以开启**-XX:UseAdaptiveSizePolicy**参数,让JVM监控收集的性能,动态调整这些区域大小参数。
4. ParNew 年轻代 配合CMS的并行回收
ParNew同样用于新生代,是Serial的多线程版本,并且在参数、算法(同样是复制算法)上也完全和Serial相同。
Par是Parallel的缩写,但它的并行仅仅指的是收集多线程并行,并不是收集和原程序可以并行进行。ParNew也是需要暂停程序一切的工作,然后多线程执行垃圾回收。
因为是多线程执行,所以在多CPU下,ParNew效果通常会比Serial好。但如果是单CPU则会因为线程的切换,性能反而更差。
5. SerialOld
老年代的收集器,与Serial一样是单线程,不同的是算法用的是标记-整理(Mark-Compact)。
因为老年代里面对象的存活率高,如果依旧是用复制算法,需要复制的内容较多,性能较差。并且在极端情况下,当存活为100%时,没有办法用复制算法。所以需要用Mark-Compact,以有效地避免这些问题。
6. ParallelOld
7. ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms)
CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定
CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收
想象一下:
PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW)
几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC
算法:三色标记 + Incremental Update
CMS,Concurrent Mark Sweep,同样是老年代的收集器。它关注的是垃圾回收最短的停顿时间(低停顿),在老年代并不频繁GC的场景下,是比较适用的。
命名中用的是concurrent,而不是parallel,说明这个收集器是有与工作执行并发的能力的。MS则说明算法用的是Mark Sweep算法。
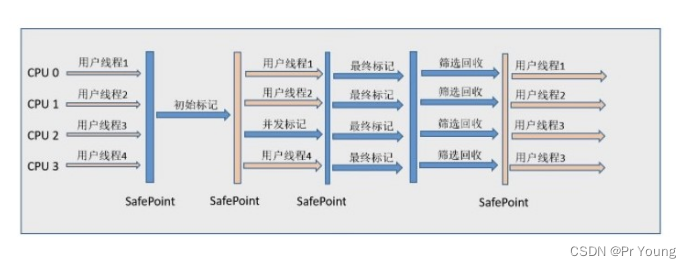
来看看具体地工作原理。CMS整个过程比之前的收集器要复杂,整个过程分为四步:
- 初始标记(initial mark),单线程执行,需要“Stop The World”,但仅仅把GC Roots的直接关联可达的对象给标记一下,由于直接关联对象比较小,所以这里的速度非常快。
- 并发标记(concurrent mark),对于初始标记过程所标记的初始标记对象,进行并发追踪标记,此时其他线程仍可以继续工作。此处时间较长,但不停顿。
- 重新标记(remark),在并发标记的过程中,由于可能还会产生新的垃圾,所以此时需要重新标记新产生的垃圾。此处执行并行标记,与用户线程不并发,所以依然是“Stop The World”,时间比初始时间要长一点。
- 并发清除(concurrent sweep),并发清除之前所标记的垃圾。其他用户线程仍可以工作,不需要停顿。
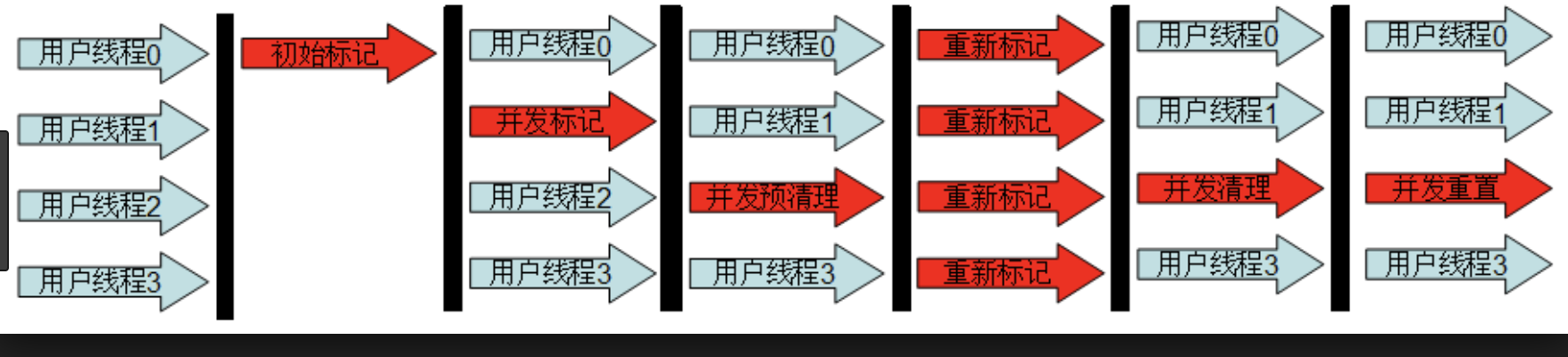
由于最耗费时间的并发标记与并发清除阶段都不需要暂停工作,所以整体的回收是低停顿的。
由于CMS以上特性,缺点也是比较明显的,
- Mark Sweep算法会导致内存碎片比较多
- CMS的并发能力依赖于CPU资源,所以在CPU数少和CPU资源紧张的情况下,性能较差
- 并发清除阶段,用户线程依然在运行,所以依然会产生新的垃圾,此阶段的垃圾并不会再本次GC中回收,而放到下次。所以GC不能等待内存耗尽的时候才进行GC,这样的话会导致并发清除的时候,用户线程可以了利用的空间不足。所以这里会浪费一些内存空间给用户线程预留。
有人会觉得既然Mark Sweep会造成内存碎片,那么为什么不把算法换成Mark Compact呢?
答案其实很简答,因为当并发清除的时候,用Compact整理内存的话,原来的用户线程使用的内存还怎么用呢?要保证用户线程能继续执行,前提的它运行的资源不受影响嘛。Mark Compact更适合“Stop the World”这种场景下使用。
8. G1(10ms)
算法:三色标记 + SATB
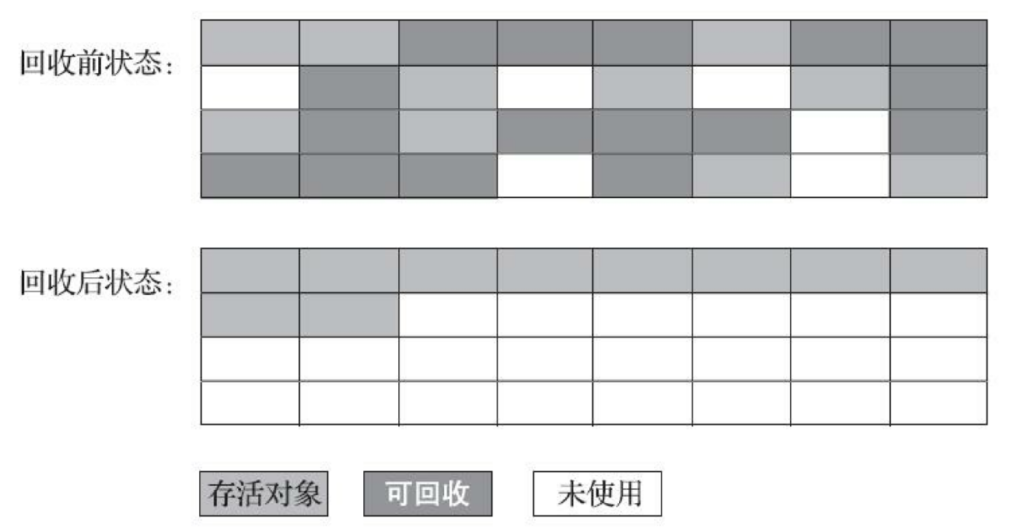
G1将内存划分为多个大小相同的Region(1-32M,上限2048个),每个Region均拥有自己的分代属性,这些分代不需要连续。通过划分Region,G1可以根据计算老年代对象的效益率,优先回收具有最高效益率的对象(分代的内存不连续,GC搜索垃圾时需要全盘扫描找出对象引用情况,G1通过在每个Region中维护一个Remembered Set记录对象引用情况解决此问题)。具体如下图所示:
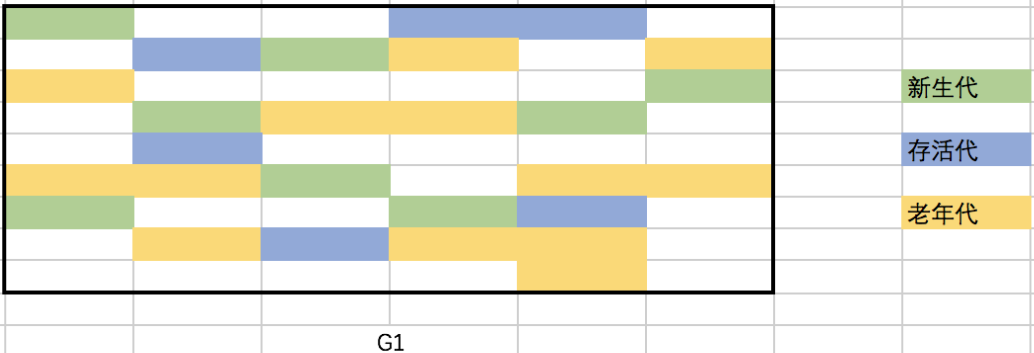
G1提供了两种GC模式,Young GC以及Mixed GC,两种GC都会STW。
两种GC模式:
- Young GC,关注于所有年轻代的Region,通过控制收集年轻代的Region个数,从而控制GC的回收时间。
- Mixed GC,关注于所有年轻代的Region,并且加上通过预测计算最大收益的若干个老年代Region。
整体的执行流程:
- 初始标记(initial mark),标记了从GC Root开始直接关联可达的对象。STW(Stop the World)执行。
- 并发标记(concurrent marking),并发标记初始标记的对象,此时用户线程依然可以执行。
- 最终标记(Remark),STW,标记再并发标记过程中产生的垃圾。
- 筛选回收(Live Data Counting And Evacuation),评估标记垃圾,根据GC模式回收垃圾。STW执行。
9. ZGC (1ms) PK C++
算法:ColoredPointers + LoadBarrier
在JDK 11当中,加入了实验性质的ZGC。它的回收耗时平均不到2毫秒。它是一款低停顿高并发的收集器。
ZGC几乎在所有地方并发执行的,除了初始标记的是STW的。所以停顿时间几乎就耗费在初始标记上,这部分的实际是非常少的。那么其他阶段是怎么做到可以并发执行的呢?
ZGC主要新增了两项技术,一个是着色指针Colored Pointer,另一个是读屏障Load Barrier。
着色指针Colored Pointer
ZGC利用指针的64位中的几位表示Finalizable、Remapped、Marked1、Marked0(ZGC仅支持64位平台),以标记该指向内存的存储状态。相当于在对象的指针上标注了对象的信息。注意,这里的指针相当于Java术语当中的引用。
在这个被指向的内存发生变化的时候(内存在Compact被移动时),颜色就会发生变化。
在G1的时候就说到过,Compact阶段是需要STW,否则会影响用户线程执行。那么怎么解决这个问题呢?
读屏障Load Barrier 由于着色指针的存在,在程序运行时访问对象的时候,可以轻易知道对象在内存的存储状态(通过指针访问对象),若请求读的内存在被着色了。那么则会触发读屏障。读屏障会更新指针再返回结果,此过程有一定的耗费,从而达到与用户线程并发的效果。
把这两项技术联合下理解,引用R大(RednaxelaFX)的话
与标记对象的传统算法相比,ZGC在指针上做标记,在访问指针时加入Load Barrier(读屏障),比如当对象正被GC移动,指针上的颜色就会不对,这个屏障就会先把指针更新为有效地址再返回,也就是,永远只有单个对象读取时有概率被减速,而不存在为了保持应用与GC一致而粗暴整体的Stop The World。
ZGC虽然目前还在JDK 11还在实验阶段,但由于算法与思想是一个非常大的提升,相信在未来不久会成为主流的GC收集器使用。
10. Shenandoah
算法:ColoredPointers + WriteBarrier
11. Eplison
12. PS 和 PN区别的延伸阅读:
▪[https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73](https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html)
13. 垃圾收集器跟内存大小的关系
1. Serial 几十兆
2. PS 上百兆 - 几个G
3. CMS - 20G
4. G1 - 上百G
5. ZGC - 4T - 16T(JDK13)
1.8默认的垃圾回收:PS + ParallelOld
小编也有自己微信公众号:“JAVA菜鸟程序猿”,喜欢的可以关注下哦!