结构体分类
结构体的一个显著特点在于,结构体中的数据字段是通过名称访问,而不是像数组那样通过索引访问。不好的是,字段名称被编译器转换成了数字偏移量。结果,在反汇编代码清单中,访问结构体字段的方式看起来与使用常量索引访问数组元素的方式极其相似。
注意的是,结构体中有个内存对齐规则,所以不要认为编译器会利用所需的最小空间来分配结构体。默认情况下,编译器会设法将结构体字段与内存地址对齐,以最有效地读取和写入这些字段
1. 全局分配的结构体
和全局分配的数组一样,编译器在编译时可获知全局分配的结构体的地址。这使得编译器能够在编译时计算出结构体中每个成员的地址,而不必在运行时进行任何计算。
如下代码:
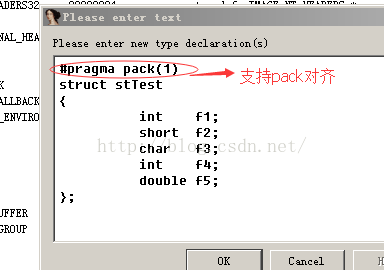
struct stTest
{int f1;short f2;char f3;int f4;double f5;
};
stTest g_st;
void fun()
{g_st.f1 = 10;g_st.f2 = 20;g_st.f3 = 30;g_st.f4 = 40;g_st.f5 = 50.0;
}对应汇编为:可以看到,在这个反汇编代码清单中,访问结构体成员不需要任何算术计算,如果没有源代码,你根本无法断定这个程序使用了结构体。
push ebp
mov ebp, esp
mov dword_403018, 10 ; int f1 = 10
mov eax, 20
mov word_40301C, ax ; word f2 = 20
mov byte_40301E, 30 ; byte f3 = 30
mov dword_403020, 40 ; int f4 = 40
fld ds:dbl_4020E0 ; f5 = dbl_403028 = 50.0
fstp dbl_403028
pop ebp
retn
2. 栈分配的结构体
同样,仅仅根据栈布局,同样很难识别出栈分配的结构体。
void fun()
{stTest l_st;l_st.f1 = 10;l_st.f2 = 20;l_st.f3 = 30;l_st.f4 = 40;l_st.f5 = 50.0;
}对应汇编为:同样,访问结构体中的字段不需要进行任何算术计算,因为在编译时,编译器能够确定栈帧内每个字段的相对偏移量
000 push ebp
004 mov ebp, esp
004 sub esp, 18h
01C mov [ebp+var_18], 10
01C mov eax, 14h
01C mov [ebp+var_14], ax
01C mov [ebp+var_12], 30
01C mov [ebp+var_10], 40
01C fld ds:dbl_4020E0
01C fstp [ebp+var_8]
01C mov esp, ebp
004 pop ebp
000 retn3. 堆分配的结构体
由于结构体的地址在编译时未知,编译器别无选择,只有生成代码来计算每个字段在结构体中的正确偏移量。
如果一个结构体在堆中分配,那么对编译器来说,引用该结构体的唯一线索就是指向该结构体起始地址的指针。
void fun()
{stTest* pst = new stTest;pst->f1 = 10;pst->f2 = 20;pst->f3 = 30;pst->f4 = 40;pst->f5 = 50.0;
}对应汇编为:
push ebp
mov ebp, esp
sub esp, 8
push 24 ; unsigned int
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
mov [ebp+var_8], eax ; eax为pst指针,var_8也是
mov eax, [ebp+var_8]
mov [ebp+var_4], eax
mov ecx, [ebp+var_4] ; ecx = pst
mov dword ptr [ecx], 10 ; (int*)pst = 10
mov edx, 20
mov eax, [ebp+var_4] ; eax = pst
mov [eax+4], dx ; (word*)(pst+4) = 20
mov ecx, [ebp+var_4] ; ecx = pst
mov byte ptr [ecx+6], 30 ; (byte*)(pst+6)=30,验证了第二个是word字节
mov edx, [ebp+var_4] ; edx = pst
mov dword ptr [edx+8], 40 ; (int*)(pst+8) = 40
mov eax, [ebp+var_4] ; eax = pst
fld ds:dbl_4020F0
fstp qword ptr [eax+10h] ; (dq)(pst+16)=50.0
mov esp, ebp
pop ebp
retn4. 结构体数组
void fun()
{stTest* pst = new stTest[2];pst[1].f1 = 10;pst[1].f2 = 20;pst[1].f3 = 30;pst[1].f4 = 40;pst[1].f5 = 50.0;
}反汇编没什么区别:与上面相比,每项加了24
push ebp
mov ebp, esp
sub esp, 8
push 48 ; 48/2 = 24
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
mov [ebp+var_8], eax
mov eax, [ebp+var_8]
mov [ebp+var_4], eax
mov ecx, [ebp+var_4]
mov dword ptr [ecx+24], 10 ; pst+24,注意+24
mov edx, 20
mov eax, [ebp+var_4]
mov [eax+1Ch], dx
mov ecx, [ebp+var_4]
mov byte ptr [ecx+30], 30 ; pst+24+6
mov edx, [ebp+var_4]
mov dword ptr [edx+32], 40 ; pst+24+8
mov eax, [ebp+var_4]
fld ds:dbl_4020F0
fstp qword ptr [eax+40] ; pst+14+16
mov esp, ebp
pop ebp
retn
创建结构体
IDA之所以在分析阶段无法识别结构体,可能源于两个原因。首先,虽然IDA了解某个结构体的布局,但它并没有足够的信息,能够判断程序确实使用了结构体。其次,程序中的结构体可能是一种IDA对其一无所知的非标准结构体。在这两种情况下,问题都可以得到解决,且首先从Structures窗口下手
1.添加结构体
Structures窗口的前4行文本用于提醒用户该窗口中可能进行的操作。

使用热键INSERT启动
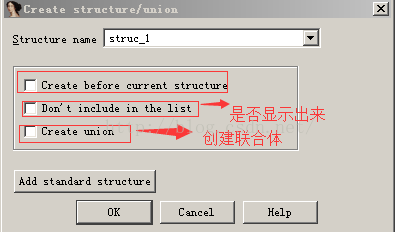
指定结构体的名称并单击OK按钮后,IDA将在Structures窗口中创建一个空结构体定义

2.编辑结构体成员
(1)要给结构体添加新字段,将光标放在结构体定义的最后一行(包含ends的那一行)并按下D键。新字段的大小取决于你在数据转盘上选择的第一个大小

(2)如果需要修改字段的大小,首先将光标放在新字段的名称上,然后重复按下D键,使数据转盘上的数据类型开始循环,从而为新字段选择正确的数据大小。另外,你还可以使用Options▶Setup Data Types来指定一个在数据转盘上不存在的大小。如果新字段是一个数组,右击其名称并在上下文菜单中选择Array
(3)要更改一个结构体字段的名称,单击字段名称并按下N键,或者右击该名称并在上下文菜单中选择ReName,然后在输入框中输入一个名称即可。
以下是帮助说明:
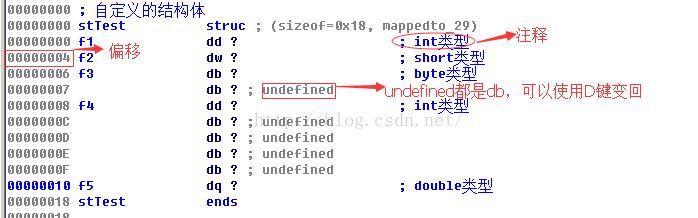
•一个字段的字节偏移量在Structures窗口的左侧显示。
•结构体的新大小会在结构体定义的第一行及时更新出来。
•可以给一个结构体字段添加注释,就像给任何反汇编行添加注释一样。
•只有当一个字段是结构体中的最后一个字段时,使用U键才能删除该字段。对于其他字段,按下U键只是变成undefined,可以通过D键恢复
•IDA并不区分已压缩和未压缩的结构体。为将字段适当对齐,如果你需要填补字节,那么你必须负责添加这些字节。填补字节最好作为适当大小的哑字段添加。在添加额外的字段后,你可以选择取消或保留这些字段的定义。
•分配到结构体中间的字节只有在取消关联字段的定义后(undefined状态),Edit▶Shrink Struct Type(缩小结构体类型)即可删除被取消定义的字节。
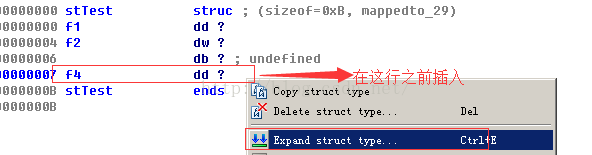
•也可以在结构体的中间添加新的字节:选择新字节后面的一个字段,然后使用Edit▶Expand Struct Type(扩大结构体类型)在选中的字段前插入一定数量的字节。
•如果知道结构体的大小,而不了解它的布局,你需要创建两个字段。第一个字段为一个数组,它的大小为结构体的大小减去1个字节(size-1);第二个字段应为1个字节。创建第二个字段后,取消第一个(数组)字段的定义。这样,结构体的大小被保留下来,随后,当你进一步了解该结构体的布局后,你可以回过头来定义它的字段及其大小。
创建完成后如下:
3.折叠打开结构体
可以选择结构体中的任何字段并按下数字键盘中的减号键,将结构体的定义折叠成一行摘要,双击结构体名称也可以打开该定义。(或ctrl+/ctrl-)
使用结构体模板
1.右击中,可在上下文菜单上看到Structure offset选项:很明确的说明了它可以是stTest.f5+24(pst[1].f5 = 50.0;)
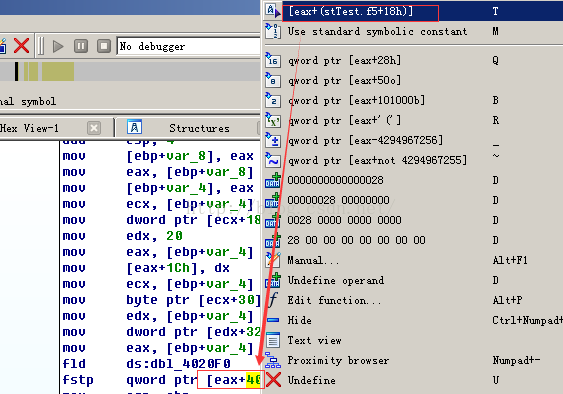
2.另一种方法,可以将栈和全局变量格式化成整个结构体,双击该变量,打开详细栈帧视图,然后使用Edit▶Struct Var(ALT+Q)命令显示一组已知的结构体
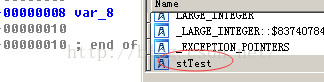
之后上面结构体数组汇编变为:重新格式化之后,IDA认识到,任何对分配给var_8的24个字节块的内存引用,都必须引用该结构体中的一个字段。如果IDA发现这样一个引用,它会尽一切努力,将这个内存引用与结构体变量中的一个已定义的字段关联起来
var_8= stTest ptr -8push ebp
mov ebp, esp
sub esp, 8
push 48 ; unsigned int
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
mov [ebp+var_8.f1], eax
mov eax, [ebp+var_8.f1]
mov dword ptr [ebp+var_8.f2], eax
mov ecx, dword ptr [ebp+var_8.f2]
mov dword ptr [ecx+(size stTest)], 10
mov edx, 20
mov eax, dword ptr [ebp+var_8.f2]
mov [eax+1Ch], dx
mov ecx, dword ptr [ebp+var_8.f2]
mov byte ptr [ecx+30], 30
mov edx, dword ptr [ebp+var_8.f2]
mov [edx+(stTest.f4+18h)], 40
mov eax, dword ptr [ebp+var_8.f2]
fld ds:dbl_4020F0
fstp [eax+(stTest.f5+18h)]
mov esp, ebp
pop ebp
retn将全局变量格式化成结构体的过程与格式化栈变量所使用的过程几乎完全相同
导入新的结构体
在创建新结构体方面,IDA确实提供了一些捷径。IDA能够解析C(而非C++)数据声明,以及整个C头文件,并自动为在这些声明或头文件中定义的结构体创建对应的IDA结构体。如果你碰巧拥有你正进行逆向工程的二进制文件的源代码,或者至少是头文件,那么,你就可以让IDA直接从源代码中提取出相关结构体,从而节省大量时间。
使用View▶Open Subviews▶Local Types(查看▶打开子窗口▶本地类型)命令,可以打开Local Types子窗口,其中列出了所有解析到当前数据库中的类型。
通过INSERT键或上下文菜单中的Insert选项解析:

解析C头文件
要解析头文件,可以使用File▶Load File▶Parse C HeaderFile(文件▶加载文件▶解析C头文件)选择你想要解析的头文件。如果一切正常,IDA会通知你Compilation successful(编译完成)。如果解析器遇到任何问题,IDA将会在输出窗口中显示错误消息
IDA会将所有被成功解析的结构体添加到当前数据库的标准结构体列表中(具体地说,是列表的末尾)。如果新结构体的名称与现有结构体的名称相同,IDA会用新结构体布局覆盖原有结构体定义。除非你明确选择添加新的结构体,否则,新结构体不会出现在Structures窗口中
•默认情况下,解析器会建立4字节对齐的结构体,当然,你可以使用pack改变它
•解析器只能理解C标准数据类型。但是,解析器还能够理解预处理器define指令和C typedef语句。因此,如果解析器之前遇到过适当的typedef,它将能够正确解析unit32_t之类的类型。
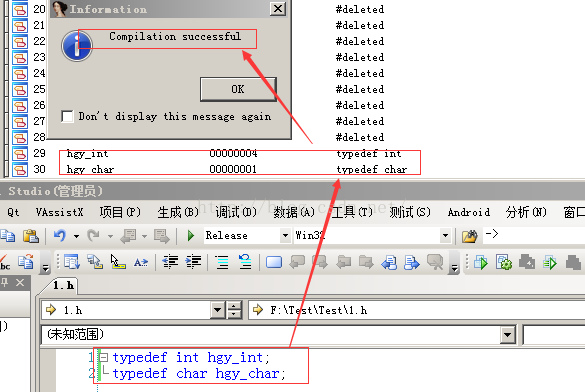
•如果你没有源代码,那么你会发现,使用文本编辑器以C表示法迅速定义一个结构体布局,并解析得到的头文件或把声明粘贴为一个新的本地类型,会比使用IDA烦琐的手动结构体定义工具更加方便。
添加到Local Types(本地类型)窗口中的数据类型不会立即在Structures(结构体)最简单的方法是在类型上单击鼠标右键,并选择Synchronize to idb。
使用标准结构体
IDA能够识别大量与各种库和API函数有关的数据结构。当IDA在反汇编代码清单中操纵结构体时,它会在Structures窗口中添加相应的结构体定义。因此,Structures窗口中显示的是应用于当前二进制文件的已知结构体的子集。除了创建自定义结构体外,你还可以从IDA的已知结构体列表中提取出其他标准结构体,并将其添加到Structures窗口中。
首先,在Structures窗口中按下IN-SERT键。在Create structure/ union对话框中,包含一个Add standard structure(添加标准结构体)按钮。单击这个按钮,IDA将显示与当前编译器(在分析阶段检测出来)和文件格式有关的结构体主列表。这个结构体主列表中还包含通过解析C头文件添加到数据库中的结构体。
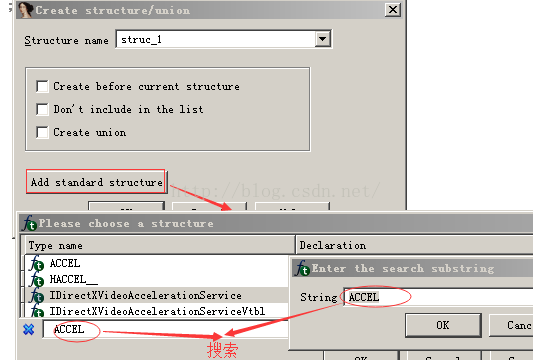
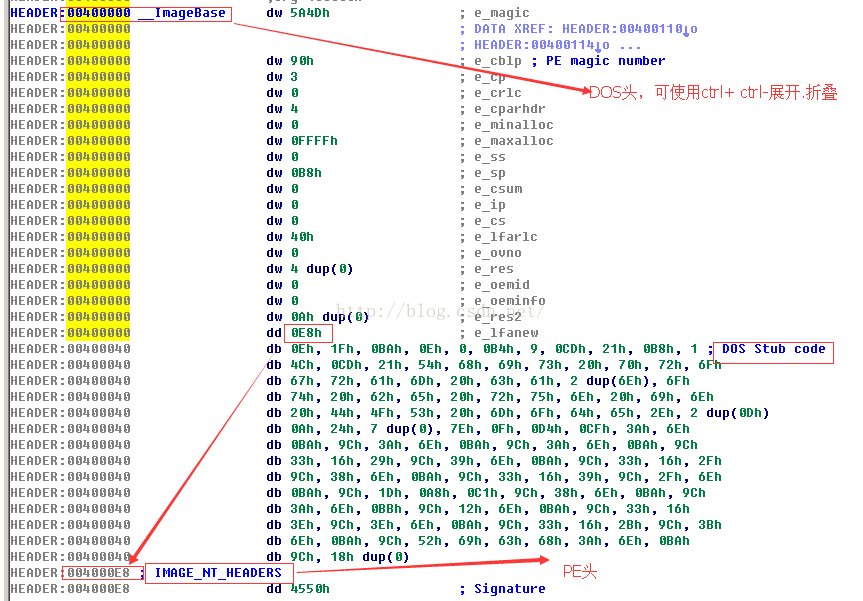
示例:(分析文件头)
默认情况下,在创建后,文件头不会立即加载到数据库中。但是,如果你在最初创建数据库时选择Manual load(手动加载)选项,就可以将文件头加载到数据库中。加载文件头可确保只有与这些头部有关的数据类型才出现在数据库中。多数情况下,文件头不会以任何形式被格式化,因为通常程序并不会直接引用它们自己的文件头。因此,分析器也没有必要对文件头应用结构体模板。
对一个PE二进制文件进行一番研究后,你会发现,PE文件的开头部分是一个名为IMAGE_DOS_HEADER的MS-DOS头部结构体。另外,IMAGE_DOS_HEADER中的数据指向一个IM-AGE_NE_HEADER结构体的位置。
第一步是添加标准的IMAGE_DOS_HEADER结构体(你可以在打开IMAGE_NT_HEADER结构体的同时添加该结构体)。

第二步是使用Edit▶Struct Var(ALT+Q),将从_Image-Base开始的字节转换成一个IMAGE_DOS_HEADER结构体