这节课讲DeepLabv3+模型,及前身DeepLabv3模型,两篇论文来自Google的同一个团队。
参考资料
DeepLabv3+,被引1000+
DeepLabv3,被引1000+
Pytorch DeepLabv3+实现,Star 1.5k
我们讲1.模型原理2.代码实现
from PIL import Image
from IPython import display
import torch.nn as nn
import torch
第一部分,模型原理
背景知识
整体架构
背景知识
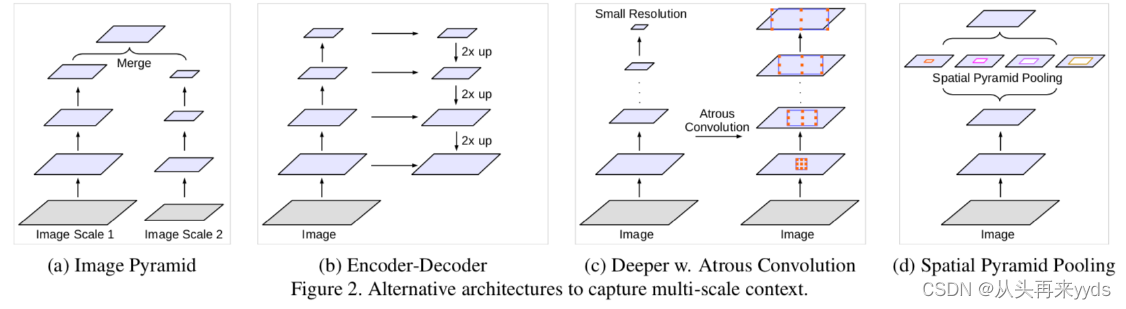
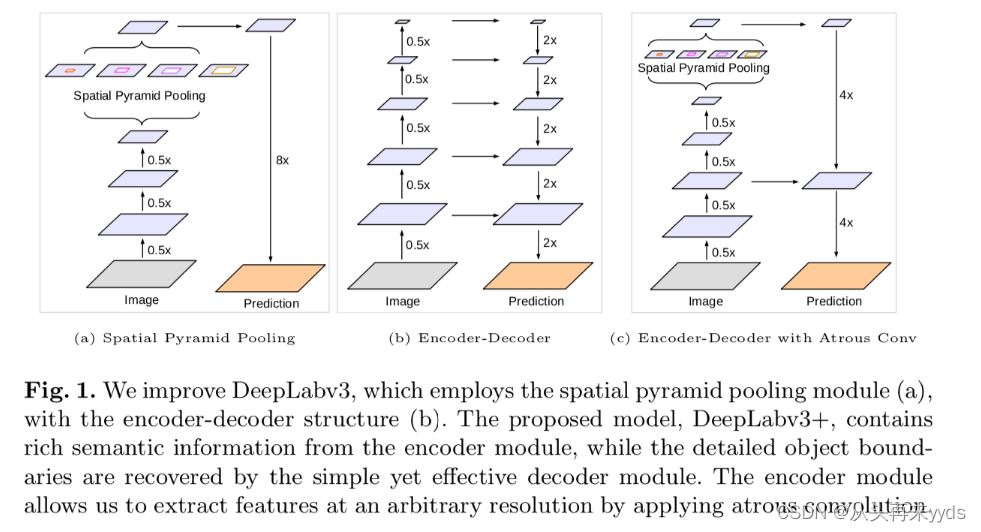
图像任务中 捕捉多尺度的图像信息很重要。通常有以下几种网络结构:
图a,一个相同的网络,共享权重,应用到不同尺度的图片上提取特征。对于尺寸小的图片输入,提取全局图像信息;对于尺寸大的图片输入,提取局部图像信息。最后将多尺度的图像信息融合。
图b,包含两个部分,下采样部分中图片尺寸逐层降低,浅层提取局部图像信息,深层提取全局图像信息;上采样中多尺度的图片特征合并,逐层还原图片尺寸。
图c,
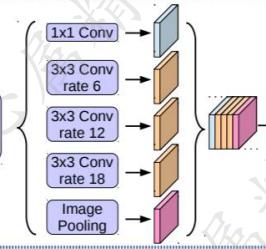
图d,SPP层采用多个不同比率(rate)的Atrous convolution,并行作用在特征图上,比率(rate)较大的卷积提取相对全局信息,较小的卷积提取相对局部的信息,最后将多个特征图进行合并。下面介绍"Atrous convolution"。
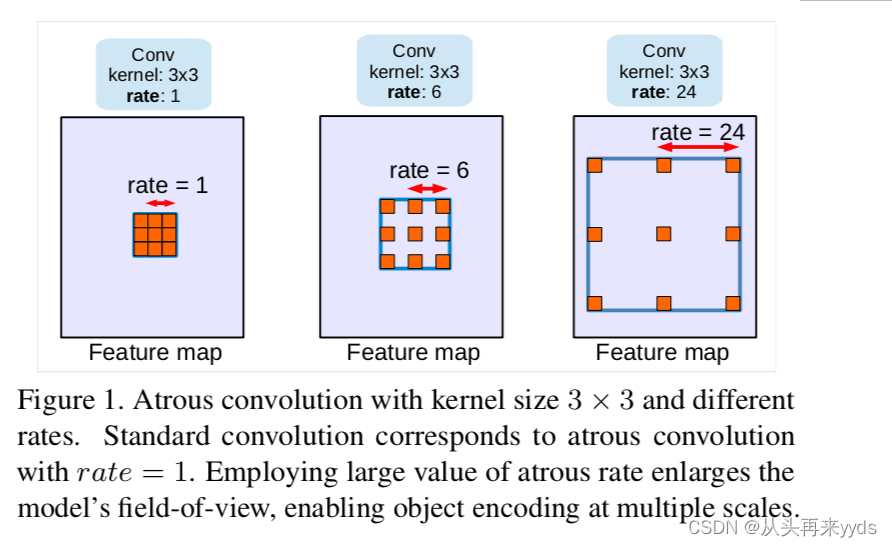
什么是"Atrous convolution"?(又叫"dilated convolution",回忆我们在pytorch的conv2d中的参数dilation=1)
一个卷积核中,相邻两个元素之间存在间隔,间隙中存在几个空白的元素,权重为0,不对图像做卷积
假如一个 3×3 的卷积,dilation rate分别为1、6、24,这三个卷积核内同样包含9个元素,对图像做9个像素点的计算
不额外增加计算量
dilation rate越大,扩大了卷积核的视野范围
dilation rate=1时就是我们常用的标准卷积核
多种dilation rate的卷积核能够捕捉多种尺度下的物体特征
dilation rate为1代表两个红色像素之间距离为1个像素点
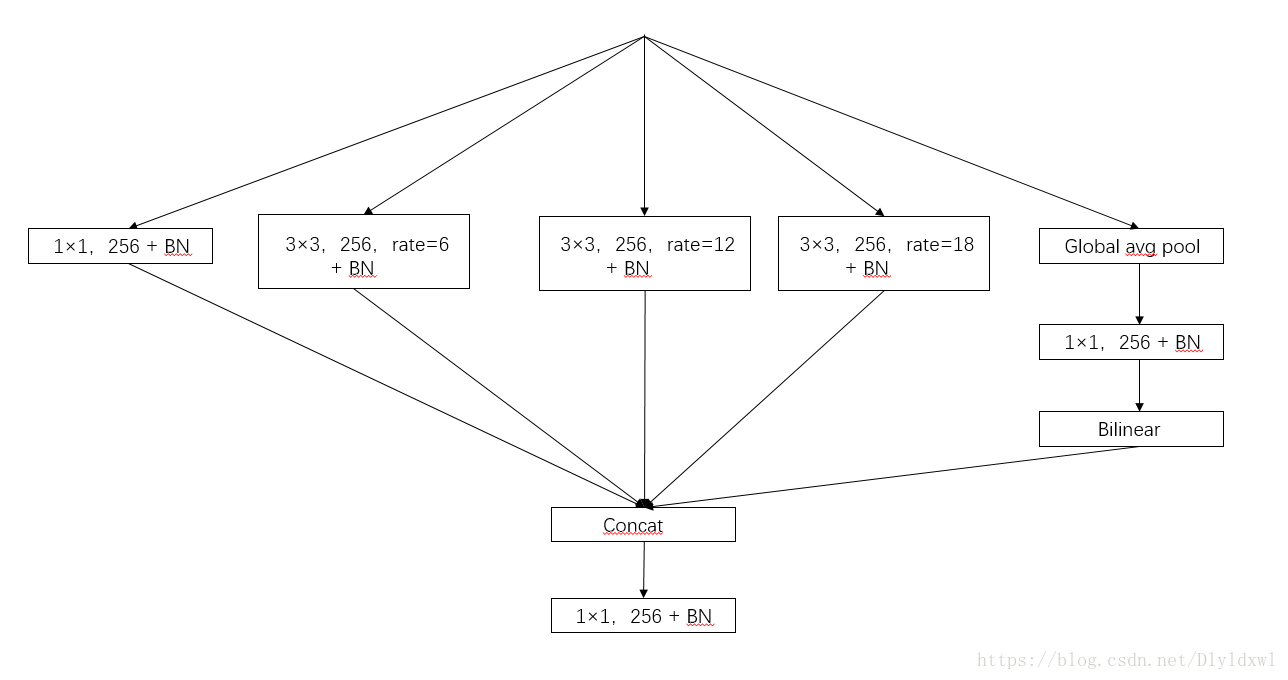
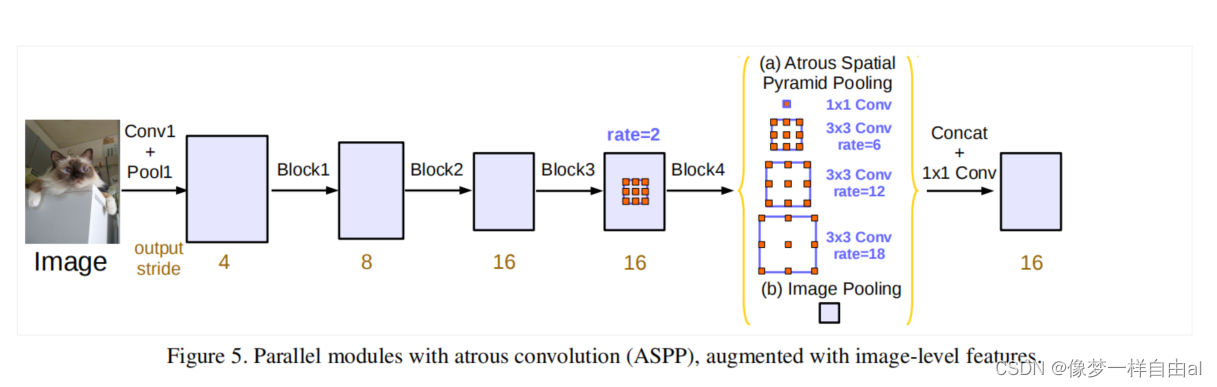
什么叫"ASPP"模块?
多个不同比率(rate)的Atrous convolution作用在特征图上,提取多尺度下图像特征,进行合并的结构叫做"ASPP"模块。例如下图中(a)(c)中,全称"Spatial Pyramid Pooling"。
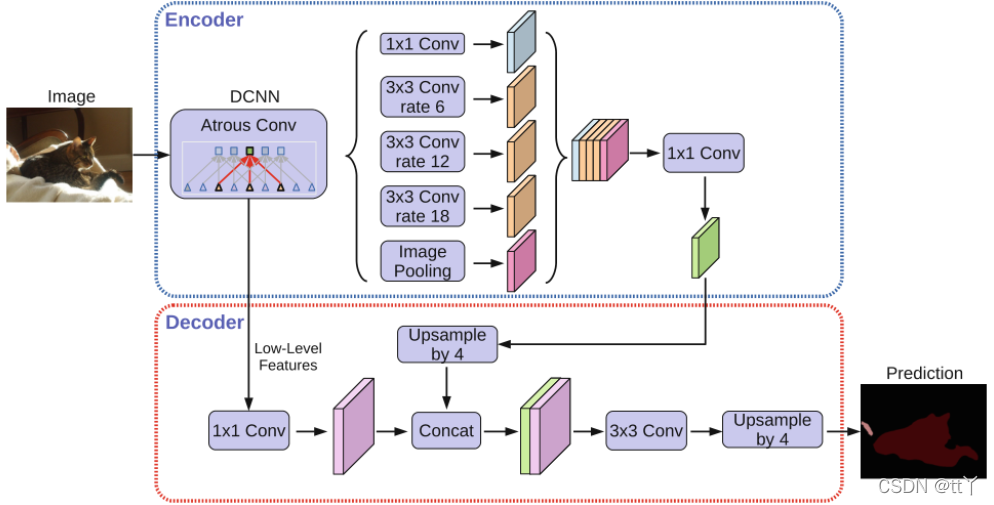
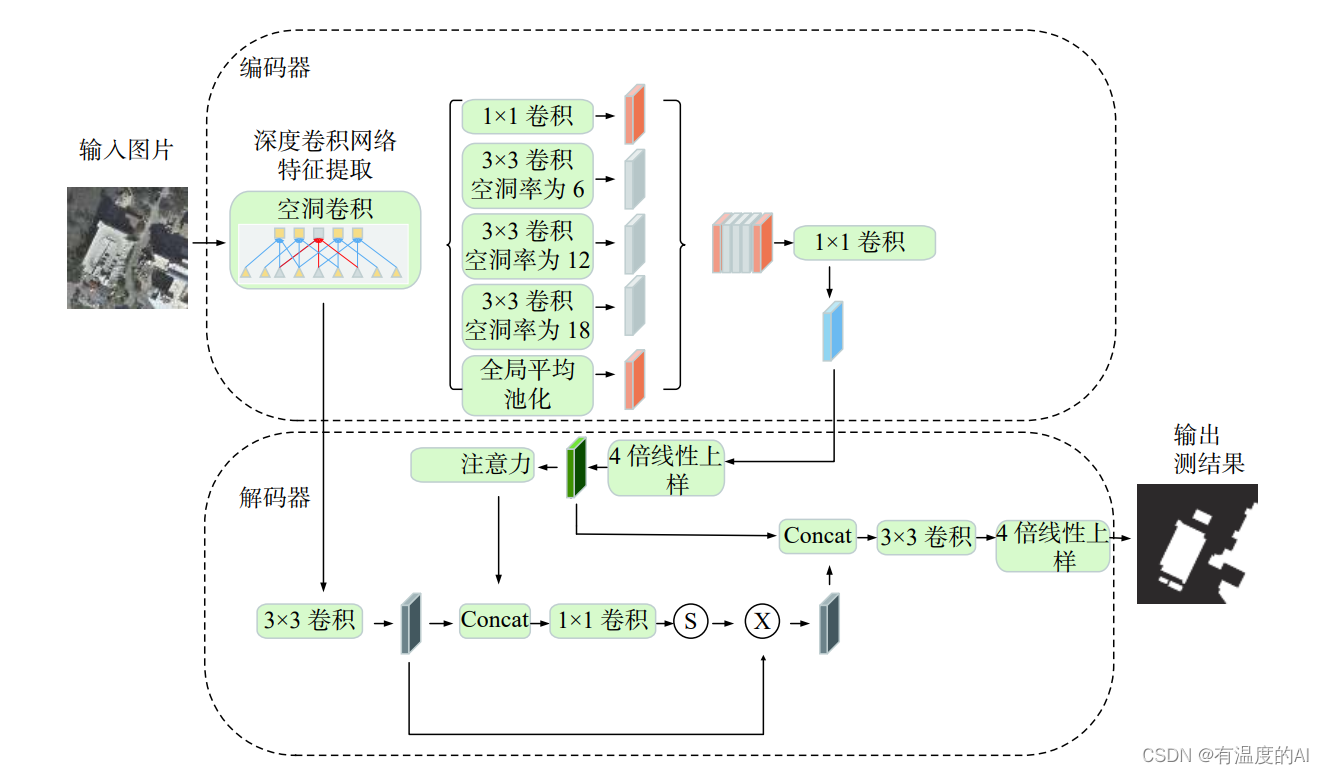
DeepLabv3网络结构是什么?下图(a)
输入图片先进入Encoder层提取特征
对特征图进行Atrous convolution操作,提取多尺度特征图后合并(ASPP模块)
模型学习到的图像分割其实是在降低8倍分辨率图片上进行的
还原图像尺寸输出Mask(比率8倍,例如 64×8=512 )
DeepLabv3改进点:
借鉴UNet等Encoder-Decoder结构中Skip Connection思想,将更多底层特征图融入到Decoder中
DeepLabv3+网络结构是什么?下图(c)
整体结构与DeepLabv3雷同,设计新的Decoder结构
Decoder中先将ASPP模块特征图还原4倍
将Ecoder中底层特征图与Decoder中特征图合并
将合并后特征图还原4倍,输出Mask
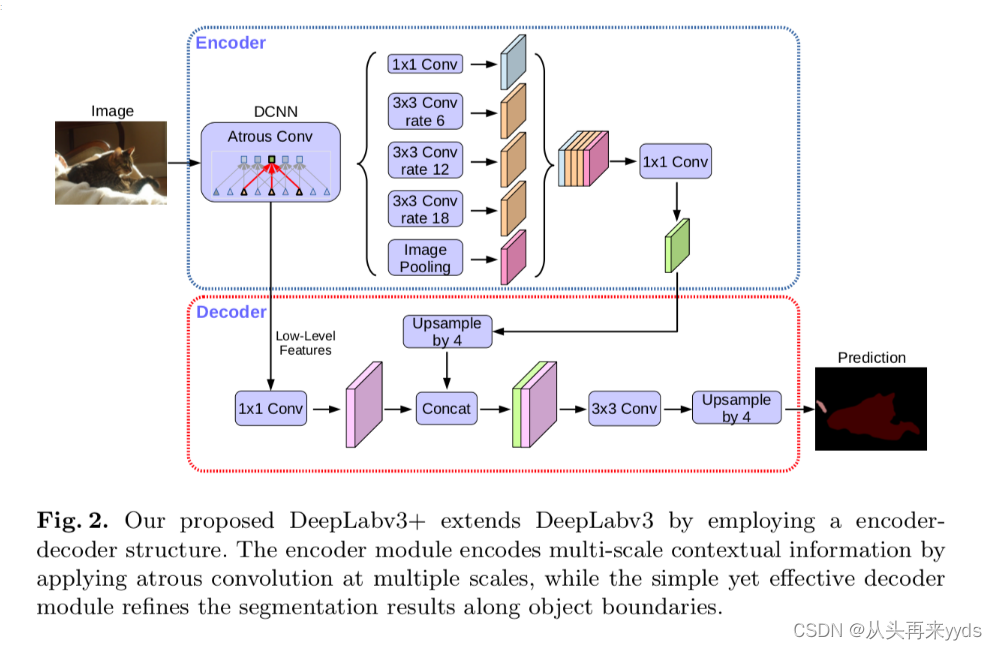
整体架构
输入图片,进入Ecoder层提取特征图,作者使用Resnet101、Modified Aligned Xception
进入ASPP模块,作者使用1个 1×1 卷积、3个 3×3 的Atrous convolution分别比率为6、12、18,以及一个图像全局的Pooling操作(为了克服当比率较大时Atrous convolution效果不好)
合并Ecoder特征图,使用一个 1×1 的卷积
上采样4倍
对底层特征图加一个 1×1 的卷积降低channel数,与Encoder特征图合并,进入 3×3 卷积层矫正分割效果(底层特征图通常256、512层,与Encoder特征图合并中层数占比过高,减损了Encoder特征图丰富的信息)
将分割上采样4倍还原图像尺寸
当rate特别大时,举一个极端的例子,当大到卷积核尺寸与特征图一样大时,3x3卷积的9个顶点在图像上,而计算的只是特征图的中间的像素点做了计算,即使卷积核在图像范围内,有效的卷积操作数越来越少,所以当rate越来越大时,卷积不太好,所以加了一个image pooling提取整张图片的特征图。
还有一个细节需要注意。
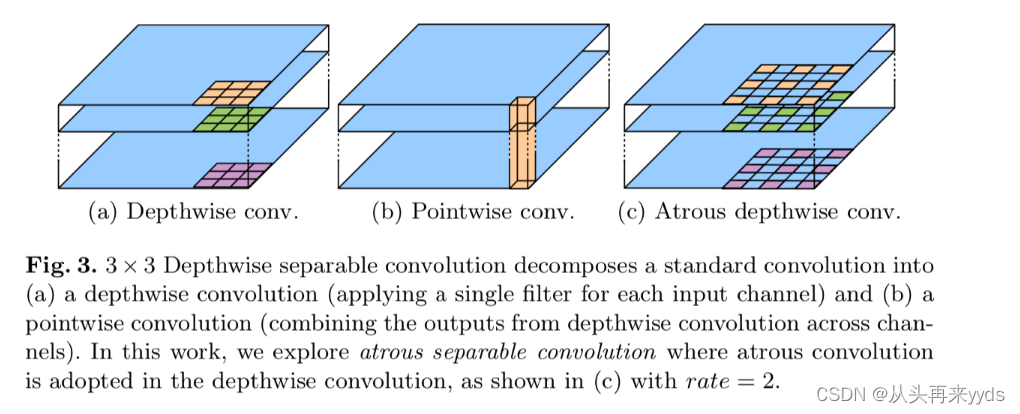
"Depthwise separable convolution"是什么?
图(a)一个 3×3 的卷积作用在每一个channel上,计算后每一个channel在每一个像素点位置上得到一个数值。几何平面内的操作。
图(b)将所有channel的每一个对应像素点位置的数值合并,得到一个数值,作为这个像素位置上的卷积结果。几何第三维度上的操作。
图(c)作者提出使用Atrous卷积核进行以上两步Depthwise separable convolution操作,称为"atrous separable convolution"
%%writefile resnet.py
import math
import torch.nn as nn
import torch.utils.model_zoo as model_zooclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, BatchNorm=None):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = BatchNorm(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,dilation=dilation, padding=dilation, bias=False)self.bn2 = BatchNorm(planes)self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)self.bn3 = BatchNorm(planes * 4)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = strideself.dilation = dilationdef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, layers, output_stride, BatchNorm, pretrained=True):self.inplanes = 64super(ResNet, self).__init__()blocks = [1, 2, 4]if output_stride == 16:strides = [1, 2, 2, 1]dilations = [1, 1, 1, 2]elif output_stride == 8:strides = [1, 2, 1, 1]dilations = [1, 1, 2, 4]else:raise NotImplementedError# Modulesself.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,bias=False)self.bn1 = BatchNorm(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(block, 64, layers[0], stride=strides[0], dilation=dilations[0], BatchNorm=BatchNorm)self.layer2 = self._make_layer(block, 128, layers[1], stride=strides[1], dilation=dilations[1], BatchNorm=BatchNorm)self.layer3 = self._make_layer(block, 256, layers[2], stride=strides[2], dilation=dilations[2], BatchNorm=BatchNorm)self.layer4 = self._make_MG_unit(block, 512, blocks=blocks, stride=strides[3], dilation=dilations[3], BatchNorm=BatchNorm)# self.layer4 = self._make_layer(block, 512, layers[3], stride=strides[3], dilation=dilations[3], BatchNorm=BatchNorm)self._init_weight()if pretrained:self._load_pretrained_model()def _make_layer(self, block, planes, blocks, stride=1, dilation=1, BatchNorm=None):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),BatchNorm(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, dilation, downsample, BatchNorm))self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes, dilation=dilation, BatchNorm=BatchNorm))return nn.Sequential(*layers)def _make_MG_unit(self, block, planes, blocks, stride=1, dilation=1, BatchNorm=None):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),BatchNorm(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, dilation=blocks[0]*dilation,downsample=downsample, BatchNorm=BatchNorm))self.inplanes = planes * block.expansionfor i in range(1, len(blocks)):layers.append(block(self.inplanes, planes, stride=1,dilation=blocks[i]*dilation, BatchNorm=BatchNorm))return nn.Sequential(*layers)def forward(self, input):x = self.conv1(input)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)low_level_feat = xx = self.layer2(x)x = self.layer3(x)x = self.layer4(x)return x, low_level_featdef _init_weight(self):for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))
# elif isinstance(m, SynchronizedBatchNorm2d):
# m.weight.data.fill_(1)
# m.bias.data.zero_()elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _load_pretrained_model(self):pretrain_dict = model_zoo.load_url('https://download.pytorch.org/models/resnet101-5d3b4d8f.pth')model_dict = {}state_dict = self.state_dict()for k, v in pretrain_dict.items():if k in state_dict:model_dict[k] = vstate_dict.update(model_dict)self.load_state_dict(state_dict)def ResNet101(output_stride=16, BatchNorm=nn.BatchNorm2d, pretrained=False):"""Constructs a ResNet-101 model.Args:pretrained (bool): If True, returns a model pre-trained on ImageNet"""model = ResNet(Bottleneck, [3, 4, 23, 3], output_stride, BatchNorm, pretrained=pretrained)return modelif __name__ == "__main__":import torchmodel = ResNet101(BatchNorm=nn.BatchNorm2d, pretrained=True, output_stride=8)input = torch.rand(1, 3, 512, 512)output, low_level_feat = model(input)print(output.size())print(low_level_feat.size())
第二部分,代码实现
import torch
import torch.nn as nn
from torch.nn import functional as F
import numpy as np
import mathfrom resnet import ResNet101
需要实现三个子模块
Encoder/Backbone
ASPP
Decoder
最后整合起来
- Encoder/Backbone
resnet.py中ResNet101,注意第120行将底层特征Copy一份最后输出。
net = ResNet101()
x, low_feats = net(torch.rand((1, 3, 128, 128)))
x.size(), low_feats.size()
- ASPP模块
class _ASPPModule(nn.Module):def __init__(self, inplanes, planes, kernel_size, padding, dilation):super(_ASPPModule, self).__init__()self.atrous_conv = nn.Conv2d(inplanes, planes, kernel_size=kernel_size,padding=padding, dilation=dilation,stride=1, bias=False)self.bn = nn.BatchNorm2d(planes)self.relu = nn.ReLU()
def forward(self, x):x = self.atrous_conv(x)x = self.bn(x)
return self.relu(x)
class ASPP(nn.Module):def __init__(self):super(ASPP, self).__init__()inplanes = 2048 #resnet101 encoderdilations = [1, 6, 12, 18]
self.aspp1 = _ASPPModule(inplanes, 256, 1, dilation=dilations[0], padding=0)#padding=dilation使得输出的4个特征图尺寸保持一致self.aspp2 = _ASPPModule(inplanes, 256, 3, dilation=dilations[1], padding=dilations[1])self.aspp3 = _ASPPModule(inplanes, 256, 3, dilation=dilations[2], padding=dilations[2])self.aspp4 = _ASPPModule(inplanes, 256, 3, dilation=dilations[3], padding=dilations[3])
self.global_avg_pool = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),nn.Conv2d(inplanes, 256, 1, stride=1, bias=False),nn.BatchNorm2d(256),nn.ReLU())self.conv1 = nn.Conv2d(1280, 256, 1, bias=False)self.bn1 = nn.BatchNorm2d(256)self.relu = nn.ReLU()self.dropout = nn.Dropout(0.5)
def forward(self, x):x1 = self.aspp1(x)x2 = self.aspp2(x)x3 = self.aspp3(x)x4 = self.aspp4(x)x5 = self.global_avg_pool(x)x5 = F.interpolate(x5, size=x4.size()[2:], mode='bilinear', align_corners=True)x = torch.cat((x1, x2, x3, x4, x5), dim=1)
x = self.conv1(x)x = self.bn1(x)x = self.relu(x)
return self.dropout(x)
add Codeadd Markdown
3. Decoder模块
add Codeadd Markdown
class Decoder(nn.Module):def __init__(self, num_classes):super(Decoder, self).__init__()low_level_inplanes = 256 #for resnet101 backbone
self.conv1 = nn.Conv2d(low_level_inplanes, 48, 1, bias=False)self.bn1 = nn.BatchNorm2d(48)self.relu = nn.ReLU()self.last_conv = nn.Sequential(nn.Conv2d(304, 256, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),nn.Dropout(0.5),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),nn.Dropout(0.1),nn.Conv2d(256, num_classes, kernel_size=1, stride=1))
def forward(self, x, low_level_feat):low_level_feat = self.conv1(low_level_feat)low_level_feat = self.bn1(low_level_feat)low_level_feat = self.relu(low_level_feat)
x = F.interpolate(x, size=low_level_feat.size()[2:], mode='bilinear', align_corners=True)x = torch.cat((x, low_level_feat), dim=1)x = self.last_conv(x)
return x
- Decoder模块
class Decoder(nn.Module):def __init__(self, num_classes):super(Decoder, self).__init__()low_level_inplanes = 256 #for resnet101 backboneself.conv1 = nn.Conv2d(low_level_inplanes, 48, 1, bias=False)self.bn1 = nn.BatchNorm2d(48)self.relu = nn.ReLU()self.last_conv = nn.Sequential(nn.Conv2d(304, 256, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),nn.Dropout(0.5),nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),nn.Dropout(0.1),nn.Conv2d(256, num_classes, kernel_size=1, stride=1))def forward(self, x, low_level_feat):low_level_feat = self.conv1(low_level_feat)low_level_feat = self.bn1(low_level_feat)low_level_feat = self.relu(low_level_feat)x = F.interpolate(x, size=low_level_feat.size()[2:], mode='bilinear', align_corners=True)x = torch.cat((x, low_level_feat), dim=1)x = self.last_conv(x)return x
整合起来,网络主函数
class DeepLabv3p(nn.Module):def __init__(self, num_classes=2):super(DeepLabv3p, self).__init__()self.backbone = ResNet101()self.aspp = ASPP()self.decoder = Decoder(num_classes)def forward(self, input):x, low_level_feat = self.backbone(input)print('backbone----x, low_level_feat: ', x.size(), low_level_feat.size())x = self.aspp(x)print('ASPP output: ', x.size())x = self.decoder(x, low_level_feat)print('decoder output: ', x.size())x = F.interpolate(x, size=input.size()[2:], mode='bilinear', align_corners=True)return x
net = DeepLabv3p()
for k,v in net.named_parameters():print(k)
backbone.conv1.weight
backbone.bn1.weight
backbone.bn1.bias
backbone.layer1.0.conv1.weight
backbone.layer1.0.bn1.weight
backbone.layer1.0.bn1.bias
backbone.layer1.0.conv2.weight
backbone.layer1.0.bn2.weight
backbone.layer1.0.bn2.bias
backbone.layer1.0.conv3.weight
backbone.layer1.0.bn3.weight
backbone.layer1.0.bn3.bias
backbone.layer1.0.downsample.0.weight
backbone.layer1.0.downsample.1.weight
backbone.layer1.0.downsample.1.bias
backbone.layer1.1.conv1.weight
backbone.layer1.1.bn1.weight
backbone.layer1.1.bn1.bias
backbone.layer1.1.conv2.weight
backbone.layer1.1.bn2.weight
backbone.layer1.1.bn2.bias
backbone.layer1.1.conv3.weight
backbone.layer1.1.bn3.weight
backbone.layer1.1.bn3.bias
backbone.layer1.2.conv1.weight
backbone.layer1.2.bn1.weight
backbone.layer1.2.bn1.bias
backbone.layer1.2.conv2.weight
backbone.layer1.2.bn2.weight
backbone.layer1.2.bn2.bias
backbone.layer1.2.conv3.weight
backbone.layer1.2.bn3.weight
backbone.layer1.2.bn3.bias
backbone.layer2.0.conv1.weight
backbone.layer2.0.bn1.weight
backbone.layer2.0.bn1.bias
backbone.layer2.0.conv2.weight
backbone.layer2.0.bn2.weight
backbone.layer2.0.bn2.bias
backbone.layer2.0.conv3.weight
backbone.layer2.0.bn3.weight
backbone.layer2.0.bn3.bias
backbone.layer2.0.downsample.0.weight
backbone.layer2.0.downsample.1.weight
backbone.layer2.0.downsample.1.bias
backbone.layer2.1.conv1.weight
backbone.layer2.1.bn1.weight
backbone.layer2.1.bn1.bias
backbone.layer2.1.conv2.weight
backbone.layer2.1.bn2.weight
backbone.layer2.1.bn2.bias
backbone.layer2.1.conv3.weight
backbone.layer2.1.bn3.weight
backbone.layer2.1.bn3.bias
backbone.layer2.2.conv1.weight
backbone.layer2.2.bn1.weight
backbone.layer2.2.bn1.bias
backbone.layer2.2.conv2.weight
backbone.layer2.2.bn2.weight
backbone.layer2.2.bn2.bias
backbone.layer2.2.conv3.weight
backbone.layer2.2.bn3.weight
backbone.layer2.2.bn3.bias
backbone.layer2.3.conv1.weight
backbone.layer2.3.bn1.weight
backbone.layer2.3.bn1.bias
backbone.layer2.3.conv2.weight
backbone.layer2.3.bn2.weight
backbone.layer2.3.bn2.bias
backbone.layer2.3.conv3.weight
backbone.layer2.3.bn3.weight
backbone.layer2.3.bn3.bias
backbone.layer3.0.conv1.weight
backbone.layer3.0.bn1.weight
backbone.layer3.0.bn1.bias
backbone.layer3.0.conv2.weight
backbone.layer3.0.bn2.weight
backbone.layer3.0.bn2.bias
backbone.layer3.0.conv3.weight
backbone.layer3.0.bn3.weight
backbone.layer3.0.bn3.bias
backbone.layer3.0.downsample.0.weight
backbone.layer3.0.downsample.1.weight
backbone.layer3.0.downsample.1.bias
backbone.layer3.1.conv1.weight
backbone.layer3.1.bn1.weight
backbone.layer3.1.bn1.bias
backbone.layer3.1.conv2.weight
backbone.layer3.1.bn2.weight
backbone.layer3.1.bn2.bias
backbone.layer3.1.conv3.weight
backbone.layer3.1.bn3.weight
backbone.layer3.1.bn3.bias
backbone.layer3.2.conv1.weight
backbone.layer3.2.bn1.weight
backbone.layer3.2.bn1.bias
backbone.layer3.2.conv2.weight
backbone.layer3.2.bn2.weight
backbone.layer3.2.bn2.bias
backbone.layer3.2.conv3.weight
backbone.layer3.2.bn3.weight
backbone.layer3.2.bn3.bias
backbone.layer3.3.conv1.weight
backbone.layer3.3.bn1.weight
backbone.layer3.3.bn1.bias
backbone.layer3.3.conv2.weight
backbone.layer3.3.bn2.weight
backbone.layer3.3.bn2.bias
backbone.layer3.3.conv3.weight
backbone.layer3.3.bn3.weight
backbone.layer3.3.bn3.bias
backbone.layer3.4.conv1.weight
backbone.layer3.4.bn1.weight
backbone.layer3.4.bn1.bias
backbone.layer3.4.conv2.weight
backbone.layer3.4.bn2.weight
backbone.layer3.4.bn2.bias
backbone.layer3.4.conv3.weight
backbone.layer3.4.bn3.weight
backbone.layer3.4.bn3.bias
backbone.layer3.5.conv1.weight
backbone.layer3.5.bn1.weight
backbone.layer3.5.bn1.bias
backbone.layer3.5.conv2.weight
backbone.layer3.5.bn2.weight
backbone.layer3.5.bn2.bias
backbone.layer3.5.conv3.weight
backbone.layer3.5.bn3.weight
backbone.layer3.5.bn3.bias
backbone.layer3.6.conv1.weight
backbone.layer3.6.bn1.weight
backbone.layer3.6.bn1.bias
backbone.layer3.6.conv2.weight
backbone.layer3.6.bn2.weight
backbone.layer3.6.bn2.bias
backbone.layer3.6.conv3.weight
backbone.layer3.6.bn3.weight
backbone.layer3.6.bn3.bias
backbone.layer3.7.conv1.weight
backbone.layer3.7.bn1.weight
backbone.layer3.7.bn1.bias
backbone.layer3.7.conv2.weight
backbone.layer3.7.bn2.weight
backbone.layer3.7.bn2.bias
backbone.layer3.7.conv3.weight
backbone.layer3.7.bn3.weight
backbone.layer3.7.bn3.bias
backbone.layer3.8.conv1.weight
backbone.layer3.8.bn1.weight
backbone.layer3.8.bn1.bias
backbone.layer3.8.conv2.weight
backbone.layer3.8.bn2.weight
backbone.layer3.8.bn2.bias
backbone.layer3.8.conv3.weight
backbone.layer3.8.bn3.weight
backbone.layer3.8.bn3.bias
backbone.layer3.9.conv1.weight
backbone.layer3.9.bn1.weight
backbone.layer3.9.bn1.bias
backbone.layer3.9.conv2.weight
backbone.layer3.9.bn2.weight
backbone.layer3.9.bn2.bias
backbone.layer3.9.conv3.weight
backbone.layer3.9.bn3.weight
backbone.layer3.9.bn3.bias
backbone.layer3.10.conv1.weight
backbone.layer3.10.bn1.weight
backbone.layer3.10.bn1.bias
backbone.layer3.10.conv2.weight
backbone.layer3.10.bn2.weight
backbone.layer3.10.bn2.bias
backbone.layer3.10.conv3.weight
backbone.layer3.10.bn3.weight
backbone.layer3.10.bn3.bias
backbone.layer3.11.conv1.weight
backbone.layer3.11.bn1.weight
backbone.layer3.11.bn1.bias
backbone.layer3.11.conv2.weight
backbone.layer3.11.bn2.weight
backbone.layer3.11.bn2.bias
backbone.layer3.11.conv3.weight
backbone.layer3.11.bn3.weight
backbone.layer3.11.bn3.bias
backbone.layer3.12.conv1.weight
backbone.layer3.12.bn1.weight
backbone.layer3.12.bn1.bias
backbone.layer3.12.conv2.weight
backbone.layer3.12.bn2.weight
backbone.layer3.12.bn2.bias
backbone.layer3.12.conv3.weight
backbone.layer3.12.bn3.weight
backbone.layer3.12.bn3.bias
backbone.layer3.13.conv1.weight
backbone.layer3.13.bn1.weight
backbone.layer3.13.bn1.bias
backbone.layer3.13.conv2.weight
backbone.layer3.13.bn2.weight
backbone.layer3.13.bn2.bias
backbone.layer3.13.conv3.weight
backbone.layer3.13.bn3.weight
backbone.layer3.13.bn3.bias
backbone.layer3.14.conv1.weight
backbone.layer3.14.bn1.weight
backbone.layer3.14.bn1.bias
backbone.layer3.14.conv2.weight
backbone.layer3.14.bn2.weight
backbone.layer3.14.bn2.bias
backbone.layer3.14.conv3.weight
backbone.layer3.14.bn3.weight
backbone.layer3.14.bn3.bias
backbone.layer3.15.conv1.weight
backbone.layer3.15.bn1.weight
backbone.layer3.15.bn1.bias
backbone.layer3.15.conv2.weight
backbone.layer3.15.bn2.weight
backbone.layer3.15.bn2.bias
backbone.layer3.15.conv3.weight
backbone.layer3.15.bn3.weight
backbone.layer3.15.bn3.bias
backbone.layer3.16.conv1.weight
backbone.layer3.16.bn1.weight
backbone.layer3.16.bn1.bias
backbone.layer3.16.conv2.weight
backbone.layer3.16.bn2.weight
backbone.layer3.16.bn2.bias
backbone.layer3.16.conv3.weight
backbone.layer3.16.bn3.weight
backbone.layer3.16.bn3.bias
backbone.layer3.17.conv1.weight
backbone.layer3.17.bn1.weight
backbone.layer3.17.bn1.bias
backbone.layer3.17.conv2.weight
backbone.layer3.17.bn2.weight
backbone.layer3.17.bn2.bias
backbone.layer3.17.conv3.weight
backbone.layer3.17.bn3.weight
backbone.layer3.17.bn3.bias
backbone.layer3.18.conv1.weight
backbone.layer3.18.bn1.weight
backbone.layer3.18.bn1.bias
backbone.layer3.18.conv2.weight
backbone.layer3.18.bn2.weight
backbone.layer3.18.bn2.bias
backbone.layer3.18.conv3.weight
backbone.layer3.18.bn3.weight
backbone.layer3.18.bn3.bias
backbone.layer3.19.conv1.weight
backbone.layer3.19.bn1.weight
backbone.layer3.19.bn1.bias
backbone.layer3.19.conv2.weight
backbone.layer3.19.bn2.weight
backbone.layer3.19.bn2.bias
backbone.layer3.19.conv3.weight
backbone.layer3.19.bn3.weight
backbone.layer3.19.bn3.bias
backbone.layer3.20.conv1.weight
backbone.layer3.20.bn1.weight
backbone.layer3.20.bn1.bias
backbone.layer3.20.conv2.weight
backbone.layer3.20.bn2.weight
backbone.layer3.20.bn2.bias
backbone.layer3.20.conv3.weight
backbone.layer3.20.bn3.weight
backbone.layer3.20.bn3.bias
backbone.layer3.21.conv1.weight
backbone.layer3.21.bn1.weight
backbone.layer3.21.bn1.bias
backbone.layer3.21.conv2.weight
backbone.layer3.21.bn2.weight
backbone.layer3.21.bn2.bias
backbone.layer3.21.conv3.weight
backbone.layer3.21.bn3.weight
backbone.layer3.21.bn3.bias
backbone.layer3.22.conv1.weight
backbone.layer3.22.bn1.weight
backbone.layer3.22.bn1.bias
backbone.layer3.22.conv2.weight
backbone.layer3.22.bn2.weight
backbone.layer3.22.bn2.bias
backbone.layer3.22.conv3.weight
backbone.layer3.22.bn3.weight
backbone.layer3.22.bn3.bias
backbone.layer4.0.conv1.weight
backbone.layer4.0.bn1.weight
backbone.layer4.0.bn1.bias
backbone.layer4.0.conv2.weight
backbone.layer4.0.bn2.weight
backbone.layer4.0.bn2.bias
backbone.layer4.0.conv3.weight
backbone.layer4.0.bn3.weight
backbone.layer4.0.bn3.bias
backbone.layer4.0.downsample.0.weight
backbone.layer4.0.downsample.1.weight
backbone.layer4.0.downsample.1.bias
backbone.layer4.1.conv1.weight
backbone.layer4.1.bn1.weight
backbone.layer4.1.bn1.bias
backbone.layer4.1.conv2.weight
backbone.layer4.1.bn2.weight
backbone.layer4.1.bn2.bias
backbone.layer4.1.conv3.weight
backbone.layer4.1.bn3.weight
backbone.layer4.1.bn3.bias
backbone.layer4.2.conv1.weight
backbone.layer4.2.bn1.weight
backbone.layer4.2.bn1.bias
backbone.layer4.2.conv2.weight
backbone.layer4.2.bn2.weight
backbone.layer4.2.bn2.bias
backbone.layer4.2.conv3.weight
backbone.layer4.2.bn3.weight
backbone.layer4.2.bn3.bias
aspp.aspp1.atrous_conv.weight
aspp.aspp1.bn.weight
aspp.aspp1.bn.bias
aspp.aspp2.atrous_conv.weight
aspp.aspp2.bn.weight
aspp.aspp2.bn.bias
aspp.aspp3.atrous_conv.weight
aspp.aspp3.bn.weight
aspp.aspp3.bn.bias
aspp.aspp4.atrous_conv.weight
aspp.aspp4.bn.weight
aspp.aspp4.bn.bias
aspp.global_avg_pool.1.weight
aspp.global_avg_pool.2.weight
aspp.global_avg_pool.2.bias
aspp.conv1.weight
aspp.bn1.weight
aspp.bn1.bias
decoder.conv1.weight
decoder.bn1.weight
decoder.bn1.bias
decoder.last_conv.0.weight
decoder.last_conv.1.weight
decoder.last_conv.1.bias
decoder.last_conv.4.weight
decoder.last_conv.5.weight
decoder.last_conv.5.bias
decoder.last_conv.8.weight
decoder.last_conv.8.bias
image = torch.rand((4, 3, 128, 128))
mask = net(image)
# backbone----x, low_level_feat: torch.Size([4, 2048, 8, 8]) # torch.Size([4, 256, 32, 32])
# ASPP output: torch.Size([4, 256, 8, 8])
# decoder output: torch.Size([4, 2, 32, 32])
mask.size()
# torch.Size([4, 2, 128, 128])