网站流量日志分析系统(一)概念
网站流量日志分析系统:
点击流数据模型
点击流:是指用户持续访问浏览网站的轨迹。
点击流数据是由散点状的点击日志数据梳理所得。点击流数据在数据建模时存在俩张模型表 Pageviews 和visits
1.首先有一张:原始访问日志表 时间戳/ip地址/请求的url/referal/响应码/。。。
2.页面点击流模型的 pageviews 表 session/ip地址/时间/访问的url/停留时长/第几步
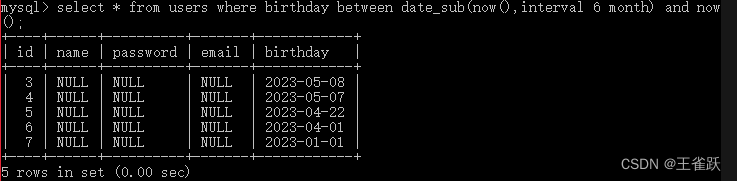
3.点击流模型 visits 表(按session聚集的页面访问信息) session/起始时间/结束时间/进入页面/离开页面/访问的页面数/ip/referal
如何进行网站流量分析:整个过程似一个金字塔

网站流量日志分析的最终目标是:ROI(投资回报率)
而且明确一点:流量并不是越多越好,还要看流量的质量,换句话讲就是流量可以给我们带来多少收入。

Bd(bd流量是指商务拓展流量)
细分:多维度 如:时间粒度/地理位置/目标页面/新老访客
对于所有的网站来说,页面可以划分为三个类别:导航页/功能页/内容页
导航页的目的是引导访问者找到信息,功能页的目的是帮助访问者完成特定
任务,内容页的目的是向访问者展示信息并帮助访问者进行 决策。
导航页有:首页/列表页
功能页有:搜索页面/注册表单页面/购物车页面等
内容页有:
网站转化和漏斗分析(转化分析)
即放文件在各环节递进访问的过程中慢慢流失的现象。【访问者的流失和迷失】
指标是网站分析的基础,用来记录和衡量访问者在网站的各种行为。
一 骨灰级指标:
1.ip:1天内,访问网站的不重复ip数。
2.Pageview(简称 PV)一个用户多次打开同一个网站就累加多次。通俗的讲就是页面被加载的次数。
3.Unique pageview:一天内同一访客多次访问网站只被计算 1 次。
二 基础级指标:
1.访问的次数:指访问者从进入网站到离开网站 记为1次,也称为会话(session),一次会话可能包含多个pv
2.网站的停留时间:访问者在网站上花费的时间。
3.页面停留时间:访问者在某个特定的页面停留的时间。
三 复合级指标:
1.人均浏览页数:平均每个独立访客产生的pv。人均浏览页数=浏览次数/独立访客
2.跳出率:在一次访问中访问者进入网站后只访问了一个页面就离开的数量
3.退出率:指访问者离开网站的次数
基于以上的指标,我们就可以从不同的角度进行分析
一 基础分析:pv/ip/uv
二 来源分析: 来源分类/ 搜索引擎/搜索词
三 受访分析:受访的域名/受访的页面/受访升级榜/热点图/用户视点/访问轨迹
四 访客分析:地区运营商/终端详情/新老访客/忠诚度/活跃度
五 转化路径分析:
网站流量日志分析是纯粹的数据分析项目
数据处理的流程可分为一下几个步骤:数据采集/数据预处理/数据入库/数据分析/数据展现
1.数据采集:数据从无到有的过程如:web服务器打印日志/自定义采集的日志等 另一方面也可以把通过使用flume等工具把数据采集到指定位置的过程叫做数据采集。
2.数据预处理:通过mapreduce程序对采集到的原始日志数据进行预处理,比如:清洗/格式整理/过滤脏数据等,并梳理成点击流模型数据。
3.数据入库:将预处理后的数据导入到hive仓库中相应的的库和表中。
4**.数据分析**:项目的核心内容,即根据需求开发etl分析语句,得出各种统计结果。
5.数据展现:将分析所得的数据结果进行可视化,一般通过图表进行展示。
系统架构:数据采集–>数据预处理–>导入hive仓库–>etl–>报表统计–>结果导出到mysql–>数据可视化
数据采集:定制开发采集程序,或使用开源框架 Flume
数据预处理:定制开发 mapreduce 程序运行于 hadoop 集群
数据仓库技术:基于 hadoop 之上的 Hive
数据导出:基于 hadoop 的 sqoop 数据导入导出工具
数据可视化:定制开发 web 程序**(echarts)**
整个过程的流程调度:hadoop 生态圈中的 azkaban 工具
流程如下: