顺序栈,即栈的顺序存储结构是利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针top指示栈项元素在顺序栈中的位置。通常的习惯做法是以top=0表示空栈,鉴于C语言中数组的下标约定从0开始,则当以C作描述语言时,如此设定会带来很大不便;另一方面由于栈在使用过程中所需最大空间的大小很难估计,因此,一般来说,在初始化设空栈时不应限定栈的最大容量。一个较合理的做法是:先为栈分配一个基本容量,然后在应用过程中,当栈的空间不够使用时再逐段扩大。为此,可设定两个常量:STAC_INT_SIZE(存储空间初始分配)和STACKINCREMENT(存储空间分配增量),并以下述类型说明作为顺序栈的定义。
typedef struct{
SElemType *base;
SElemType *top;
int stackseze;
}SqStack;
其中,stacksize只是栈的当前可使用的最大容量。栈的初始化操作为:按设定的初始分配量进行第一次存储分配,base可称为栈底指针,在顺序栈中,它始终指向栈底的位置,若base的值为NULL,则表明栈结构不存在。称top为栈顶指针,其初值指向栈底,即top=base可作为栈空的标记,每当插入新的栈顶元素时,指针top增1;删除栈顶元素时,指针top减1,因此,非空栈中的栈顶指针始终在栈顶元素的下一个位置上。图1展示了顺序栈中数据元素和栈顶指针之间的对应关系。

图1 栈顶指针和栈中元素之间的关系
以下是顺序栈的模块说明。
//=====ADT Stack 的表示与实现 =====
//-----栈的顺序存储表示-----
#define STACK_INIT_SIZE 100; //存储空间初始分配量
#define STACKINCREMENT 10; //存储空间分配增量
typedef struct{
SElemType *base; //在栈构造之前和销毁之后,base的值为NULL
SElemType *top; //栈顶指针
int stacksize; //当前已分配的存储空间,以元素为单位
}SqStack;
//-----基本操作的函数原型说明(针对几个易错易考的)-----
Status GetTop (SqStack S, SElemType &e);
//若栈不空,则用e返回S的栈顶元素,并返回OK;否则返回ERRO
Status Push (SqStack &S, SElemType e);
//插入元素e为新的栈顶元素
Status Pop (SqStack &S, SElemType &e);
// 若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR
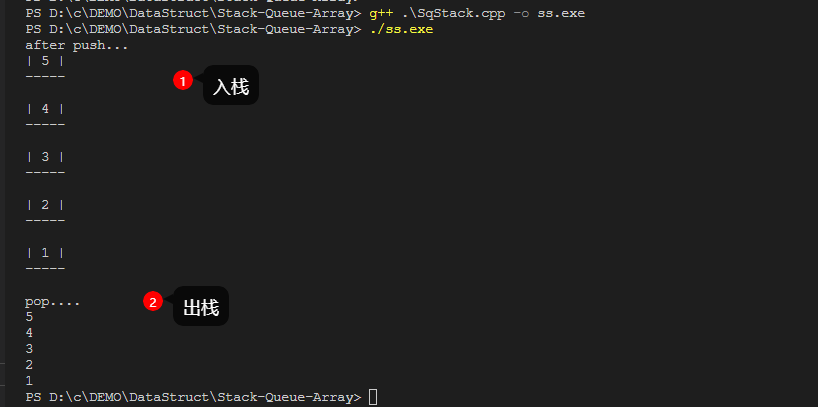
栈的引入简化了程序设计的问题,划分了不同的关注层次,使思考范围缩小了。而用数组不仅掩盖了问题的本质,还要分散精力去考虑数组下标增减等细节问题。(栈这个数据结构模型正是基于一些问题本质而构建的,具有了一些实际的模型含义,不像数组那样原始。 )
队列是一种先进先出(first infirst out,缩写为FIFO)的线性表。它只允许在标的一端进行插入,而在另一端删除元素。这和我们日常生活中的排队是一致的,最早进入队列的元素最早离开。在队列中,允许插入的一端叫做队尾(rear),允许删除的一端则称为对头(front)(排队买票,窗口一端叫对头,末尾进队叫队尾)。
用链表表示的队列称为链队列,如图2所示。一个链队列显然需要两个分别指向对头和队尾的指针(分别称为头指针和尾指针)才能唯一确定。这里,和线性表的单链表一样,为了操作方便起见,我们先给链队列添加一个头结点,并令头指针和尾指针均指向头结点,如图3(a)所示。链队列的操作即为单链表的插入和删除操作的特殊情况,只是尚需修改尾指针或头指针,图3(b)~(d)展示了这两种操作进行时指针变化的情况。下面给出链队列类型的模块说明。


图2 链队列示意图 图3 队列运算指针变化情况 (a)空队列;(b)元素x入队;(c)元素y入队;(d)元素x出队
//=====ADT Queue的表示与实现=====
//-----单链队列——队列的链式存储结构-----
typedef struct QNode{
QElemType data;
struct QNode *next;
}QNode, *QueuePtr;
typedef struct{
QueuePtr front; //对头指针
QueuePtr rear; //队尾指针
}LinkQueue;
//-----基本操作的函数原型说明(几个易错常考的)-----
Status GetHead(LinkQueue Q, QElemType &e)
//若队列不空,则用e返回Q的对头元素,并返回OK;否则返回ERROR
Status EnQueue(LinkQueue &Q, QElemType e)
//插入元素e为Q的新的队尾元素
Status DeQueue(LinkQueue &Q, QElemType &e)
//若队列不空,则删除Q的对头元素,用e返回其值,并返回OK;
//否则返回ERROR
和顺序栈相类似,在队列的顺序存储结构中,除了用一组地址连续的存储单元依次存放从队列头到队列尾的元素之外,尚需附设两个指针front和rear分别之时队列头元素和队列尾元素的位置。为了在C语言中描述方便起见,在此我们约定:初始化建空队列时,令front=rear=0,每当插入新的队列尾元素时,“尾指针增1”;每当删除队列头元素时,“头指针增1”。因此,在非空队列中,头指针始终指向队列头元素,而尾指针始终指向队列尾元素的下一个位置。如图4所示。
 图4 头、尾指针和队列中元素之间的关系
图4 头、尾指针和队列中元素之间的关系
(a)空队列;(b)J1、J2和J3相继入队列;(c)J1和J2相继被删除;(d)J4、J5和J6相继插入队列之后J3及J4被删除
假设当前为队列分配的最大空间为6,则当队列处于图4(d)的状态时不可再继续插入新的队尾元素,否则会因数组越界而遭致程序代码被破坏。然而此时又不宜如顺序栈那样,进行存储再分配扩大数组空间,因为队列的实际可用空间并未占满。一个较巧妙的办法是将顺序队列臆造为一个环状的空间,如图5所示,称之为循环队列。指针和队列元素之间关系不变,如图6(a)所示循环队列中,队列头元素时J3,队列尾元素是J5,之后J6、J7和J8相继插入,则队列空间均被占满,如图6(b)所示,此时Q.front=Q.rear;反之,若J3、J4和J5相继从图6(a)的队列中删除,使队列呈“空”的状态,如图6(c)所示。此时亦存在关系式Q.front=Q.rear,由此可见,只凭等式Q.front=Q.rear无法判别队列空间是“空”还是“满”。可由两种处理方法:其一是另设一个标志位以区别队列是“空”还是“满”;其二是少用一个元素空间,约定以“队列头指针在队列尾指针的下一位置(指环状的下一位置)上”作为队列呈“满”状态的标志。

图5 循环队列示意图

图6 循环队列的头尾指针 (a)一般情况;(b)队列满时;(c)空队列;
从上述分析可见,在C语言中不能用动态分配的一维数组来实现循环队列。如果用户的应用程序中设有循环队列,则必须为它设定一个最大队列长度;若用户无法预估所用队列的最大长度,则宜采用链队列。循环队列类型的模块说明如下:
//-----循环队列———队列的顺序存储结构-----
#define MAXQSIZE 100 //最大队列长度
typedef struct{
QElemType *base; //初始化的动态非配存储空间
int front; //头指针,若队列不空,指向队列的头元素
int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
//-----循环队列的基本操作的算法描述-----
Status InitQueue(SqQueue &Q){
//构造一个空队列Q
Q.base=(ElemType *)malloc(MAXQSIZE*sizeof(ElemType));
if(!Q.base) exit (OVERFLOW); // 存储分配失败
Q.front=Q.rear=0;
return OK;
}
int QueueLength(SqQueue Q){
//返回Q的元素个数,即队列的长度
return (Q.rear-Q.front+MAXQSIZE) % MAXQSIZE;
}
Status EnQueue(SqQueue &Q, QElemType e){
//插入元素e为Q的新的队尾元素
if((Q.rear+1) % MAXQSIZE == Q.front) return ERROR; // 队列满
Q.base[Q.rear]=e;
Q.rear=(Q.rear+1) % MAXQSIZE;
return OK;
}
Status DeQueue(SqQueue &Q, QElemType &e){
//若队列不空,则删除Q的对头元素,用e返回其值,并返回OK;
//否则返回ERROR
if(Q.front==Q.rear) return ERROR;
e=Q.base[Q.front];
Q.front=(Q.front+1) % MAXQSIZE;
return OK;
}


![[转载]静息态fMRI、DTI、VBM](http://simg.sinajs.cn/blog7style/images/common/sg_trans.gif)
![[spm操作] VBM分析中,modulation的作用](http://52brain.com/data/attachment/forum/201703/28/022631c8j8h668saiszbw8.png)