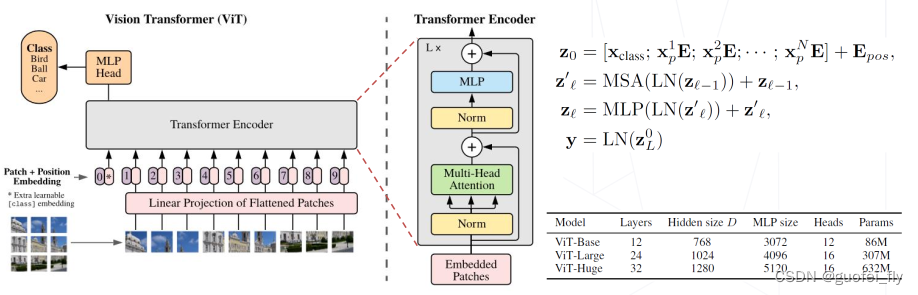
pytorch 图片分类,python 图片分类,resnet18 图片分类,深度学习 图片分类
pytorch版本:1.5.0+cu101
全部源码,可以直接运行。
下载地址:https://download.csdn.net/download/TangLingBo/12598435
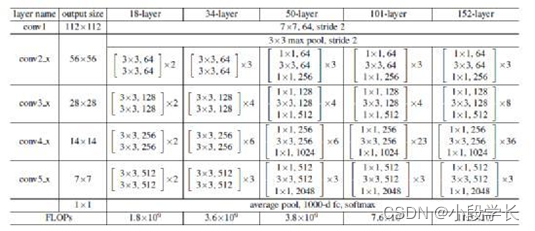
网络是用 resnet18 ,可以修改图片的大小,默认是32 x32
如果出现需要下载的文件或者问题可以联系:QQ 1095788063
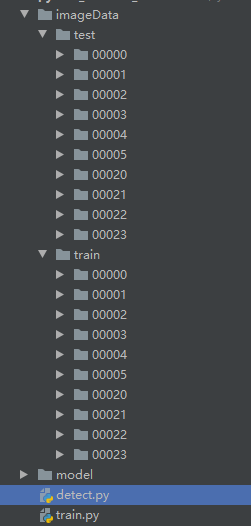
图片结构:

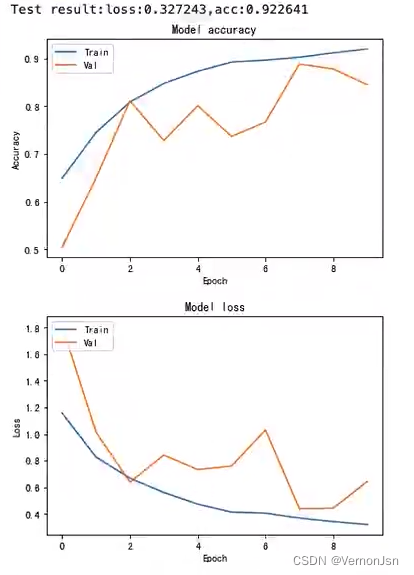
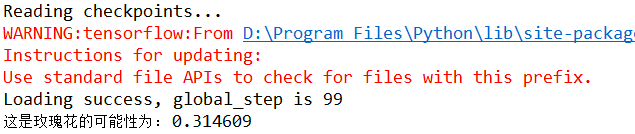
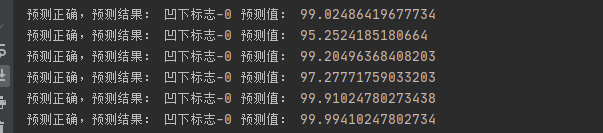
测试结果:

训练代码:
import torch as t
import torchvision as tv
import os
import time
import numpy as np
from tqdm import tqdm# 一些参数配置
class DefaultConfigs(object):data_dir = "./imageData/" # 图片目录data_list = ["train", "test"] # train=训练集,test=测试集lr = 0.001 # 学习率(默认值:1e-3epochs = 51 # 训练次,越多就越好num_classes = 10 # 分类image_size = 32 # 图片大小 ,可以改,因为用的是 resnet18 的网络,越大就越慢batch_size = 40 # 批量大小,看自己电脑的配置,需要占用 CPU或者GPU资源channels = 3 # 通道数use_gpu = t.cuda.is_available() # 启用gpu,如果电脑不支持,直接设置为 False ,GPU 训练效果最好config = DefaultConfigs()
config.use_gpu = False # 我的电脑不支持,设置为 False# 对Tensor进行变换 颜色转换 mean=给定均值:(R,G,B) std=方差:(R,G,B)
normalize = tv.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])# Train数据需要进行随机裁剪,Test数据不要进行裁剪了
transform = {# tv.transforms.Resize 用于重设图片大小 train 训练集数据# tv.transforms.CenterCrop([224,224]) 将给定的PIL.Image进行中心切割config.data_list[0]: tv.transforms.Compose([tv.transforms.Resize([config.image_size, config.image_size]),tv.transforms.CenterCrop([config.image_size,config.image_size]),tv.transforms.ToTensor(), normalize]),# test 测试数据config.data_list[1]: tv.transforms.Compose([tv.transforms.Resize([config.image_size, config.image_size]),tv.transforms.ToTensor(),normalize])
}# 数据集
datasets = {x: tv.datasets.ImageFolder(root=os.path.join(config.data_dir, x), transform=transform[x])for x in config.data_list
}# 数据加载器
dataloader = {x: t.utils.data.DataLoader(dataset=datasets[x],batch_size=config.batch_size,shuffle=True)for x in config.data_list
}# 构建网络模型 resnet18
def get_model(num_classes):#resnet18 好像要下载什么的,忘记了,可以联系我model = tv.models.resnet18(pretrained=True)# 梯度什么的,电脑硬件支持,可以把下述代码屏蔽,则训练整个网络,最终准确率会上升,训练数据会变慢# for parma in model.parameters():# parma.requires_grad = Falsemodel.fc = t.nn.Sequential(t.nn.Dropout(p=0.3), t.nn.Linear(512, num_classes))return model# 训练模型(支持自动GPU加速)
def train(epochs):model = get_model(config.num_classes)loss_f = t.nn.CrossEntropyLoss()# GPUif config.use_gpu:model = model.cuda()loss_f = loss_f.cuda()opt = t.optim.Adam(model.fc.parameters(), lr=config.lr)# 时间time_start = time.time()for epoch in range(epochs):train_loss = []train_acc = []test_loss = []test_acc = []model.train(True) # 将模块设置为训练模式print("Epoch {}/{}".format(epoch + 1, epochs))for batch, datas in tqdm(enumerate(iter(dataloader["train"]))):x, y = datas# 开启GPU 加速if config.use_gpu:x, y = x.cuda(), y.cuda()y_ = model(x)# print(x.shape, y.shape, y_.shape)_, pre_y_ = t.max(y_, 1)pre_y = y# print(y_.shape)loss = loss_f(y_, pre_y)# print(y_.shape)acc = t.sum(pre_y_ == pre_y)loss.backward()opt.step()opt.zero_grad()if config.use_gpu:loss = loss.cpu()acc = acc.cpu()train_loss.append(loss.data)train_acc.append(acc)time_end = time.time()print("正式 批次 {}, Train 损失:{:.4f}, Train 准确率:{:.4f}, 训练时间: {}".format(batch + 1,np.mean(train_loss) / config.batch_size,np.mean(train_acc) / config.batch_size,(time_end - time_start)))model.train(False) # 关闭训练模式for batch, datas in tqdm(enumerate(iter(dataloader["test"]))):x, y = datasif config.use_gpu:x, y = x.cuda(), y.cuda()y_ = model(x)# print(x.shape,y.shape,y_.shape)_, pre_y_ = t.max(y_, 1)pre_y = y# print(y_.shape)loss = loss_f(y_, pre_y)acc = t.sum(pre_y_ == pre_y)if config.use_gpu:loss = loss.cpu()acc = acc.cpu()test_loss.append(loss.data)test_acc.append(acc)print("测试 批次 {}, 损失:{:.4f}, 准确率:{:.4f}".format(batch + 1, np.mean(test_loss) / config.batch_size,np.mean(test_acc) / config.batch_size))t.save(model, 'model/' + str(epoch + 1) + "_ttmodel.pkl") # 保存整个神经网络的结构和模型参数t.save(model.state_dict(), 'model/' + str(epoch + 1) + "_ttmodel_params.pkl") # 只保存神经网络的模型参数print('训练结束')#开始训练
if __name__ == "__main__":train(config.epochs)
调用代码:
import torch as t
import torchvision as tv
from PIL import Image
import matplotlib.pyplot as plt
from torch.autograd import Variable
import numpy as npbCuda = t.cuda.is_available() # 是否开启 GPU
bCuda = False # 不启用GPU 我的电脑不支持
device = t.device("cuda:0" if bCuda else "cpu")img_size = 32 # 图片大小,可以改# 对Tensor进行变换 颜色转换 mean=给定均值:(R,G,B) std=方差:(R,G,B)
normalize = tv.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
transform = tv.transforms.Compose([tv.transforms.Resize([img_size, img_size]), tv.transforms.CenterCrop([img_size, img_size]),tv.transforms.ToTensor(), normalize])# 分类数组
classes = ['凹下标志-0', '凸上标志-1', '打滑标志-2', '左弯标志-3', '右弯标志-4', '连续转弯标志-5', '00020-6', '00021-7', '00022-8', '00023-9']# 显示图片方法
def imshow(img):plt.imshow(img)plt.show()# 单张图片调用
def prediect(model, img_path, imgType, isShowSoftmax=False, isShowImg=False):t.no_grad()image_PIL = Image.open(img_path)# imshow(image_PIL)image_tensor = transform(image_PIL)# 以下语句等效于 img = torch.unsqueeze(image_tensor, 0)image_tensor.unsqueeze_(0)# 没有这句话会报错image_tensor = image_tensor.to(device)out = model(image_tensor)# 得到预测结果,并且从大到小排序_, indices = t.sort(out, descending=True)# 返回每个预测值的百分数percentage = t.nn.functional.softmax(out, dim=1)[0] * 100# 是否显示每个分类的预测值item = indices[0]if isShowSoftmax:for idx in item:ss = percentage[idx]value = ss.item();name = classes[idx]print('名称:', name, '预测值:', value)# 预测最大值_, predicted = t.max(out.data, 1)maxPredicted = classes[predicted.item()]maxAccuracy = percentage[item[0]].item()if imgType == maxPredicted:print('预测正确,预测结果:', maxPredicted, '预测值:', maxAccuracy)else:print('预测错误,正确结果:', imgType, ',预测结果:', maxPredicted, '预测值:', maxAccuracy, '图片:', img_path)if isShowImg:plt.imshow(image_PIL)plt.show()# 构建网络模型 resnet18
def get_model(num_classes):# resnet18 好像要下载什么的,忘记了,可以联系我model = tv.models.resnet18(pretrained=True)# 梯度什么的,电脑硬件支持,可以把下述代码屏蔽,则训练整个网络,最终准确率会上升,训练数据会变慢# for parma in model.parameters():# parma.requires_grad = Falsemodel.fc = t.nn.Sequential(t.nn.Dropout(p=0.3), t.nn.Linear(512, num_classes))return model# 测试集
def loadtestdata():path = "./imageData/test/"testset = tv.datasets.ImageFolder(path, transform=transform)testloader = t.utils.data.DataLoader(testset, batch_size=40, shuffle=True, num_workers=6)return testloader# 测试全部
def testAll(model):testloader = loadtestdata()dataiter = iter(testloader)images, labels = dataiter.next()print(labels)print('真实值: ', " ".join('%5s' % classes[labels[j]] for j in range(25))) # 打印前25个GT(test集里图片的标签)outputs = model(Variable(images))_, predicted = t.max(outputs.data, 1)print('预测值: ', " ".join('%5s' % classes[predicted[j]] for j in range(25)))# 打印前25个预测值imshow2(tv.utils.make_grid(images, nrow=5)) # nrow是每行显示的图片数量,缺省值为8def imshow2(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()if __name__ == '__main__':# 直接加载model = t.load('model/51_ttmodel.pkl')# 加载2 ,看官方的解释# model = get_model(classes.__len__()) # 10 分类数量# load_weights = t.load('model/51_ttmodel_params.pkl', map_location='cpu')# model.load_state_dict(load_weights)model = model.to(device) # GPUmodel.eval() # 运行模式# 测试全部图片testAll(model)# 测试一张图片# # 凹下标志-0# prediect(model,'imageData/test/00000/01160_00000.png', classes[0], False, False)# prediect(model,'imageData/test/00000/01160_00001.png', classes[0], False, False)# prediect(model,'imageData/test/00000/01160_00002.png', classes[0], False, False)# prediect(model,'imageData/test/00000/01798_00000.png', classes[0], False, False)# prediect(model,'imageData/test/00000/01798_00001.png', classes[0], False, False)# prediect(model,'imageData/test/00000/01798_00002.png', classes[0], False, False)## # 凸上标志-1# prediect(model,'imageData/test/00001/00029_00000.png', classes[1], False, False)# prediect(model,'imageData/test/00001/00029_00001.png', classes[1], False, False)# prediect(model,'imageData/test/00001/00029_00002.png', classes[1], False, False)# prediect(model,'imageData/test/00001/00079_00000.png', classes[1], False, False)# prediect(model,'imageData/test/00001/00079_00002.png', classes[1], False, False)# prediect(model,'imageData/test/00001/00079_00001.png', classes[1], False, False)## # 打滑标志-2# prediect(model,'imageData/test/00002/01503_00000.png', classes[2], False, False)# prediect(model,'imageData/test/00002/01503_00001.png', classes[2], False, False)# prediect(model,'imageData/test/00002/01503_00002.png', classes[2], False, False)# prediect(model,'imageData/test/00002/01515_00000.png', classes[2], False, False)# prediect(model,'imageData/test/00002/01515_00001.png', classes[2], False, False)# prediect(model,'imageData/test/00002/01515_00002.png', classes[2], False, False)## # 左弯标志-3# prediect(model,'imageData/test/00003/00207_00000.png', classes[3], False, False)# prediect(model,'imageData/test/00003/00207_00001.png', classes[3], False, False)# prediect(model,'imageData/test/00003/00207_00002.png', classes[3], False, False)# prediect(model,'imageData/test/00003/00211_00000.png', classes[3], False, False)# prediect(model,'imageData/test/00003/00211_00001.png', classes[3], False, False)# prediect(model,'imageData/test/00003/00211_00002.png', classes[3], False, False)# prediect(model,'imageData/test/00003/02664_00000.png', classes[3], False, False)# prediect(model,'imageData/test/00003/02664_00001.png', classes[3], False, False)# prediect(model,'imageData/test/00003/02664_00002.png', classes[3], False, False)## # 右弯标志-4# prediect(model,'imageData/test/00004/00214_00000.png', classes[4], False, False)# prediect(model,'imageData/test/00004/00214_00001.png', classes[4], False, False)# prediect(model,'imageData/test/00004/00214_00002.png', classes[4], False, False)# prediect(model,'imageData/test/00004/00282_00000.png', classes[4], False, False)# prediect(model,'imageData/test/00004/00282_00001.png', classes[4], False, False)# prediect(model,'imageData/test/00004/00282_00002.png', classes[4], False, False)# prediect(model,'imageData/test/00004/02567_00000.png', classes[4], False, False)# prediect(model,'imageData/test/00004/02567_00001.png', classes[4], False, False)# prediect(model,'imageData/test/00004/02567_00002.png', classes[4], False, False)# prediect(model,'imageData/test/00004/02660_00000.png', classes[4], False, False)# prediect(model,'imageData/test/00004/02660_00001.png', classes[4], False, False)# prediect(model,'imageData/test/00004/02660_00002.png', classes[4], False, False)## # 连续转弯标志-5# prediect(model,'imageData/test/00005/00575_00000.png', classes[5], False, False)# prediect(model,'imageData/test/00005/00575_00001.png', classes[5], False, False)# prediect(model,'imageData/test/00005/00575_00002.png', classes[5], False, False)# prediect(model,'imageData/test/00005/01893_00000.png', classes[5], False, False)# prediect(model,'imageData/test/00005/01893_00001.png', classes[5], False, False)# prediect(model,'imageData/test/00005/01893_00002.png', classes[5], False, False)# prediect(model,'imageData/test/00005/02225_00000.png', classes[5], False, False)# prediect(model,'imageData/test/00005/02225_00001.png', classes[5], False, False)# prediect(model,'imageData/test/00005/02225_00002.png', classes[5], False, False)### # 00020-6# prediect(model,'imageData/test/00020/00230_00000.png', classes[6], False, False)# prediect(model, 'imageData/test/00020/00230_00001.png', classes[6], True, True)# prediect(model,'imageData/test/00020/00230_00002.png', classes[6], False, False)# prediect(model,'imageData/test/00020/00231_00000.png', classes[6], False, False)# prediect(model,'imageData/test/00020/00231_00001.png', classes[6], False, False)# prediect(model,'imageData/test/00020/00231_00002.png', classes[6], False, False)## # 00021-7# prediect(model, 'imageData/test/00021/00375_00000.png', classes[7], False, False)# prediect(model, 'imageData/test/00021/00375_00001.png', classes[7], False, False)# prediect(model, 'imageData/test/00021/00375_00002.png', classes[7], False, False)# prediect(model, 'imageData/test/00021/00478_00000.png', classes[7], False, False)# prediect(model, 'imageData/test/00021/00478_00001.png', classes[7], False, False)# prediect(model, 'imageData/test/00021/00478_00002.png', classes[7], False, False)## # 00022-8# prediect(model, 'imageData/test/00022/00020_00000.png', classes[8], False, False)# prediect(model, 'imageData/test/00022/00020_00001.png', classes[8], False, False)# prediect(model, 'imageData/test/00022/00020_00002.png', classes[8], False, False)# prediect(model, 'imageData/test/00022/00048_00000.png', classes[8], False, False)# prediect(model, 'imageData/test/00022/00048_00001.png', classes[8], False, False)# prediect(model, 'imageData/test/00022/00048_00002.png', classes[8], False, False)## # 00023-9# prediect(model, 'imageData/test/00023/00465_00000.png', classes[9], False, False)# prediect(model, 'imageData/test/00023/00465_00001.png', classes[9], False, False)# prediect(model, 'imageData/test/00023/00465_00002.png', classes[9], False, False)# prediect(model, 'imageData/test/00023/00535_00000.png', classes[9], False, False)# prediect(model, 'imageData/test/00023/00535_00001.png', classes[9], False, False)# prediect(model, 'imageData/test/00023/00535_00002.png', classes[9], False, False)