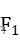目录
前言
课题背景和意义
实现技术思路
一、相关工作
二、域名特征选取及方案设计
三、实验与分析
四、总结
实现效果图样例
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于DGA 恶意域名的检测算法
课题背景和意义
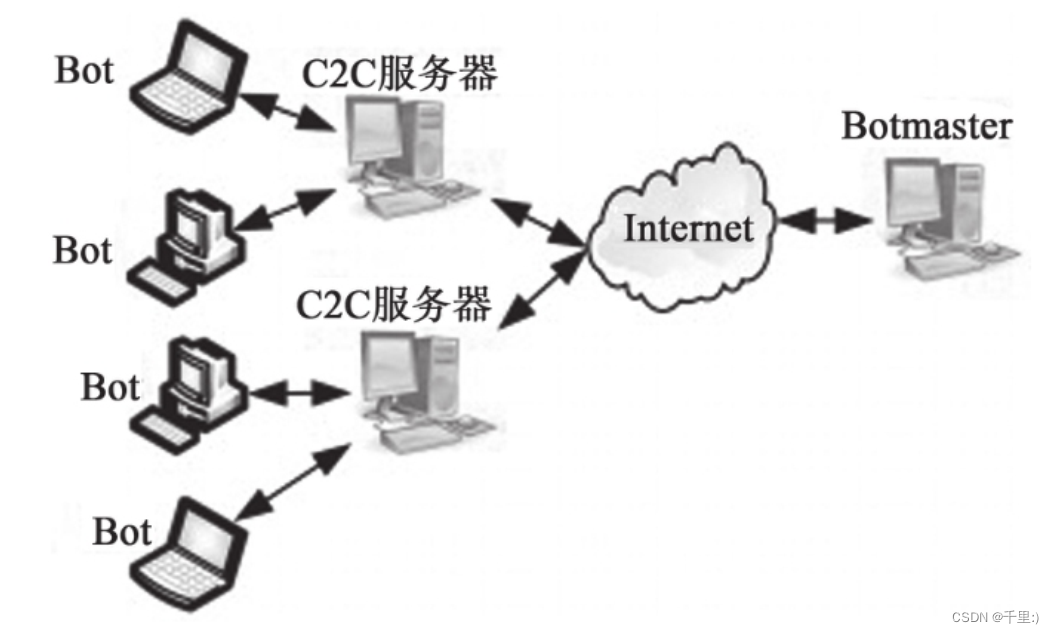
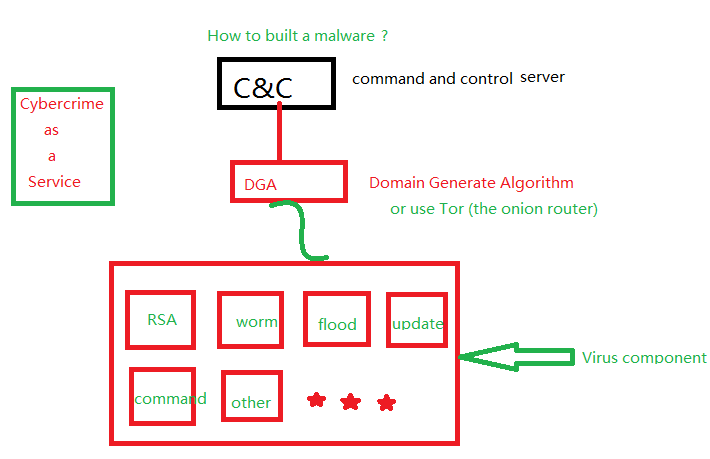
域名解析系统已经发展成为了国际互联网中一个完全不可能被忽视且重要的一个关键的基础网络设施和信息服务 , 难以避 免被域名利用者非法利用。在深入地分析研究了网络僵尸病毒网络与 DGA 等恶意域名的应用之后 , 对当前网络市场上各种主流恶意 域名安全检测解决技术特点进行了分析比较 , 并初步提出了一种基于字符特征来改善网络恶意域名检测技术的理论框架。域名解析系统 (DomainNameSystem,dns) 作为目前互联网 最重要的信息技术和核心信息基础服务设施之一 , 把难以被 他人记忆的互联网协议地址通过映射成为容易被他人记忆的 域名。许多网络服务都是基于域名服务而进行。 恶意网站域名指的是任何滥用该网站域名进行任何恶意 操作的网站域名 , 主要含义指的是包括网站内容为包括传播 各种恶意软件、促进恶意命令和控制 (commandandcontrol,c&c) 服务器进行通信 , 发送恶意垃圾邮件、托管网络诈骗和进 行网络安全钓鱼的恶意网页等。 恶意域名对于人们进行网络活动中的经济和个人信息都 有很大的威胁 , 域名安全检测也成为信息安全里的重要研究 内容。
实现技术思路
一、相关工作
实现方法
当 前,有两种主要的方法来实现恶意域名:fastflux 和 domain-flux。fast-flux方法是将连续执行每个域 名和输入主机 IP 地址的快速映射从而对输入 IP 进行初始 限制地址配置和其他安全技术策略丢弃或暂时丢弃,这可 能导致安全专业人员无法在短时间内准确,快速地定位攻
击服务器的恶意黑客的网络地理中心。domain-flux有效 保护攻击者实际执行的候选命令,并完全控制整个服务器 (commandandcontrol,c & c),以防止恶意的候选域名在完 全受控的虚拟机上被访问。
相关研究
恶意网址检测方面主要有 2 个比较流行的做法 : 第一个 是直接维护一个黑名单 , 第二个是用 data-driven 的方式 , 即 设计良好的特征 + 机器学习分类模型来实现对恶意网址的自 动分类。接下来主要为大家介绍一种基于机器学习的恶意网 页检测技术。
一些现有的研究项目及其工作主要使用一些所谓的机 器和深度学习技术,这些技术主要包括决策树,支持向量机 (helper vector machine,svm),聚类等。使用决策 树算法基于被动 DNS 数据构建分类器。文献 [9] 从分析 DNS 流量和网络数据的角度总结了周期性域名发现的特征,并重 构了 J48 决策树进行分类。
当前,用于检测和处理现有的域名检测的各种方法具有 其自身的特性。但是,无论是公司顶级域名服务器,权威顶 级域名服务器还是带有递归域名解析器的域名服务器,都很 难获得域名流量数据和解析数据。
二、域名特征选取及方案设计
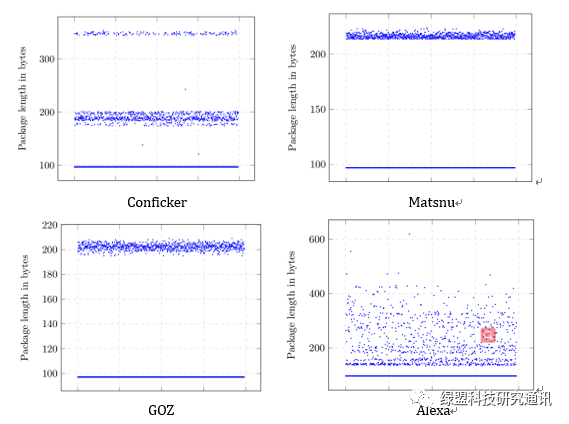
白样本:采用Alexa top1m
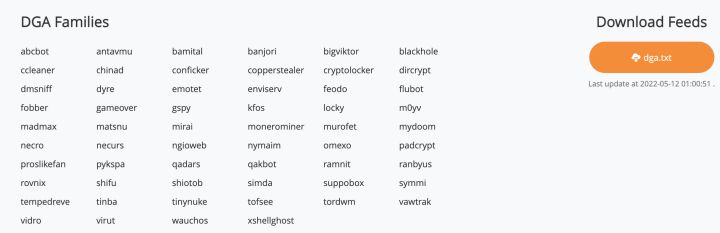
黑样本:DGA - Netlab OpenData Project
域名字符特性分析
由于 DGA 域名算法生成的恶意注册域名经常使用字符 的一些随机字母和数字组合,在字符的概率分布方面,这些 字符通常与善意域名有显着差异。选取字符特征有:字符长 度、域名后缀、数字个数、数字比率、连续数字最大长度、 连续字母最大长度、连续相同字母最大长度、最长元音距、 域名字符熵值九个特征。
特征改进
基于一个开放源代码的分词数据库,对域名的字 符结构进行了全面的分析,并从英语域名字符组中提取了 最长和可能最特殊的含义。例如,一个域名,名称为 google. com,通常由域名 google 和 com 的两个单字符子字符串组成。 则该字符串长度为 2。将选取特征中连续字母最大长度改为 拆词后字符串长度。特征改进前后如图所示,对比正负样 本区分更明显。
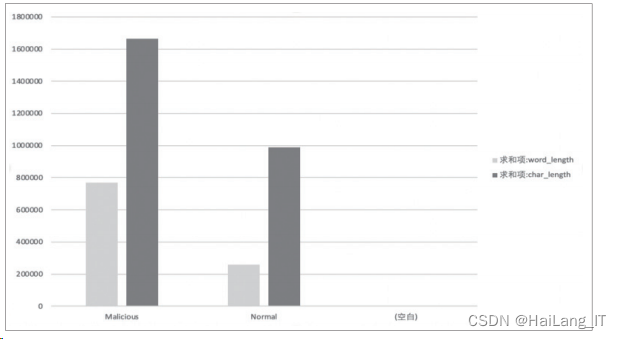
数据分析特征提取
黑白样本不均衡,保留类别数目大于3000的家族样本,并使用随机下采样方式使黑白样本均衡。
仅做测试数据足够,而且高维文本特征表示,近乎两两正交,使用SMOTE类似方法过采样效果甚微。
最终数据分布如下:

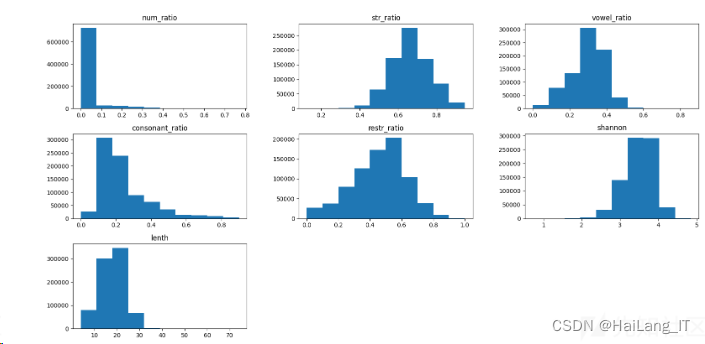
DGA算法作为随机域名生成算法,它生成的域名与正常域名相比随机性更强。可以从如下几个方面考虑特征:
1、数字/字母 占比
2、元音字母/辅音字母 占比(合法域名一般由正常字母组成包含元音字母多,可读行强)
3、字母 重复出现次数占比
4、域名长度
5、香农熵(可以判断域名随机性)
特征数据分布图可以大概看出特征区分度:
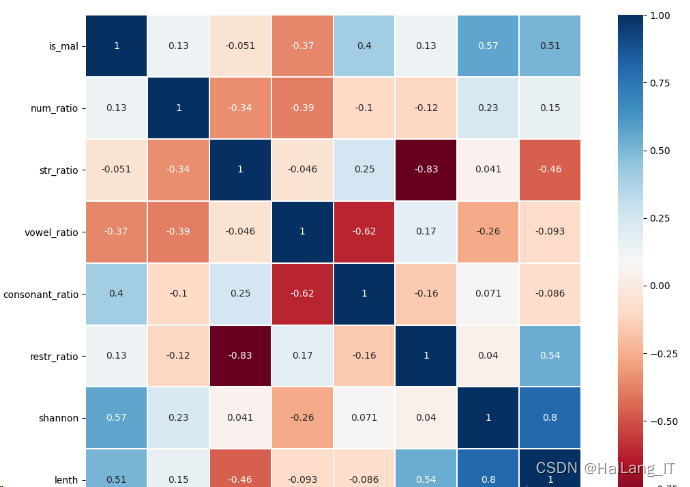
特征相关性分布混淆矩阵:
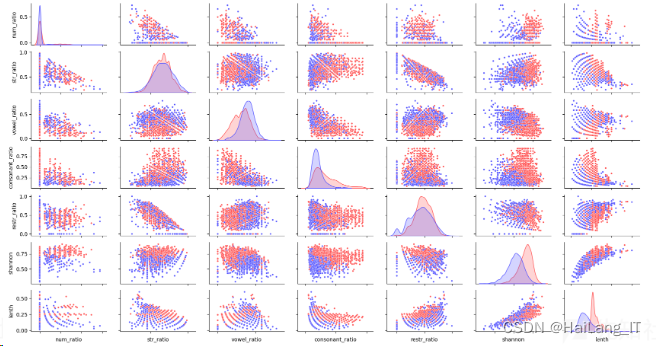
特征关联性分布散点图:
分类算法选择
本次实验中,使用一个目前应用十分广泛的算法 支持向量机 (supportvectormachine,svm),这个算法对正常域名 和 DGA 域名之间的特征差异性关系进行了精确区分 ,svm 分 类算法的主要分类理论依据之一其实就是特征结构分类风险 的全局最小化。svm 分类算法结构是一种非常严谨的分类数 学理论推导和重要的分类理论数据基础 , 分类的算法正确率 高、稳定性好、泛化分类能力强 , 可以很好地快速得到全局 最优值的解。
三、实验与分析
数据集
本次实验的数据集由正常域名和恶意域名两个组成部 分 , 共二十多万。使用 alexa 的排名相对比较靠前的域名作 为正常域名。通过对网络上所公开的域名黑名单 进行列表分析 , 并且将去重的域名进行列表分析形成本文的 域名样本。正负样本比例约为一比一。其中模型的训练数据 占 2/3, 测试数据占 1/3。
实验对比
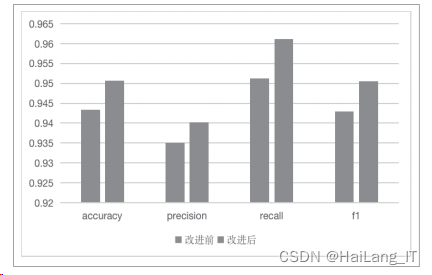
本文与特征改进前的方法进行了对比试验,对比结果如 图所示。
四、总结
基于 domain-flux 恶意域名的异常 检测的系统,结合了九个主要特征,主要实现了基于 svm 算 法检测的恶意域名的异常检测方案。该方法的检测准确率, 查全率和 Fl 值均达到 95%,具有良好的检测效果。另外, 本文的工作也可以离线完成,不再接收 DNS 流量,数据收 集简单。该检测解决方案解决了检测大量数据中的问题,具 有良好的实用价值。 未来,改进的技术方向将主要针对不合理使用计算资源 来优化总体状况,并对检测到的恶意域名进行第二次调查以 提高其准确性。
实现效果图样例
使用分类器分类结果:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!