文章目录
- Shell基础
- Shell本身
- Shell脚本
- 第一个Shell脚本
- 运行Shell脚本有三种方式
- Shell bash和sh区别
- .sh文件与.bash文件
- Shell内置变量命令
- eval
- echo
- 实例分析
- .sh脚本自动执行文件
- 一个.sh执行多个程序
- 执行多个.sh
Shell基础
Shell本身
Shell 是一个用 C 语言编写的程序,它是用户使用 Linux 的桥梁。Shell 既是一种命令语言,又是一种程序设计语言。
Shell 是指一种应用程序,这个应用程序提供了一个界面,用户通过这个界面访问操作系统内核的服务。
Ken Thompson 的 sh 是第一种 Unix Shell,Windows Explorer 是一个典型的图形界面 Shell。
shell 是用户登录时看到的主界面,用来启动其他应用程序。
在 UNIX 圈子中,shell 专门用于表示命令行 shell,以输入想要启动的应用程序名,后面跟随想要操作的文件或其他对象的名称,按下 Enter 键。其他非 UNIX 的环境不用 shell 这个词;基于视窗界面的操作系统使用“窗口管理器”和“桌面环境”而不是 shell。
有很多种不同的 UNIX shell。常见的包括 bash(大多数 Linux 预装)、zsh(强大且可随心定制)、fish(更强调简洁)
Shell脚本
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。
业界所说的 shell 通常都是指 shell 脚本,但读者朋友要知道,shell 和 shell script 是两个不同的概念。
由于习惯的原因,简洁起见,本文出现的 “shell编程” 都是指 shell 脚本编程,不是指开发 shell 自身。
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- Bourne Again Shell(/bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。
#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
第一个Shell脚本
打开文本编辑器(可以使用 vi/vim 命令来创建文件),新建一个文件 test.sh,扩展名为 sh(sh代表shell),扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了。
输入一些代码,第一行一般是这样:
#!/bin/bash
echo "Hello World !"
#! 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。
echo 命令用于向窗口输出文本。
回车换行导致command not found:习惯用回车使代码变得清晰,但是会让shell脚本输出:command not found
#!/bin/bashecho "Hello World !"
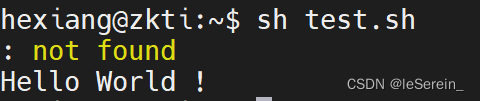
解决:
sublime text
View->Line endings->Unix
editplus
Document->File Fomart(FR/LF)->Change File Format
MobaTextEditor
Format -> UNIX
运行Shell脚本有三种方式
1、作为可执行程序
将上面的代码保存为 test.sh,并 cd 到相应目录:
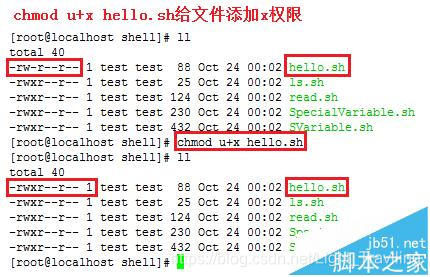
chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本
注意,一定要写成 ./test.sh,而不是 test.sh,运行其它二进制的程序也一样,直接写 test.sh,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 test.sh 是会找不到命令的,要用 ./test.sh 告诉系统说,就在当前目录找。
2、作为解释器参数
这种运行方式是,直接运行解释器,其参数就是 shell 脚本的文件名,如:
/bin/sh test.sh
/bin/php test.php
这种方式运行的脚本,不需要在第一行指定解释器信息,写了也没用。
3、直接用sh(这种办法不需要文件具备可执行的权限也可运行)
sh ./test.sh
Shell bash和sh区别
sh 遵循POSIX规范:“当某行代码出错时,不继续往下解释”。bash 就算出错,也会继续向下执行。
POSIX表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX )。POSIX标准意在期望获得源代码级别的软件可移植性。换句话说,为一个POSIX兼容的操作系统编写的程序,应该可以在任何其它的POSIX操作系统上编译执行。
sh 脚本:
#!/bin/sh
source err
echo "test sh"
结果为:
testsh.sh: 2: testsh.sh: source: not found
bash 脚本:
#!/bin/bash
source err
echo "test sh"
结果为:
testsh.sh: 2: testsh.sh: source: not found
test sh
sh 跟bash的区别,实际上是bash有没开启POSIX模式的区别。
简单说,sh是bash的一种特殊的模式,sh就是开启了POSIX标准的bash, /bin/sh 相当于 /bin/bash --posix。
.sh文件与.bash文件
.sh文件和.bash文件都是脚本文件,.sh文件对应shell解释器,.bash对应bash解释器。大多数情况下,两者可以视为相同。
Shell内置变量命令
eval
命令格式:eval args
功能:当Shell程序执行到eval语句时,Shell读入参数args,并将它们组合成一个新的命令,然后执行。
[root@zabbix ~]# cat eval.sh
echo $1 $2 -- 打印输出第一第二个参数
echo $# -- 打印输出参数个数
eval "echo \$$#" -- 二次解析"echo $2"为一个命令,输出结果
[root@zabbix ~]# sh eval.sh arg1 arg2
arg1 arg2
2
arg2
eval “$(conda shell.bash hook)” : 用shell脚本激活conda虚拟环境
echo
命令格式:echo args #<==可以是字符串和变量的组合。功能说明:将echo命令后面args指定的字符串及变量等显示到标准输出。
实例分析
#!/bin/sh## uncomment for slurm
##SBATCH -p gpu
##SBATCH --gres=gpu:8
##SBATCH -c 80export PYTHONPATH=./
eval "$(conda shell.bash hook)"
##conda activate yolo_hx # pytorch 1.4.0 env
PYTHON=pythondataset=$1
exp_name=$2
exp_dir=exp/${dataset}/${exp_name}
model_dir=${exp_dir}/model
result_dir=${exp_dir}/result
config=config/${dataset}/${dataset}_${exp_name}.yaml
now=$(date +"%Y%m%d_%H%M%S")mkdir -p ${model_dir} ${result_dir}
cp tool/train.sh tool/train.py tool/test.sh tool/test.py ${config} ${exp_dir}export PYTHONPATH=./
$PYTHON -u ${exp_dir}/train.py \--config=${config} \2>&1 | tee ${model_dir}/train-$now.log
A. python -u:python执行脚本输出到屏幕结果直接重定向到日志文件的情况下,使用-u参数,这样将标准输出的结果不经缓存直接输出到日志文件。
B. 2>&1 | tee train-$now.log t命令解析
2>&1应该分成两个部分来看,一个是2>以及另一个是&1,
其中2>就是将标准出错重定向到某个特定的地方;&1是指无论标准输出在哪里。
所以2>&1的意思就是说无论标准出错在哪里,都将标准出错重定向到标准输出中。
有时候希望将错误的信息重新定向到输出,就是将2的结果重定向至1中就有了”2>1”这样的思路,如果按照上面的写法,系统会默认将错误的信息(STDERR)2重定向到一个名字为1的文件中,而非所想的(STDOUT)中。因此需要加&进行区分。就有了 2>&1 这样的用法
| 管道
管道的作用是提供一个通道,将上一个程序的标准输出重定向到下一个程序作为下一个程序的标准输入。
通常使用管道的好处是一方面形式上简单,另一方面其执行效率要远高于使用临时文件。
这里使用管道的目的是将make程序的输出重定向到下一个程序,其最终目的是用来将输出log存入文件中。
tee是用来干什么的?
tee从标准输入中读取,并将读入的内容写到标准输出以及文件中。
所以这里tee命令的作用是将数据读入并写到标准输出以及log.txt中。
之所以要将编译产生的log保存到log.txt中,其原因是你的标准输出的缓存可能是有限制的,而你编译程序产生的log可能会很多,这样很可能会造成log不完整;
其目的是当程序发生编译错误的时候,我们可以从log.txt中看到完整的编译log,这样方便查找编译错误。
C. PYTHONPATH=./ 的作用
将当前所处文件加入系统环境中
.sh脚本自动执行文件
有时候我需要很多超参数参数,跑出来的实验结果。这个时候比如我有两张卡,要跑十个实验,我可以预先设定好超参数并且写到.sh文件里,就可以实现这个程序执行完自动执行下一个,而不用人盯着结束了再放到卡上跑(因为一张GPU同时加速两个程序,没有一个一个放上去快,在利用率都占满的情况下)
一个.sh执行多个程序
在一个.sh文件里,$!来表示后台运行的最后一个进程的 ID 号,同时挂到后台后,wait挂到后台的进程,两个结束后才进行下面的操作。
python Vgg16_CIFAR100.py --device 0 --lr 0.1 &
PID1=$!;
python Vgg16_CIFAR100.py --device 1 --lr 0.01 &
PID2=$!;
wait ${PID1} && wait ${PID2}python ResNet20_CIFAR100.py --device 0 --lr 0.1 &
PID1=$!;
python ResNet20_CIFAR100.py --device 1 --lr 0.01 &
PID2=$!;
wait ${PID1} && wait ${PID2}
执行多个.sh

1. Shell 教程
2. shell—解决shell脚本中回车换行导致command not found
3. Shell bash和sh区别
4. shell内置变量命令:echo、eval、exec、export、read、shift
5. Shell 输入/输出重定向
6. Linux添加PYTHONPATH方法以及3种修改环境变量方法
7. Shell 脚本中 ‘$’ 符号的多种用法
8. Shell(Bash)多命令顺序执行方法详解