三大框架的基础知识
1,hibernate的工作原理及为什么要用?
2,为什么要用?
3,Hibernate是如何延迟加载?
4,Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
5,说下Hibernate的缓存机制
6. 如何优化Hibernate?
1.使用双向一对多关联,不使用单向一对多
2.灵活使用单向一对多关联
3.不用一对一,用多对一取代
4.配置对象缓存,不使用集合缓存
5.一对多集合使用Bag,多对多集合使用Set
6. 继承类使用显式多态
7. 表字段要少,表关联不要怕多,有二级缓存撑腰
7,阐述struts2的执行流程。
Struts 2框架本身大致可以分为3个部分:核心控制器FilterDispatcher、业务控制器Action和用户实现的企业业务逻辑组件。
核心控制器FilterDispatcher是Struts 2框架的基础,包含了框架内部的控制流程和处理机制。业务控制器Action和业务逻辑组件是需要用户来自己实现的。用户在开发Action和业务逻辑组件的同时,还需要编写相关的配置文件,供核心控制器FilterDispatcher来使用。 Struts 2的工作流程相对于Struts 1要简单,与WebWork框架基本相同,所以说Struts 2是WebWork的升级版本。
基本简要流程如下:
1、客户端浏览器发出HTTP请求。
2、根据web.xml配置,该请求被FilterDispatcher接收。
3、根据struts.xml配置,找到需要调用的Action类和方法, 并通过IOC方式,将值注入给Aciton。
4、Action调用业务逻辑组件处理业务逻辑,这一步包含表单验证。
5、Action执行完毕,根据struts.xml中的配置找到对应的返回结果result,并跳转到相应页面。
6、返回HTTP响应到客户端浏览器。
8,Struts工作机制?为什么要使用Struts?
工作机制: Struts的工作流程
在web应用启动时就会加载初始化ActionServlet,ActionServlet从 struts-config.xml文件中读取配置信息,把它们存放到各种配置对象 当ActionServlet接收到一个客户请求时,将执行如下流程.
-(1)检索和用户请求匹配的ActionMapping实例,如果不存在,就返回请求路径无效信息;
-(2)如果ActionForm实例不存在,就创建一个ActionForm对象,把客户提交的表单数据保存到ActionForm对象中;
-(3)根据配置信息决定是否需要表单验证.如果需要验证,就调用ActionForm的validate()方法;
-(4)如果ActionForm的validate()方法返回null或返回一个不包含ActionMessage的ActuibErrors对象, 就表示表单验证成功;
-(5)ActionServlet根据ActionMapping所包含的映射信息决定将请求转发给哪个Action,如果相应的 Action实例不存在,就先创建这个实例,然后调用Action的execute()方法;
-(6)Action的execute()方法返回一个ActionForward对象,ActionServlet在把客户请求转发给 ActionForward对象指向的JSP组件;
-(7)ActionForward对象指向JSP组件生成动态网页,返回给客户;
为什么要用:
JSP、Servlet、JavaBean技术的出现给我们构建强大的企业应用系统提供了可能。但用这些技术构建的系统非常的繁乱,所以在此之上,我们需要一个规则、一个把这些技术组织起来的规则,这就是框架,Struts便应运而生。 基于Struts开发的应用由3类组件构成:控制器组件、模型组件、视图组件
9. Struts的设计模式
MVC模式: web应用程序启动时就会加载并初始化ActionServler。用户提交表单时,一个配置好的ActionForm对象被创建,并被填入表单相应的数据,ActionServler根据Struts-config.xml文件配置好的设置决定是否需要表单验证,如果需要就调用ActionForm的 Validate()验证后选择将请求发送到哪个Action,如果Action不存在,ActionServlet会先创建这个对象,然后调用 Action的execute()方法。Execute()从ActionForm对象中获取数据,完成业务逻辑,返回一个ActionForward对象,ActionServlet再把客户请求转发给ActionForward对象指定的jsp组件,ActionForward对象指定的jsp生成动态的网页,返回给客户。
MVC模式知识点 ——补充:
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写,一种软件设计典范,用一种业务逻辑、数据、界面显示分离的方法组织代码,将业务逻辑聚集到一个部件里面,在改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑。MVC被独特的发展起来用于映射传统的输入、处理和输出功能在一个逻辑的图形化用户界面的结构中。
MVC开始是存在于桌面程序中的,M是指业务模型,V是指用户界面,C则是控制器,使用MVC的目的是将M和V的实现代码分离,从而使同一个程序可以使用不同的表现形式。比如一批统计数据可以分别用柱状图、饼图来表示。C存在的目的则是确保M和V的同步,一旦M改变,V应该同步更新。


spring工作机制及为什么要用?
1.spring mvc所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责负责对请求进行真正的处理工作。
2.DispatcherServlet查询一个或多个HandlerMapping,找到处理请求的Controller.
3.DispatcherServlet请请求提交到目标Controller
4.Controller进行业务逻辑处理后,会返回一个ModelAndView
5.Dispathcher查询一个或多个ViewResolver视图解析器,找到ModelAndView对象指定的视图对象
6.视图对象负责渲染返回给客户端
为什么用:
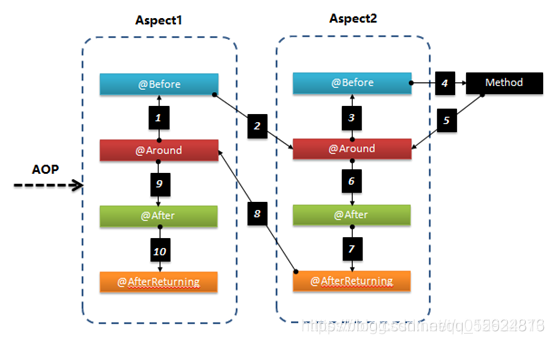
{AOP 让开发人员可以创建非行为性的关注点,称为横切关注点,并将它们插入到应用程序代码中。使用 AOP 后,公共服务 (比如日志、持久性、事务等)就可以分解成方面并应用到域对象上,同时不会增加域对象的对象模型的复杂性。 IOC 允许创建一个可以构造对象的应用环境,然后向这些对象传递它们的协作对象。正如单词 倒置 所表明的,IOC 就像反 过来的 JNDI。没有使用一堆抽象工厂、服务定位器、单元素(singleton)和直接构造(straight construction),每一个对象都是用其协作对象构造的。因此是由容器管理协作对象(collaborator)。 Spring即使一个AOP框架,也是一IOC容器。 Spring 最好的地方是它有助于您替换对象。有了 Spring,只要用 JavaBean 属性和配置文件加入依赖性(协作对象)。然后可以很容易地在需要时替换具有类似接口的协作对象。}
三大框架顾名思义就是非常有名的Struts2 ,Hibernate,Spring,
框架整合的方法很多,现在我写一个非常简单的整合过程,相信大家一看就会!
这里使用的struts-2.2.1.1、hibernate-3.2.0、spring2.5.6
第一步,搭建Struts2环境
1、导入struts2的jar包(直接把struts-blank项目下的依赖库coypy到自己项目中)
2、 配置web.xml,增加struts2提供的过滤器(参考struts-blank项目)
 View Code
View Code 3、建立包:com.qcf.struts.test,并增加普通java类,代码如下:
View Code 4、在src下增加struts.xml,并增加FirstAction类的配置内容:
View Code 5、增加ok.jsp页面,用来显示FirstAction中的属性msg:
View Code 测试成功!
第二步:搭建Hibernate环境
1、导入hibernate所需要的基本的jar包

2、添加hibernate.cfg.xml配置文件
打开etc目录,将hibernate.cfg.xml拷贝到项目src下
修改配置文件hibernate.cfg.xml内容,结合etc/hibernate.properties(文件中搜索”mysql”),完成后配置内容如下:
View Code 3、新建pojo类(Plain Old Java Objects 简单的java对象,实际上就是我们讲的普通javabean对象):User
View Code 4、增加映射文件User.hbm.xml(写法可以参考:eg/User.hbm.xml)
映射文件hbm.xml说明了pojo类和表的对应关系,以及pojo类中属性和表中字段的对应关系。
注:本映射文件增加到跟pojo同一个包中
View Code 5、在hibernate.cfg.xml中增加User.hbm.xml文件的配置,让hibernate知道本映射关系。在<session-factory>元素下增加:
<mapping resource="com/qcf/hib/bean/User.hbm.xml"/>
6、修改hibernate.cfg.xml文件,在<session-factory>下增加hbm2ddl.auto的配置:
<property name="hibernate.hbm2ddl.auto">update</property>
– create-drop: 运行时,先创建,运行完,在删除。
– create:每次运行前都会删除已有的。在创建。 测试时,可以使用create.
– update:映射文件和表。不会重新创建表及不会重新执行ddl语句,只会更新表中的记录。
– validate:看映射文件和表是不是对应,如果不对应,他也不会更新,会报错。经常用它,保险一些。
7、增加Test.java测试类:
View Code 8、 上一次执行,我们发现表创建成功但是数据记录并没有插入表中。jdbc是自动提交,autocommit。hibernate缺省是false. 因此,我们必须很明确的开启事务才行。我们将Test.java文件内容修改如下:
View Code 测试成功,数据库中也有相应的数据添加成功!
第三步:搭建Spring环境
1、导入Spring所需要的jar包
spring.jar这一个即可!
2、写一个测试类
View Code 3、增加配置文件beans.xml,内容如下:
View Code
通过上面的配置文件,spring框架知道了UserDao类的存在!可以通过反射机制自动将UserDao类的对象new出! 所以注意托管给spring的类必须符合基本的javabean规范:
1. 如果有属性,则必须有相应的get/set方法。
2. 必须要无参的构造器 4、建立Test.java类
View Code 5、上面的代码中,我们可以使用context.getBean("userDao")代替了new UserDao(这样的代码,也就是spring内部有个工厂类,替我们完成了new对象的操作!而这个工厂类是通过读取beans.xml文件知道了字符串”userDao”和com.sxt.test.UserDao类之间的关系!
直接运行Test.java类即可。
第四步:已经将三个框架各自搭建完毕。现在先整合Struts和spring
整合struts2和spring非常简单只需两步:
1、在web.xml下面添加一个spring的过滤器(添加到最上面,在struts2的配置文件上面)

1 <listener> 2 <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> 3 </listener> 4 <context-param> 5 <param-name>contextConfigLocation</param-name> 6 <param-value>classpath:application.xml</param-value> 7 </context-param>
2、添加一个struts-spring.plus的插件,这个可以再struts官方提供的jar中即可找到
注:action中的class不用填写全名,直接写spring中注册的id即可,如:testAction
1 <package name="default" namespace="/" extends="struts-default"> 2 <action name="testAction" class="testAction"> 3 <result name="success">index.jsp</result> 4 </action> 5 </package>
第五步:整合spring和hibernate
1、首先将web.xml添加头文件
1 <?xml version="1.0" encoding="UTF-8"?> 2 <beans xmlns="http://www.springframework.org/schema/beans" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xmlns:aop="http://www.springframework.org/schema/aop" 5 xmlns:tx="http://www.springframework.org/schema/tx" 6 xmlns:context="http://www.springframework.org/schema/context" 7 xsi:schemaLocation=" 8 http://www.springframework.org/schema/beans 9 http://www.springframework.org/schema/beans/spring-beans-2.5.xsd 10 http://www.springframework.org/schema/tx 11 http://www.springframework.org/schema/tx/spring-tx-2.5.xsd 12 http://www.springframework.org/schema/aop 13 http://www.springframework.org/schema/aop/spring-aop-2.5.xsd 14 http://www.springframework.org/schema/context 15 http://www.springframework.org/schema/context/spring-context-2.5.xsd 16 ">
2、配置sessionFactory(配置了C3P0数据库连接池)
<!-- 导入jdbc.properties --><context:property-placeholder location="classpath:jdbc.properties"/><!-- 配置sessionfactory --><bean name="sessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean"><!-- 配置application.xml路径 --><property name="configLocation" value="classpath:hibernate.cfg.xml"></property><!-- 配置c3p0连接池 --><property name="dataSource"><bean class="com.mchange.v2.c3p0.ComboPooledDataSource"><!-- 数据库连接信息 --><property name="driverClass" value="${driverClass}"></property><property name="jdbcUrl" value="${jdbcUrl}"></property><property name="user" value="${user}"></property><property name="password" value="${password}"></property><!-- 其它配置 --><!-- 数据库初始化时获取三个链接,取值应该在min --><property name="initialPoolSize" value="3"></property><!-- 连接池中保留的最小连接数 --><property name="minPoolSize" value="3"></property><!-- 连接池中保留的最大连接数 --><property name="maxPoolSize" value="10"></property><!-- 当连接池中连接耗尽时c3p0一次获取的连接数 --><property name="acquireIncrement" value="3"></property><!-- 配置数据源内加载的preparestatement数量 --><property name="maxStatements" value="3"></property><!-- 单个连接所拥有的最大statments缓存数 --><property name="maxStatementsPerConnection" value="3"></property><!-- 设置最大空闲时间不使用自动丢弃,如果为0永远不丢弃 --><property name="maxIdleTime" value="1800"></property></bean></property></bean>
3、配置事务管理(XML)
1 <!-- 配置声明事务管理 --> 2 <bean id="txManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager"> 3 <property name="sessionFactory" ref="sessionFactory"></property> 4 </bean> 5 <!-- AOP核心配置 --> 6 <aop:config> 7 <!-- 定义aop切面 --> 8 <aop:pointcut expression="execution(public * com.qcf.test.*.*(..))" id="testa"/> 9 <aop:advisor advice-ref="txadvice" pointcut-ref="testa"/> 10 </aop:config> 11 <!-- 定义切割方法 --> 12 <tx:advice id="txadvice" transaction-manager="txManager"> 13 <tx:attributes> 14 <tx:method name="save*" propagation="REQUIRED"/> 15 </tx:attributes> 16 </tx:advice> 17 <!-- -->
配置事务(annotation)
1 <!-- 自动扫面 2 --> 3 <context:component-scan base-package="com.qcf"></context:component-scan> 4 5 6 <!-- 配置事务 --> 7 <bean id="txManager" class="org.springframework.orm.hibernate3.HibernateTransactionManager"> 8 <property name="sessionFactory" ref="sessionFactory"></property> 9 </bean> 10 11 <!-- annotation配置事务 --> 12 <tx:annotation-driven transaction-manager="txManager"/>
测试方法:
View Code 4、配置HibernateTemplate
HibernateTemplate类可让我们将Hibernate的使用模板化,使我们对hibernate的调用更加简单!使用他,我们只需要在配置文件中增加:
1 <!-- 配置hibernatetempter --> 2 <bean id="hibernateTemplate" class="org.springframework.orm.hibernate3.HibernateTemplate"> 3 <property name="sessionFactory" ref="sessionFactory"></property> 4 </bean> 5
hibernateTemplate常用方法:
◦ void delete(Object entity):删除指定持久化实例
◦ deleteAll(Collection entities):删除集合内全部持久化类实例
◦ find(String queryString):根据HQL查询字符串来返回实例集合
◦ get(Class entityClass, Serializable id):根据主键加载特定持久化类的实例
◦ save(Object entity):保存新的实例
◦ saveOrUpdate(Object entity):根据实例状态,选择保存或者更新
◦ update(Object entity):更新实例的状态,要求entity是持久状态
◦ setMaxResults(int maxResults):设置分页的大小(无setFirstResult方法)
HibernateTemplate的典型用法:
-
- 需要直接获得session对象的处理方式(比如:分页处理)
1 hibernateTemplate.execute(new HibernateCallback() { 2 3 public Object doInHibernate(Session session) throws HibernateException, 4 SQLException { 5 // TODO Auto-generated method stub 6 session.save(new User(0, "lisi", 19)); 7 return null; 8 } 9 });
2. 不需要直接获得session对象的情况
1 public List<User> getAllUser(){ 2 List<User> list=hibernateTemplate.find("from User"); 3 for (int i = 0; i < list.size(); i++) { 4 System.out.println(list.get(i).getId()); 5 6 } 7 8 List list2 = hibernateTemplate.find("from User where name=? and id=?", new Object[]{"zhangsan",1}); 9 for (int i = 0; i < list2.size(); i++) { 10 System.out.println(list2.get(i).toString()); 11 } 12 13 return null; 14 }
5、HibernateDaoSupport
封装了HibernateTemplate!常见用法如下:
public class UserDaoImpl3 extends HibernateDaoSupport {public void add(User u) {this.getHibernateTemplate().save(u);} } public class UserDaoImpl3 extends HibernateDaoSupport {public void add(User u) {Session s = this.getSession();s.save(u);releaseSession(s); //手动释放session资源 } }
6、JDBCTemplate的使用
dbcTemplate类是spring为了让我们更加容易使用jdbc而提供的封装。JdbcTemplate对jdbc操作做了简单的封装。内部也使用了类似HibernateTemplate中使用的模板方法模式。JdbcTemplate在工作中用的不多。本节为自学内容,目的是让大家开阔眼界。
要使用JdbcTemplate,我们必须要在spring中增加配置:
1 <!--配置一个JdbcTemplate实例--> 2 <bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"> 3 <property name="dataSource" ref="dataSource"/> 4 </bean>
测试类如下:
View Code 7、OpenSessionInView管理session
OpenSessionInViewFilter是Spring提供的一个针对Hibernate的一个支持类,其主要意思是在发起一个页面请求时打开 Hibernate的Session,一直保持这个Session,直到这个请求结束,具体是通过一个Filter来实现的。
由于Hibernate引入了Lazy Load特性,使得脱离Hibernate的Session周期的对象如果再想通过getter方法取到其关联对象的值,Hibernate会抛出一个 LazyLoad的Exception。所以为了解决这个问题,Spring引入了这个Filter,使得Hibernate的Session的生命周期变长。
OpenSessionInViewFilter:org.springframework.orm.hibernate3.support.OpenSessionInViewFilter]是 Spring提供的一个针对Hibernate的一个支持类,其主要意思是在发起一个页面请求时打开Hibernate的Session,一直保持这个 Session,直到这个请求结束,具体是通过一个Filter来实现的。
由于Hibernate引入了Lazy Load特性,使得脱离Hibernate的Session周期的对象如果再想通过getter方法取到其关联对象的值,Hibernate会抛出一个 LazyLoad的Exception。所以为了解决这个问题,Spring引入了这个Filter,使得Hibernate的Session的生命周期 变长。
有两种方式可以配置实现OpenSessionInView,分别是 OpenSessionInViewInterceptor和OpenSessionInViewFilter,功能完全相同,只不过一个在 web.xml配置,另一个在application.xml配置而已。
我们可以在web.xml中配置opensessioninview,代码如下:
1 <!-- 配置Spring自动管理Session. 要配置到struts过滤器之前!--> 2 <filter> 3 <filter-name>hibernateSessionFilter</filter-name> 4 <filter-class> 5 org.springframework.orm.hibernate3.support.OpenSessionInViewFilter 6 </filter-class> 7 </filter> 8 <filter-mapping> 9 <filter-name>hibernateSessionFilter</filter-name> 10 <url-pattern>/*</url-pattern> 11 </filter-mapping>
8、ThreadLocal模式管理session
我们知道Session是由SessionFactory负责创建的,而SessionFactory的实现是线程安全的,多个并发的线程可以同时访问一 个SessionFactory并从中获取Session实例,那么Session是否是线程安全的呢?很遗憾,答案是否定的。
早在Java1.2推出之时,Java平台中就引入了一个新的支持:java.lang.ThreadLocal,给我们在编写多线程程序时提供了 一种新的选择。ThreadLocal是什么呢?其实ThreadLocal并非是一个线程的本地实现版本,它并不是一个Thread,而是thread local variable(线程局部变量)。也许把它命名为ThreadLocalVar更加合适。线程局部变量(ThreadLocal)其实的功用非常简单, 就是为每一个使用某变量的线程都提供一个该变量值的副本,是每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像 每一个线程都完全拥有一个该变量。
ThreadLocal是如何做到为每一个线程维护变量的副本的呢?其实实现的思路很简单,在ThreadLocal类中有一个Map,用于存储每一个线程的变量的副本。
比如下面的示例实现(为了简单,没有考虑集合的泛型):
1 public class ThreadLocal { 2 private Map values = Collections.synchronizedMap(new HashMap()); 3 public Object get() { 4 Thread currentThread = Thread.currentThread(); 5 Object result = values.get(currentThread); 6 if(result == null&&!values.containsKey(currentThread)) { 7 result = initialValue(); 8 values.put(currentThread, result); 9 } 10 return result; 11 } 12 public void set(Object newValue) { 13 values.put(Thread.currentThread(), newValue); 14 } 15 public Object initialValue() { 16 return null; 17 } 18 }
那麽具体如何利用ThreadLocal来管理Session呢?Hibernate官方文档手册的示例之中,提供了一个通过ThreadLocal维护Session的好榜样:
1 public class HibernateUtil { 2 public static final SessionFactory sessionFactory; 3 static { 4 try { 5 sessionFactory = new Configuration().configure().buildSessionFactory(); 6 } catch (Throwable ex) { 7 throw new ExceptionInInitializerError(ex); 8 } 9 } 10 public static final ThreadLocal<Session>session=new ThreadLocal<Session>(); 11 public static Session currentSession() throws HibernateException { 12 Session s = session.get(); 13 if(s == null) { 14 s = sessionFactory.openSession(); 15 session.set(s); 16 } 17 return s; 18 } 19 public static void closeSession() throws HibernateException { 20 Session s = session.get(); 21 if(s != null) { 22 s.close(); 23 } 24 session.set(null); 25 } 26 }