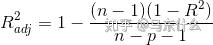目录
- 解释变量与自变量,被解释变量与因变量
- 1、多重共线性的现象
- 2、出现的原因
- 3、判别标准
- 4、检验方法
- 5、多重共线性有什么影响
- 6、多重共线性处理方法
- 7、其他说明
- 8、多重共线性识别-python代码
- 8.1、vif检验
- 8.2 相关系数
- 8.3 聚类
- 9、宏观把握共线性问题
- 9.1、共线性的一般性的影响
- 9.2、共线性对线性回归、逻辑回归的影响
- 10、statsmodel库
- DF Residuals:残差的自由度
- Df Model:模型参数个数(不包含常量参数)
- R-squared:可决系数
- adj-R-squared:修正可决系数
解释变量与自变量,被解释变量与因变量
Y=aX+b
从解释变量和被解释变量看,Y是被X解释的变量。因此,X是解释变量,Y是被解释变量。
从自变量和因变量看,X是自身变量的量,Y是随着X变化而变化的量。因此,X是自变量,Y是因变量。
1、多重共线性的现象
在进行线性回归分析时,容易出现自变量(解释变量)之间彼此相关的现象,我们称这种现象为多重共线性。
适度的多重共线性不成问题,但当出现严重共线性问题时,会导致分析结果不稳定,出现回归系数的符号与实际情况完全相反的情况。
本应该显著的自变量不显著,本不显著的自变量却呈现出显著性,这种情况下就需要消除多重共线性的影响。
2、出现的原因
多重共线性问题就是指一个解释变量的变化引起另一个解释变量的变化。
原本自变量应该是各自独立的,根据回归分析结果能得知:哪些因素对因变量Y有显著影响,哪些没有影响。
如果各个自变量x之间有很强的线性关系,就无法固定其他变量,也就找不到x和y之间真实的关系了。
除此以外,多重共线性的原因还可能包括:
- 数据不足。 (在某些情况下,收集更多数据可以解决共线性问题)
- 错误地使用虚拟变量。(比如,同时将男、女两个虚拟变量都放入模型,此时必定出现共线性,称为完全共线性)
- 自变量都享有共同的时间趋势
- 一个自变量是另一个的滞后,二者往往遵循一个趋势
- 由于数据收集的基础不够宽,某些自变量可能会一起变动
3、判别标准
有多种方法可以检测多重共线性,较常使用的是回归分析中的VIF——方差扩大因子(variance inflation factor)值,VIF值越大,多重共线性越严重。一般认为VIF大于10时(严格是5),代表模型存在严重的共线性问题。
有时候也会以容差值作为标准,容差值=1/VIF,所以容差值大于0.1则说明没有共线性(严格是大于0.2),VIF和容差值有逻辑对应关系,两个指标任选其一即可。
除此之外,
- 直接对自变量进行相关分析,查看相关系数和显著性也是一种判断方法。如果一个自变量和其他自变量之间的相关系数显著,则代表可能存在多重共线性问题。
- 发现系数估计值的符号不对
- 某些重要的解释变量 t 值(SPSS中T的数值对回归参数的显著性检验值)低,而R²不低
- 当一不太重要的解释变量被删除后,回归结果显著变化;
4、检验方法
- 相关性分析,相关系数高于0.8,表明存在多重共线性;但相关系数低,并不能表示不存在多重共线性;(摘抄《计量经济学中级教程》潘省初主编)
- vif检验
- 条件系数检验
5、多重共线性有什么影响
共线性会导致回归参数不稳定,即增加或删除一个样本点或特征,回归系数的估计值会发生很大变化。
这是因为某些解释变量之间存在高度相关的线性关系,XTX会接近于奇异矩阵,即使可以计算出其逆矩阵,逆矩阵对角线上的元素也会很大,这就意味着参数估计的标准误差较大,参数估计值的精度较低,这样,数据中的一个微小的变动都会导致回归系数的估计值发生很大变化。
总结共线性对线性模型影响:
- 回归模型缺乏稳定性。样本的微小扰动都可能带来参数很大的变化;
- 难以区分每个解释变量的单独影响;
- 参数的方差增大;
- 变量的显著性检验失去意义;
- 影响模型的泛化误差。
6、多重共线性处理方法
多重共线性是普遍存在的,通常情况下,如果共线性情况不严重(VIF<5),不需要做特别的处理。如存在严重的多重共线性问题,可以考虑使用以下几种方法处理:
- 手动移除出共线性的变量
先做下相关分析,如果发现某两个自变量X(解释变量)的相关系数值大于0.7,则移除掉一个自变量(解释变量),然后再做回归分析。此方法是最直接的方法,但有的时候我们不希望把某个自变量从模型中剔除,这样就要考虑使用其他方法。 - 逐步回归法
让系统自动进行自变量的选择剔除,使用逐步回归分析将共线性的自变量自动剔除出去。此种解决办法有个问题是,可能算法会剔除掉本不想剔除的自变量,如果有此类情况产生,此时最好是使用岭回归进行分析。 - 增加样本容量
增加样本容量是解释共线性问题的一种办法,但在实际操作中可能并不太适合,原因是样本量的收集需要成本时间等。 - 岭回归
上述第1和第2种解决办法在实际研究中使用较多,但问题在于,如果实际研究中并不想剔除掉某些自变量,某些自变量很重要,不能剔除。此时可能只有岭回归最为适合了。岭回归可以减小参数估计量的方差,是当前解决共线性问题最有效的解释办法。
岭回归是一种改良的最小二乘法,其通过放弃最小二乘法的无偏性,以损失部分信息为代价来寻找效果稍差但回归系数更符合实际情况的模型方程。针对共线性的病态数据,岭回归的耐受性远强于普通线性最小二乘法回归。
其他方法:
-
对模型施加某些约束条件
-
将模型适当变形
-
差分法
时间序列数据、线性模型:将原模型变换为差分模型。 -
主成分分析(PCA)
-
简单相关系数检验法
-
变量聚类、方差膨胀因子vif、相关系数、L1 L2正则化:在特征比较多的时候,先变量聚类,每类中选择单特征比较强的,也可以根据1-r²小的选择有代表性的特征(r²表示的是其他变量能否线性解释的部分,1-r²表示的是容忍度,也就是其他变量不能解释的部分;变量聚类是多选一,因此需要选择一个具有代表性的变量,选择容忍度小的变量;另vif就是容忍度的倒数); 在变量聚类的步骤中也可以结合 方差膨胀因子、相关系数以及业务理解来筛选特征; vif选择多少合适(一般样本集在10w以上VIF>10就有严重的共线性问题了,样本集在10w以下,VIF>5也是严重的共线性问题。在小样本时,一般保证在2以下。当然,这也不能保证一定排除了,最后在检验下模型参数,判断是否仍旧存在共线性)
检验模型参数:
- 看模型系数,和实际业务是否相符合。(注:在进行完证据权重转化后,系数正负,不在具有实际的业务意义。当woe是好客户占比/坏客户占比时,系数都为负,反之系数都为正。(相关原因可以公式推导))
- 模型R^2较高,通过F检验,系数不能通过t检验
7、其他说明
- 多重共线性是普遍存在的,轻微的多重共线性问题可不采取措施,如果VIF值大于10说明共线性很严重,这种情况需要处理,如果VIF值在5以下不需要处理,如果VIF介于5~10之间视情况而定。
- 如果模型仅用于预测,则只要拟合程度好,可不处理多重共线性问题,存在多重共线性的模型用于预测时,
往往不影响预测结果。(这个“往往不影响预测结果”结论小编自己觉得前提条件“拟合程度好”很重要,小编觉得可能还是有些许影响的,有查到一些论文《多重共线性的检验及对预测目标影响程度的定量分析 》)
 3. 解释变量理论上的高度相关与观测值高度相关没有必然关系,有可能两个解释变量理论上高度相关,但观测值未必高度相关,反之亦然。所以多重共线性本质上是数据问题。
3. 解释变量理论上的高度相关与观测值高度相关没有必然关系,有可能两个解释变量理论上高度相关,但观测值未必高度相关,反之亦然。所以多重共线性本质上是数据问题。 - 严重的多重共线性问题,一般可根据经验或通过分析回归结果发现。如影响系数符号,重要的解释变量t值(对回归参数的显著性检验值)很低。要根据不同情况采取必要措施。
8、多重共线性识别-python代码
8.1、vif检验
目前业界检验共线性最常用的方法是VIF检验。VIF越高,多重共线性的影响越严重。
两种方式,一种方式是直接掉包(https://zhuanlan.zhihu.com/p/56793236?utm_source=qq),另一种方式是自己写的函数,两个结果一致。
import pandas as pd
import numpy as np
#数据
df = pd.DataFrame([[15.9,16.4,19,19.1,18.8,20.4,22.7,26.5,28.1,27.6,26.3],[149.3,161.2,171.5,175.5,180.8,190.7,202.1,212.1,226.1,231.9,239],[4.2,4.1,3.1,3.1,1.1,2.2,2.1,5.6,5,5.1,0.7],[108.1,114.8,123.2,126.9,132.1,137.7,146,154.1,162.3,164.3,167.6]]).T
columns = ["var1","var2","var3","var4"]
df.columns=columns#方式1:直接调包
#def_function
def calulate_vif(X):from statsmodels.stats.outliers_influence import variance_inflation_factor#✨✨✨务必注意✨✨✨,一定要加上常数项,#如果没有常数项列,计算结果天差地别,可能VIF等于好几千X[X.shape[1]]=1#vifvif=[]for i in range(X.shape[1]-1):#计算第i+1个变量的(第i+1列)的方差膨胀因子vif.append(variance_inflation_factor(X.values,i))#result_outyy=pd.DataFrame(X.columns[:-1,])yy.rename(columns={0:"var_name"},inplace=True) yy["vif"]=vifprint(yy)#call
calulate_vif(df[["var1","var2","var3","var4"]])#函数2:自定义函数,结果与调包的结果一致
#def_function
def calulate_vif2(x_data):var_name=pd.DataFrame(x_data.columns)var_name.rename(columns={0:"var_name"},inplace=True)vif=[]for i in range(x_data.shape[1]):y=x_data.loc[:,x_data.columns[i]] y.values.reshape(-1,1) x=x_data.drop([x_data.columns[i]],axis=1) x.values.reshape(-1,1)model=linear.fit(x,y)R_2=linear.score(x,y)vif_re=1/(1-R_2)vif.append(vif_re)var_name["vif"]=vifprint(var_name)#call
calulate_vif2(df[["var1","var2","var3","var4"]])
8.2 相关系数
#生成数据集
df = pd.DataFrame([[15.9,16.4,19,19.1,18.8,20.4,22.7,26.5,28.1,27.6,26.3],[149.3,161.2,171.5,175.5,180.8,190.7,202.1,212.1,226.1,231.9,239],[4.2,4.1,3.1,3.1,1.1,2.2,2.1,5.6,5,5.1,0.7],[108.1,114.8,123.2,126.9,132.1,137.7,146,154.1,162.3,164.3,167.6]]).T
columns = ["var1","var2","var3","var4"]
df.columns=columnsdef calulate_cor(cor_data):# calculate pearson corcoefficient1 =cor_data.corr(method = 'pearson')print(coefficient1)# Plotplt.figure(figsize=(12,10), dpi= 80)sns.heatmap(cor_data.corr(), xticklabels=cor_data.corr().columns, yticklabels=cor_data.corr().columns, cmap='RdYlGn', center=0, annot=True)# Decorationsplt.title('Correlogram of mtcars', fontsize=22)plt.xticks(fontsize=12)plt.yticks(fontsize=12)plt.show()calulate_cor(df[["var1","var2","var3","var4"]])
输出结果为: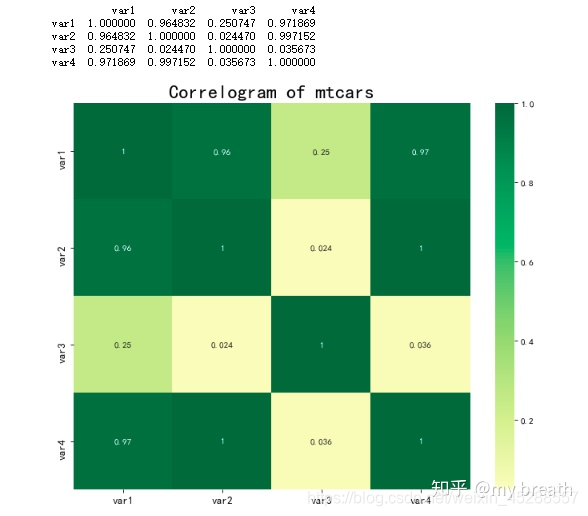
8.3 聚类
可能不是很好用
#生成数据集
df = pd.DataFrame([[15.9,16.4,19,19.1,18.8,20.4,22.7,26.5,28.1,27.6,26.3],[149.3,161.2,171.5,175.5,180.8,190.7,202.1,212.1,226.1,231.9,239],[4.2,4.1,3.1,3.1,1.1,2.2,2.1,5.6,5,5.1,0.7],[108.1,114.8,123.2,126.9,132.1,137.7,146,154.1,162.3,164.3,167.6]]).T
columns = ["var1","var2","var3","var4"]
df.columns=columns#方式一:
def var_cluster(clusterNum,cluster_data):from scipy.cluster.vq import vq,kmeans,whitentransed=whiten(np.array(cluster_data.T)) #归一化transed#clustermodel = kmeans(transed,clusterNum)#cluster_resultresult = vq(transed,model[0])[0]result#result_outaa=pd.DataFrame(cluster_data.columns)aa.rename(columns={0:"var_name"},inplace=True) bb=pd.DataFrame(result)bb.rename(columns={0:"cluster"},inplace=True)var_cluster=pd.concat([aa,bb],axis=1)var_cluster.sort_values(by=["cluster"],ascending=(True),inplace=True)print(var_cluster)#call
var_cluster(2,df[["var1","var2","var3","var4"]])#方式二:
def var_cluster2(clusterNum,cluster_data):import numpy as npfrom sklearn.cluster import KMeans#arraytransed=np.array(cluster_data.T)#model_fitkmeans=KMeans(n_clusters=clusterNum).fit(transed)pred=kmeans.predict(transed)print(pred)#result_outaa=pd.DataFrame(cluster_data.columns)aa.rename(columns={0:"var_name"},inplace=True) bb=pd.DataFrame(pred)bb.rename(columns={0:"cluster"},inplace=True)var_cluster=pd.concat([aa,bb],axis=1)var_cluster.sort_values(by=["cluster"],ascending=(True),inplace=True)print(var_cluster)#call
var_cluster2(2,df[["var1","var2","var3","var4"]])
参考:
- https://zhuanlan.zhihu.com/p/72722146
- https://zhuanlan.zhihu.com/p/96793075
- https://zhuanlan.zhihu.com/p/146298015
9、宏观把握共线性问题
参考:https://zhuanlan.zhihu.com/p/88025370
9.1、共线性的一般性的影响
太多相关度很高的特征并没有提供太多的信息量,并没有提高数据可以达到的上限,相反,数据集拥有更多的特征意味着更容易收到噪声的影响,更容易收到特征偏移的影响等等。
简单举个例子:
N个特征全都不受到到内在或者外在因素干扰的概率为k,则2N个特征全部不受到内在或外在因素干扰的概率必然远小于k。这个问题实际上对于各类算法都存在着一定的不良影响。
9.2、共线性对线性回归、逻辑回归的影响
逻辑回归的梯度更新公式用代码表示为:
weights = weights - alpha * dataMatrix.transpose()* error
其中alpha为学习率,dataMatrix.transpose()为原始数据的矩阵,error=y_pred-y_true。
从这里可以看出,共线性问题对于逻辑回归损失函数的最优化没影响,参数都是一样更新,一样更新到收敛为止。所以对于预测来说没什么影响。
那共线性会引发的问题:
- 模型参数估计不准确,有时甚至会出现回归系数的符号与实际情况完全相反的情况,比如逻辑上应该系数为正的特征系数 算出来为负;
- 本应该显著的自变量不显著,本不显著的自变量却呈现出显著性(也就是说,无法从p-值的大小判断出变量是否显著——下面会给一个例子);
- 多重共线性使参数估计值的方差增大,模型参数不稳定,也就是每次训练得到的权重系数差异都比较大。
其实多重共线性这样理解会简单很多:
> 假设原始的线性回归公式为:y=w1*x1+w2*x2+w3*x3
> 训练完毕的线性回归公式为:y=5x1+7x2+10x3
> 此时加入一个新特征x4,假设x4和x3高度相关,x4=2x3,则:
> y=w1*x1+w2*x2+w3*x3+w4*x4=w1*x1+w2*x2+(w3+2w4)*x3
> 因为我们之前拟合出来的最优的回归方程为:y=5x1+7x2+10x3
> 显然w3+2w4可以合并成一个新的权重稀疏 w5,则:y=w1*x1+w2*x2+w5*x3
> 显然:y=w1*x1+w2*x2+w3*x3和y=w1*x1+w2*x2+w5*x3是等价的。
> 那么最终最优的模型应该也是 y=5x1+7x2+10x3
> 但是考虑到引入了x4,所以w4和w3的权重是分开计算出来的,这就导致了w5=10=w3+2w4,
> 显然这个方程有无穷多的解,比如w3=4,w4=3,或者w4=-1,w3=12等,
> 因此导致了模型系数估计的不稳定并且可能会出现负系数的问题。
10、statsmodel库
statsmodels(http://www.statsmodels.org)是一个Python库,用于拟合多种统计模型,执行统计测试以及数据探索和可视化。statsmodels包含更多的“经典”频率学派统计方法。
总结:https://blog.csdn.net/zm147451753/article/details/83107535
statsmodel的检验项目比较全面,实际上逻辑回归与线性回归比我们想象的要复杂。
DF Residuals:残差的自由度
等于 观测数也就是样本数(No. Observations)-参数数目(Df Model+1(常量参数,权重加上偏置的数量))
Df Model:模型参数个数(不包含常量参数)
R-squared:可决系数
R 2 = 1 − ∑ i ( y ^ i − y i ) 2 ∑ i ( y ^ i − y ˉ i ) 2 R^{2}=1-\frac{\sum_{i}\left(\hat{y}_{i}-y_{i}\right)^{2}}{\sum_{i}\left(\hat{y}_{i}-\bar y_{i}\right)^{2}} R2=1−∑i(y^i−yˉi)2∑i(y^i−yi)2
上面分子就是我们训练出的模型预测的所有误差。
下面分母就是不管什么我们猜的结果就是y的平均数。(瞎猜的误差)
adj-R-squared:修正可决系数
R a d j 2 = 1 − ( n − 1 ) ( 1 − R 2 ) n − p − 1 R_{a d j}^{2}=1-\frac{(n-1)\left(1-R^{2}\right)}{n-p-1} Radj2=1−n−p−1(n−1)(1−R2)
右边式子的R就是原始的R-sqaure,n是样本数量,p是特征的数量。