目录
前言:
一.字符串函数
1.strlen——求字符串长度
strlen
2.长度不受限制的字符串函数
a.strcpy——字符串拷贝
strcpy
b.strcat——追加字符串
strcat
c.strcmp——字符串比较
strcmp
3.长度受限制的字符串函数——strncpy,strncat,strncmp
为什么会出现这些函数呢?
strncpy函数:
strncpy
strncat函数
strncat
strncmp函数:
strncmp
4.字符串查找
a.strstr——判断是否为子字符串
strstr
b.strtok——一个奇怪的函数
strtok
c.strerror——错误信息查找
strerror
perror
上面是字符串相关的函数,下面是一些字符分类的函数:
编辑 字符转换函数:
二.内存函数
1.内存拷贝函数
a.memcpy
b.memmove
2.内存填充函数——memset
3.内存比较函数——memcmp
总结:
博客主页:张栩睿的博客主页
欢迎关注:点赞+收藏+留言
系列专栏:c语言学习
家人们写博客真的很花时间的,你们的点赞和关注对我真的很重要,希望各位路过的朋友们能多多点赞并关注我,我会随时互关的,欢迎你们的私信提问,也期待你们的转发!
希望大家关注我,你们将会看到更多精彩的内容!!!
前言:
C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有字符串类型的,字符串通常放在 常量字符串 中或者 字符数组中。 字符串常量 适用于那些对它不做修改的字符串函数。
以下的函数都需要引用头文件<string.h>
一.字符串函数
1.strlen——求字符串长度
strlen
函数原型:
![]()
函数作用:
- 字符串以
'\0'作为结束标志,strlen函数返回值是在字符串中'\0'前面出现的字符个数(不包含'\0') - 参数是一个字符指针变量
- 参数指向的字符串必须要以
'\0'结束,否则计算出的长度是随机值 - 注意函数的返回值为
size_t,是无符号的
函数注意事项:
因为返回值是size_t,所以就要避免出现下图这样的代码:strlen(“abc”)算出的结果是3, strlen("abcde")算出的结果是5,可能想着3-5得到-2,实际上并不是这样的,这里算出的3和5都是无符号整型,算出的-2也是一个无符号整型,-2在内存中以补码的形式存储,从无符号整型的视角看去,这串补码就表示一个很大的正数。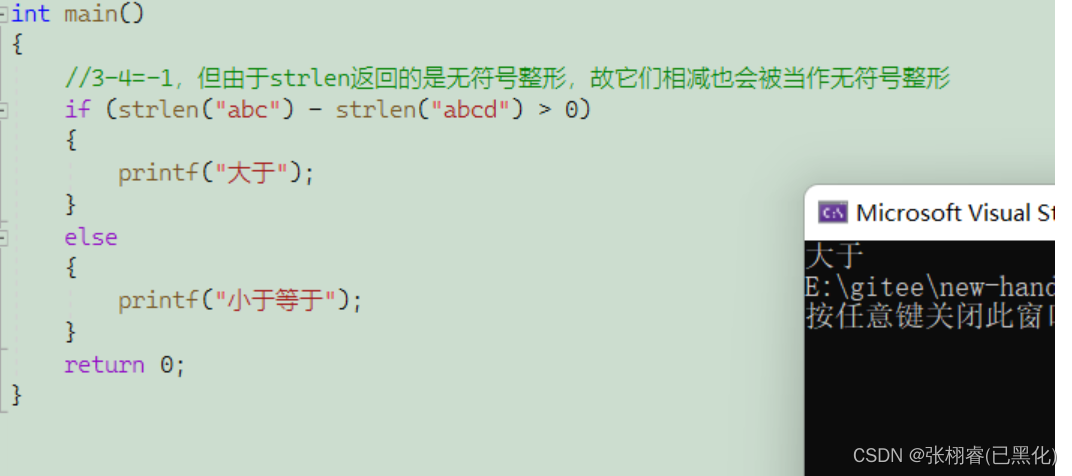
3种模拟的方法:
递归:
递归
int my_strlen1(const char* str)
{assert(str != NULL);if (*str != '\0')return 1 + my_strlen(str + 1);elsereturn 0;
}指针-指针
指针-指针
int my_strlen2(const char* str)
{const char* start = str;assert(str != NULL);while (*str){str++;}return str - start;递推
int my_strlen(const char* str)
{assert(str != NULL);int count = 0;while (*str != '\0'){count++;str++;}return count;
}2.长度不受限制的字符串函数
a.strcpy——字符串拷贝
strcpy
函数原型:

函数作用:
字符串拷贝函数,把源字符串拷贝到目标空间
注意事项:
函数有两个参数,source指向待拷贝的字符串,也叫做源字符串。destination是目标空间的地址
源字符串必须以’\0’结束
目标空间必须足够大,以确保能存放源字符串,否则会出现非法访问
特殊情况:
会把源字符串中的 ‘\0’ 也拷贝到目标空间

目标空间必须可变,例如把源字符串拷贝到一个字符串常量里面是不可取的

模拟实现:
char* my_strcpy(char* destination, const char* source)
{assert(destination && source);char* ret = destination;while (*destination++ = *source++){;}return ret;
}b.strcat——追加字符串
strcat
函数原型:

函数作用:
字符串追加函数,将源字符串追加到目标字符串后面,目标中的终止字符’\0’会被源字符串的第一个字符覆盖

注意事项:
函数有两个参数,其中source指向要追加的字符串,也叫做源字符串,destination是目标空间的地址
目标空间中必须要有'\0',作为追加的起始地址
源字符串中也必须要有'\0'作为追加的结束标志
目标空间必须足够大,能容纳下源字符串的内容
目标空间必须可修改
以上与strcpy类似,但是有一点很特殊:
自己给自己追加会陷入死循环!
同学们先看看模拟实现的代码可以知道,该函数本质是将\0覆盖了,再最后追加\0,但是自己改自己会把\0覆盖不见,最后造成死循环。
模拟实现:
char* my_strcat(char* destination, const char* source)
{assert(destination && source);char* ret = destination;while (*destination){ret++;}while (*destination++ = *source++){;}return ret;
}c.strcmp——字符串比较
strcmp
函数原型:
![]()
函数作用:
根据相同位置的ASCII值进行大小的比较。并不是比字符串长度
注意事项:
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字
该函数是按字典序来比较的。

模拟实现:
int my_strcmp(const char* str1, const char* str2)
{assert(str1 && str2);while (*str1 == *str2)//如果相等就进去,两个指针加加,但是可能会出现两个字符串相等的情况,两个指针都指向'\0',此时比较就结束了{if (*str1 == '\0'){return 0;}str1++;str2++;}if (*str1 > *str2){return 1;}else{return -1;}
}3.长度受限制的字符串函数——strncpy,strncat,strncmp
为什么会出现这些函数呢?
前面三个函数压根不关心到底拷贝,追加,比较了几个字符。它们只关心是否找到了\0,一旦找到了\0就会停止。这样的话如果目标空间不够大,会造成越界。这些特点就会让人们决定它是不安全的,并且我们之前发现如果自己给自己追加会出现死循环的现象,因为这些缺点,下面介绍较安全的函数。
strncpy函数:
strncpy
函数原型:
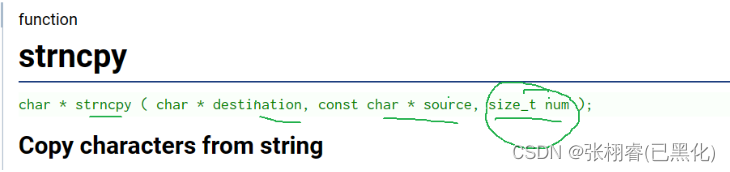
函数作用:
长度受限的字符串拷贝
注意事项:
- 拷贝num个字符从源字符串到目标空间。
- 如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
模拟实现:
char* my_strncpy(char* dest, const char* src, int num)
{assert(dest && src);char* ret = dest;while (num){if (*src == '\0')//此时说明src指针已经指向了待拷贝字符串的结束标志'\0'处,src指针就不用再++了{*dest = '\0';dest++;}else{*dest = *src;dest++;src++;}num--;}return ret;
}strncat函数
strncat
函数原型:

注意事项:
- 从源字符串的第一个字符开始往后数num个字符追加到目标空间的后面,外加一个终止字符。
- 如果源字符串的长度小于 num,则仅复制终止字符之前的内容。
模拟实现:
char* my_strncat(char* dest, const char* src, int sz)
{assert(dest && src);char* ret = dest;//找目标空间的\0while (*dest != '\0'){dest++;}//追加while (sz){*dest++ = *src++;sz--;}*dest = '\0';return ret;
}
strncmp函数:
strncmp
函数原型:

模拟实现:
int my_strncmp(const char* str1, const char* str2, int sz)
{assert(str1 && str2);while (sz){if (*str1 < *str2){return -1;}else if (*str1 > *str2){return 1;}else if(*str1 == '\0'||*str2 =='\0')//当有一个为'\0',说明比较就可以结束了{if (*str1 == '\0' && *str2 == '\0')//如果二者都是'\0',说明两个字符串相等{return 0;}else if(*str1 =='\0')//如果str1为'\0',说明str1小,str2大{return -1;}else//如果src为'\0',说明str1大,str2小{return 1;}}sz--;str1++;str2++;}
}
4.字符串查找
a.strstr——判断是否为子字符串
strstr
函数原型:

函数作用:
判断是否为子字符串

注意事项:
- 在str1指向的字符串中查找str2指向的字符串
- 返回一个指向str1中第一次出现的str2的指针
- 如果 str2 不是 str1 的一部分,则返回一个空指针NULL
- 匹配过程不包括终止空字符,但它到此为止
BF算法(暴力枚举)模拟函数实现:
char* my_strstr(const char* str1, const char* str2)
{assert(str1 && str2);if (*str2 == '\0'){return (char*)str1;}const char* s1 = NULL;const char* s2 = NULL;const char* cp = str1;while (*cp){s1 = cp;s2 = str2;while (*s1 !='\0' && *s2!='\0' && *s1 == *s2){s1++;s2++;}if (*s2 == '\0'){return (char*)cp;}cp++;}return NULL;
}KMP算法模拟实现:
void Getnext(char* next, char* str2)
{next[0] = -1;next[1] = 0;int k = 0;int i = 2;while (i <= strlen(str2)){if (str2[k] == str2[i-1])next[i] = k + 1;else if (str2[i] != str2[0])next[k] = 0;else if (str2[i] == str2[0])next[k] = 1;k++;i++;}
}
char* KMP(const char* str1, const char* str2)
{assert(str1 && str2);int* next = (int*)malloc(sizeof(int) * strlen(str2));assert(next);Getnext(next, str2);int i = 0;int j = 0;while (i < strlen(str1) && j < strlen(str2)){if (j==-1||str1[i] == str2[j]){i++;j++;}else{j = next[j];}}free(next);if (i == strlen(str2))return &str1[i - j];return NULL;
}关于KMP算法可以通过这两篇博客来了解:
一篇文章弄懂KMP算法
关于next数组
b.strtok——一个奇怪的函数
strtok
函数原型:

作用:
通过分隔符分割字符串
注意事项:
1.sep参数是个字符串,定义了用作分隔符的字符集合第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标记。
2.strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容并且可修改。)
3. strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串中的位置。
4.strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标记。
5.如果字符串中不存在更多的标记,则返回 NULL 指针。
这个函数很奇怪,让我举个栗子:
用来分割字符串。一个例子,例如我的邮箱是xxxxx@163.com。这个邮箱起始由三部分组成,一个是xxxxxx,一个是163,一个是com。我现在想把这三部分分开。


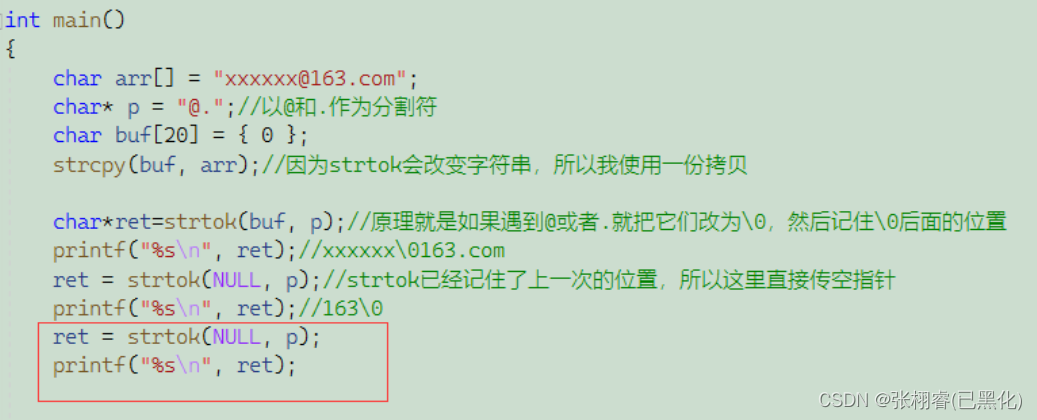

当然,我们可以用for循环简写:
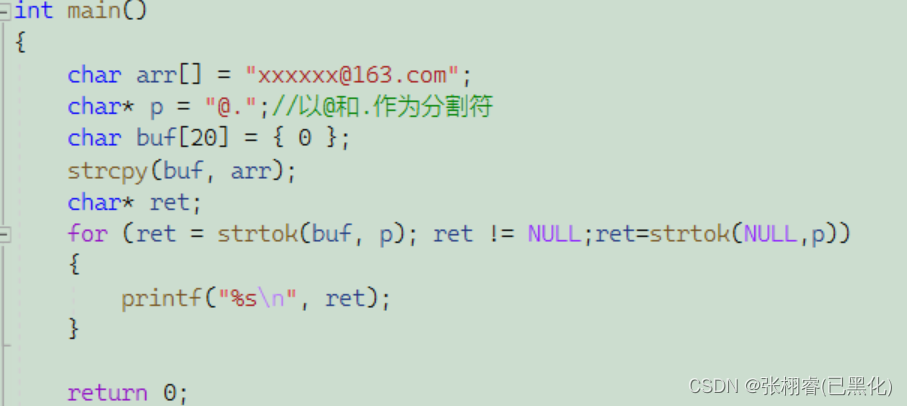
该函数模拟较复杂,我们就先不模拟了。
c.strerror——错误信息查找
strerror
函数原型:

作用:
把错误码转换成错误信息
注意事项:
- C语言的库函数在运行的时候,如果发生错误,就会把错误码存在一个变量中,这个变量是:errno
- 返回的指针指向静态分配的字符串(错误信息字符串)
一些栗子:

用法:
int main()
{//打开文件FILE* pf = fopen("test.c", "r");if (pf == NULL){printf("%s\n", strerror(errno));//需要包含头文件#include<errno.h>return 1;}//读文件//关闭文件fclose(pf);return 0;
}
//打开失败时屏幕显示:
No such file or directory
关于这里的errno,C语言的库函数在运行的时候,如果发生错误,就会将错误码存在一个变量中,这个变量是:errno,错误码是一些数字:1 2 3 4 5,我们需要讲错误码翻译成错误消息。
perror函数:
perror
实际上就是printf和strerror的结合!

上面是字符串相关的函数,下面是一些字符分类的函数:
 字符转换函数:
字符转换函数:
tolower:将大写字母转换为小写字母
int tolower ( int c );
toupper:将小写字母转换成大写字母
int toupper ( int c );
这些函数我就不一一讲解了,家人们有兴趣的话可以去官网了解一下哦!
二.内存函数
上面我们介绍了处理字符串的函数,但是对于其他类型,我们该如何处理呢?通过下面的内存函数的介绍,相信你会有所感悟!
1.内存拷贝函数
a.memcpy
函数原型:

注意事项:
这里的destination指向要在其中赋值内容的目标数组,source指向要复制的数据源,num是要复制的字节数,注意这里前两个指针的的类型还有函数返回值都是void*,这是因为,memcpy这个函数是内存拷贝函数,它有可能拷贝整型,浮点型,结构体等等各种类型的数据……虽然返回类型是void*,但他也是必不可少的,void*也表示一个地址,用户可以把它强制转换成自己需要的类型去使用。

 函数的模拟实现:
函数的模拟实现:
void* my_memcpy(void* dest, const void* src, size_t num)
{void* ret = dest;assert(dest && src);//前->后while (num--){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;}return ret;
}注意:这里对于(char*)dest不能++或--,因为虽然强制转化类型,但是他的类型实质是没有改变的。
然而,这个函数存在缺陷,就是当对于自己拷贝并且有重叠部分时,会出现bug
如果我们只在一个字符串里操作就会出现问题。例如我想把arr1里的1,2,3,4,5拷贝到3,4,5,6,7上就,理论上arr1[]应该变为1,2,1,2,3,4,5,8,9。
但是实际上:

为了修改这个bug,大佬们又写出了memmove函数!
b.memmove
函数原型和memcpy一样,作用也是一样的,不同的就是可以拷贝自己,并且重叠不会出bug!
为什么之前的模拟实现会出现这个bug呢?

原因是:当1拷贝到3上时,原来的3已经被1替换,当2拷贝到4上的时候,原来的4已将被2替换。所以当拷贝arr[2]到arr[4]上的时候,原本arr[2]里面存放的3已将被1替换了,同理,所以才得出了不符合我们预期的结果。那如何解决这个问题呢?先来分析这个问题产生的原因,这是因为源空间与目标空间之间有重叠,这里的arr[2]、arr[3]、arr[4]既是源空间也是目标空间,当拷贝1和2的时候把源空间中开没有拷贝的3和4就给覆盖了,此时源空间arr[2]和arr[3]里面存的就不再是3和4了,而是1和2,所以此时拷贝arr[2]和arr[3]里面的数据,其实拷贝的就是1和2。为了解决这个问题,我们可以从后往前拷贝,此时就不会出现这样的问题
但是,我们从后往前拷贝就可以解决这个问题吗?答案是当然不是,比如:

所以我们需要分类讨论:
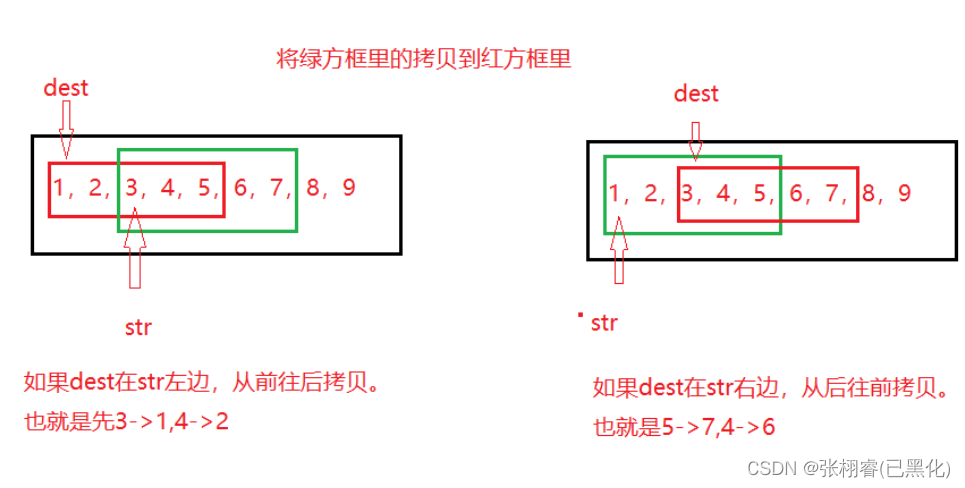 模拟实现:
模拟实现:
void* my_memmove(void* dest, const void*src, size_t num)
{void* ret = dest;assert(dest && src);if (dest < src){//前-->后while (num--){*(char*)dest = *(char*)src;dest = (char*)dest + 1;src = (char*)src + 1;}}else{//后->前while (num--){*((char*)dest+num) = *((char*)src + num);}}return ret;
}2.内存填充函数——memset
 函数作用:
函数作用:
内存设置
注意事项:
- 以字节为单位来设置内存中的数据,把从ptr开始往后的num个字节设置成value
- 形参value也可以是字符,字符其实也是整型,因为字符在内存中存的是其ASCII
- value如果是整数的话,需要注意它的取值范围,因为一个字节最大可以存储255,超过255就会发生截断
- 由于这个函数是一个字节一个字节的改变,所以有些初始化是不成立的,比如对于整形数组初始化为1是不可能实现的,因为每个字节都变成01,一个整形事实上是一个很大的数字。所以对于整形数组初始化,一般都是初始化为0或-1.当然对于字符,不必担心,他本身也是一个字符一个字符改变的!

3.内存比较函数——memcmp
函数原型:

注意事项:
- 比较从ptr1和ptr2指针开始的num个字节
- 两个内存块中不匹配的第一个字节在 ptr1 中的值低于 ptr2 中的值返回一个小于零的数子,相等返回零,两个内存块中不匹配的第一个字节在 ptr1 中的值大于在 ptr2 中的值返回一个大于零的数子
总结:
本文通过函数使用的介绍来初步学习,函数的模拟实现来深刻理解了库函数的使用。辛苦各位小伙伴们动动小手,三连走一波 最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!












![[Vue warn]: Failed to resolve directive: modle (found in ComponentA)](https://img-blog.csdnimg.cn/20191017160234828.png)

![Vue:解决[Vue warn]: Failed to resolve directive: modle (found in Anonymous)](https://img-blog.csdn.net/20180730152335479?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyMjI5MjUz/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)